课程名称:课程版本(101/201/301)+ Tidb发展简史
学习时长:10 mins
课程收获:
我们处在一个最好的时代,有ZY高层的政策支持,未来10年国产数据库将得到空前的发展。 DB领域有位大神说:分布式数据库一定是未来,HTAP 是最好的方向,云原生是最好的舞台,然而这些优点 TiDB 全都有。
接下来让我们从tidb的架构上读懂这些优点:

受Google Spanner启发而开发的Tidb Database可以做到
- 存储节点、计算节点的无限扩展(且做到存储节点和计算节点的分开扩展)、弹性伸缩。
- 兼容mysql的语法和协议。
- 对应用透明的分片策略,做到对应用的无感知。
- 强一致的分布式事务。
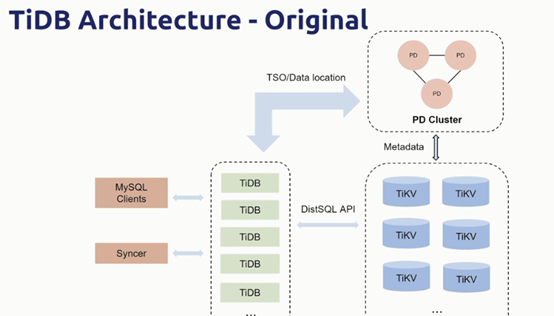
Tidb是无状态的SQL引擎,负责计算任务,可以多实例启动
Tikv是分布式存储引擎,使用raft算法来进行副本之间的复制(数据同步),保障高可用
PD 负责元数据的请求及tikv 中数据的调度(分配TSO号、数据位置路由等)
Tidb具备无限横向扩展能力。
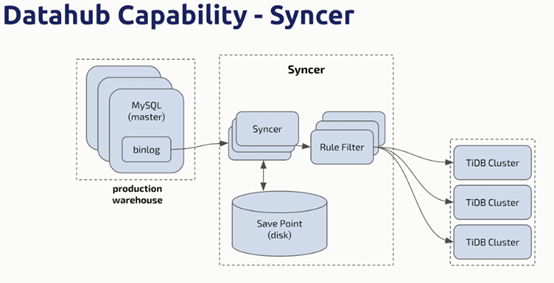
Tidb也具备非常好的中台能力,在中台场景中通过工具syncer可以将外部数据向Tidb cluster进行汇总。

Tidb可以非常方便的从各类mysql DB中同步数据(协议兼容mysql)
不需要分片,对应用透明
数据的汇总是实时的,可以将后台和中台合二为一
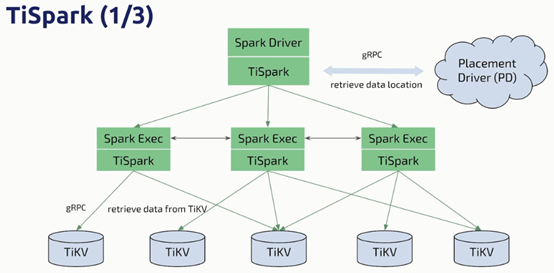
引入tispark 分布式计算框架,平滑接入大数据生态,将单点计算能力扩展为多点的并行计算

Tispark 分布式计算框架有点:更快、更稳定;脚本、python、R语言、Apache Zeppelin等都可以轻松直接的操作Tidb cluster

Tispark缺点有二:
- 并发度低
- 消耗大量的计算资源
VS tidb进行OLAP时
使用Tidb更适合在高并发的同时进行中等规模的查询,对于复杂计算消耗的资源更少,维护简单、方便

在引入spark的同时优化器从Basic optimizer 到RBO+CBO到未来要支持的Cascades optimizer
执行器从火山模型到批量执行再到向量化执行,更好地并发控制

在数据分析中列存VS行存会消耗更小的I/O资源

通过raft learner 向tiflash同步数据;读取时通过raft index和MVCC实现了强一致性读。
通过打标签方式实现了物理隔离,使OLAP 和 OLTP的业务不会相互影响
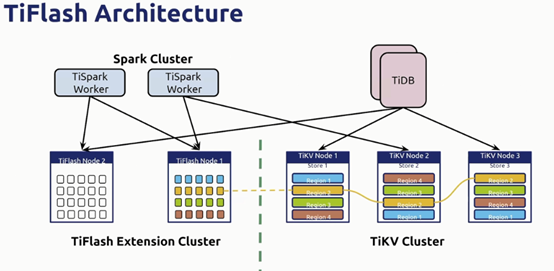
Tiflash可以接收来自tidb和tispark的读请求,写请求通过raft learner方式同步实现
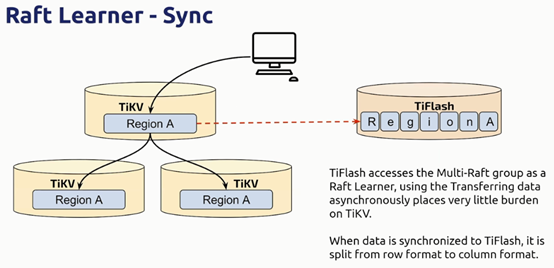
从tikv中通过Raft Learner同步到Tiflash中的数据最终会以列存的方式保存下来
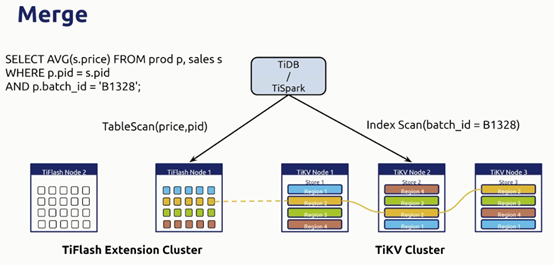
当一条sql进来,tidb会通过智能算法将不同的请求发送到不同的存储引擎中(tikv进行索引扫描;tiflash进行某列或几列的扫描)

Tidb中既有行存也有列存(是真正意义上的HTAP数据库),能自动的进行 行/列转换(不需要 ETL工具进行数据转换)。在系统运行 OLTP 业务时,也可以方便的进行报表OLAP查询。
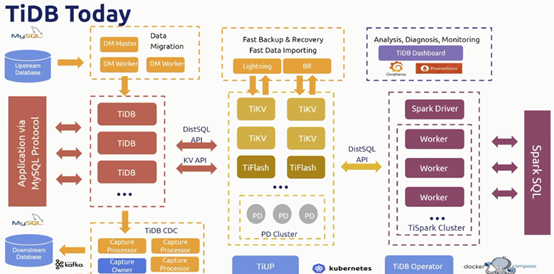
Tidb整体生态
- DM: 上游数据同步工具
- Ticdc:将数据同步到下游的工具
- Lightning :数据全量导入工具
- BR:数据全量/增量数据备份/恢复工具
- dashboard+prometheus:数据实时采集监控工具
- tiup: 快速部署工具
- Operator: 云端部署工具(例如现在最流行的K8s端部署)

Follower Read 功能是指在强一致性读的前提下使用 Region 的 follower 副本来承载数据读取的任务,从而提升 TiDB 集群的吞吐能力并降低 leader 负载。Follower Read 包含一系列将 TiKV 读取负载从 Region 的 leader 副本上 offload 到 follower 副本的负载均衡机制。TiKV 的 Follower Read 可以保证数据读取的一致性,可以为用户提供强一致的数据读取能力。
Follower Read是分布式DB领域一项重大的技术突破,领先于国内市场同类产品,属硬实力。
欢迎关注我的公众号,大家一起探讨、交流,一起玩转Tidb
