课程名称:课程版本(101/201/301)+ 3.7.5 Partition Table(TiDB 的分表
学习时长:
10min
课程收获:
如何使用分区表
课程内容:
一、Partition Table introduction
- 分区表
- 通过一些规则将一张表拆成多个表
- 被拆分出来的每张表称为一个分区
- 分区直接相互独立的,对上层应用使用是透明的
- 在查询和写入时会按照相应规则路由到相应的分区
- 对于TiDB来说分区表就是一个独立的物理表(拥有Table ID),既可以透明的使用整个分区,也可以单独操作某几个分区
- TiDB支持的分区表类型
- range
- 通过分区表达式的范围进行分区
- 分区的表达式可以是单个的列名也可以是几个列组成的分区函数
- 划分的range类似于0到10、10到20这种连续不相交的区间
- range分区表只能划分整数范围,所以分区的表达式结果必须是一个整数或者使用一个整数的列作为一个表达式
- 分区表达式包含的列必须都包含在所有唯一索引中
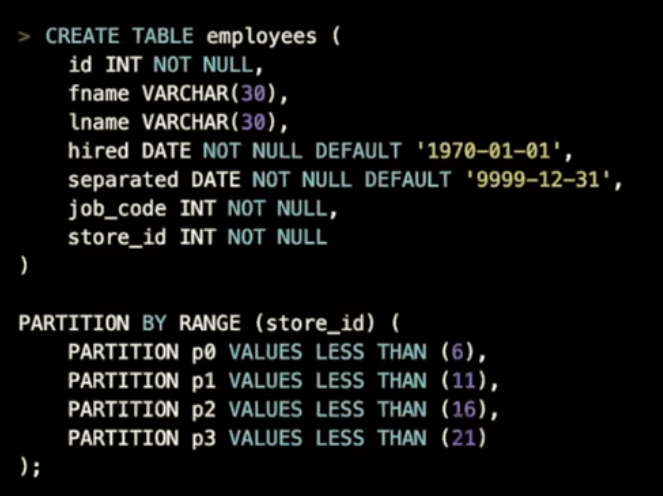
- 上面示例中当写入数据的store_id小于6时,数据会被划分到p0分区
- 上面示例中分区表只支持store_id到21的数据,如果大于21时写入时会报错
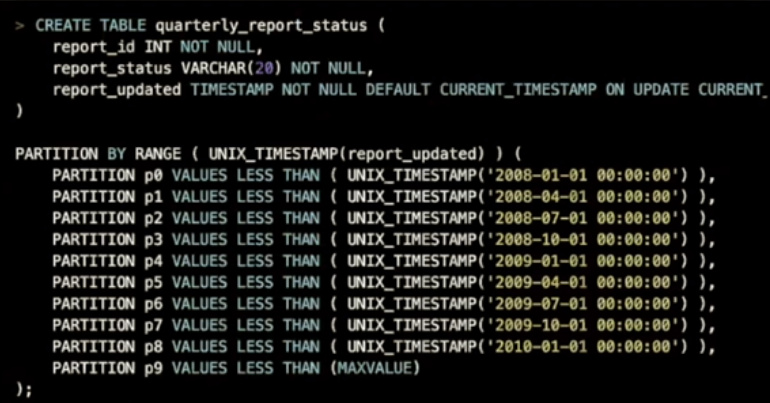
- 上面示例中最后一个分区使用MAXVALUE来表示整数范围的最大值
- 上面示例中分区表达式使用了函数,数据带有时间字段时使用这种方式创建分区表
- 使用range分区表注意事项
*业务中需要大量删除数据,直接使用Delete可能会带来性能问题,使用某些规则创建分区表可以直接删除分区
*数据是按照时间来分布需要保留一些历史数据,做一些按时间范围查询
*可以解决小表读热点问题,通过把一个小表拆分成多个分区把热点打散 - range columns
- 在使用和创建上与range分区表没有太大区别
- TiDB range columns只支持单个列作为range表达式
- 分区划分值不但支持整数,还可以是字符串、时间类型
- hash
- hash分区表是根据表达式的值,根据数量取模来划分分区的分区表
- 优势体现在单点查询或更新时,会直接路由到指定的hash分区比range要快,但是范围查询时性能较差
- 分区表达式包含的列必须都包含在所有唯一索引中
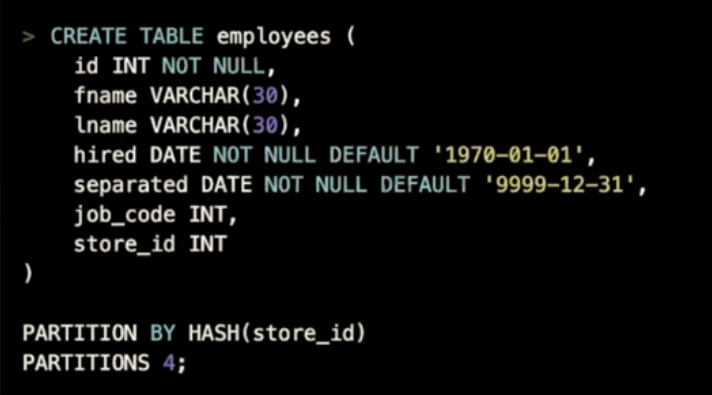
- 上面示例中通过store_id作为一个表达式创建了一个包含4个分区的hash分区表
- 上面示例中当store_id=10时,store_id对4取模得到了2,这条数据将存储至第二个分区
- 上面示例中当store_id=7时,store_id对4取模得到了3,这条数据将存储至第三个分区
- 上面示例中当此列为NULL value时默认存储在第零个分区
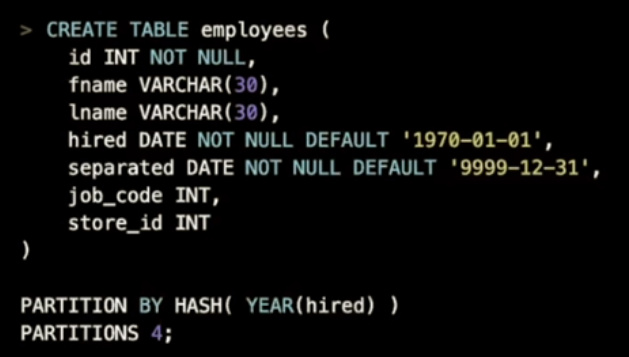
- 需要注意hash分区表支持函数表达式作为分区时,这个表达式结果必须是一个整数
- 适用于hash分区表的场景
*比如账户表,用户信息过于庞大,没有明显分区的特征字段,可以根据分区表中的int类型的row_id字段作为hash分区的表达式,结合分区时配置的分区数量,可以把row_id打散到不同分区
*根据时间类型来分布的字段,可以用年或者月这样的时间来进行分区,这样每次分区可以指定在某个分区中
*可以解决小表读热点问题,通过hash分区表把热点打散
二、Effective Partition
- Uderstanding Partition pruning
- 分区表对于使用者是透明的可以像普通表一样使用,分区裁剪是根据优化器来选择不同的分区
- 熟悉分区裁剪后可以写出性能更好的分区表的查询语句
- Range Partition pruning
- 在分区裁剪阶段,优化器会根据条件中包含的分区列的范围推导出分区的范围
- 示例
- 列的值是7,这样优化器很容易确定去找列的范围是7的有哪些分区
- 通过明显的指的定列范围,直接去找包含指定范围的分区
- 分区合并例子如,通过or语句前半部分是5至7,后半部分为11至13,这样优化器也可以推断出查哪些分区
- 如果列的值进行了一个算式运算,优化无法判断,将导致全表扫描
- 如果使用了函数的分区表达式,TiDB只支持单调函数,包括’unix_timestamp’和’to_days’,除此之外,建议使用单个列作为表达式
- Hash Partition Pruning
- 优化器会尝试获取分区表表达式列的值,来根据列的值推断整个分区表表达式的值
- 示例
- 使用单个列作为分区表表达式,如果此列的值是7,那么优化器很容易判断出整个分区表表达式的值是7,根据取模规则路由到制定分区
- 使用单个列作为分区表表达式,指定了一个范围,那么会导致优化器分区裁剪因为hash分区表不能很好地处理范围查询导致失效
- 使用函数操作示例
- a=5,b=6,对于分区表达式a+b优化器可以直接确定这个值是11
- a=6,没告诉b的值时,对于a+b的值是模糊的,优化器无法做出有效的分区裁剪
- 使用year(a)+b作为分区表达式,当查询条件中year(a)=7,b=5时,因优化器未能获取a的值,所以无法得到year(a)函数的值,最终导致分区裁剪失效
- Partition Pruning
- 由于分区裁剪过程在TiDB4.0中是发生在逻辑优化阶段,所以一些运行时才会得到结果的条件并不能作为分区裁剪的条件
- 运行时得到结果的条件示例:select * from t2 where x<(select * from t1 where t2.x <t1.x and t2.x<2);
- 目前在index join情况也不能进行分区裁剪,在TiDB 5.0时将会支持
学习过程中遇到的问题或延伸思考:
- 问题 1:
- 问题 2:
- 延伸思考 1:
- 延伸思考 2: