课程名称:TiKV Server 优化
学习时长:30
课程收获:
课程内容:
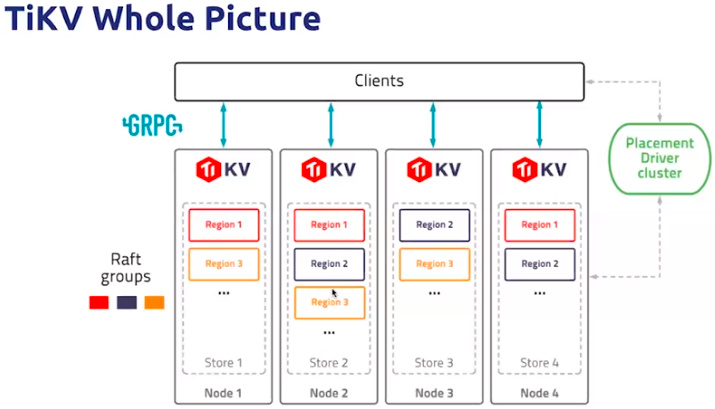
1. TiKV 的架构
- 架构
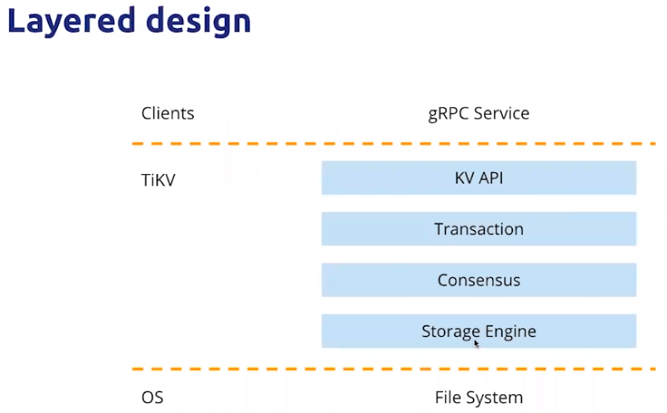
- TiKV 分层设计
- TiKV module

2. TiKV 的读写流程分析及优化
2.1 写请求处理
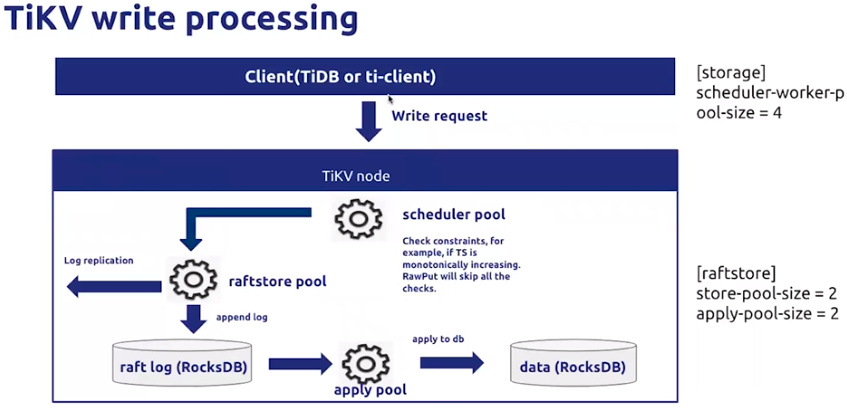
scheduler pool > raftstore pool > apply pool

scheduler pool 达到80%以上建议扩容。
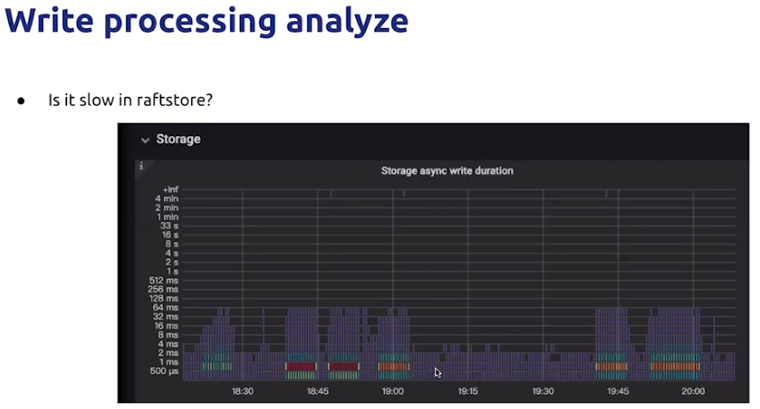
上图 :确认 raftstore pool 是否存储延迟、慢的情况。
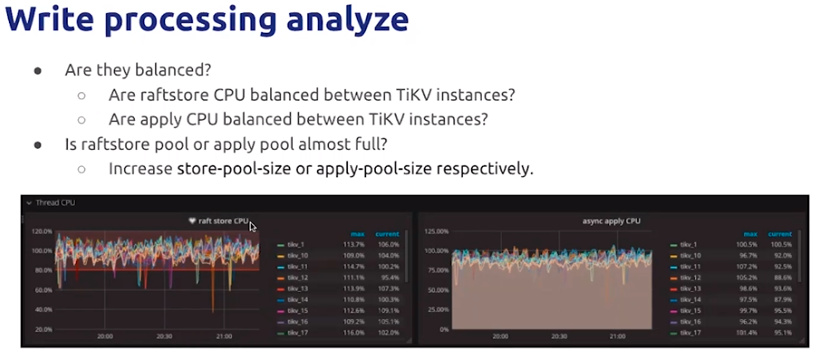
a.通过观察 raftstore & apply CPU,确认是否负载均衡。
b.如果负载均衡,则可通过调整 store-pool-size & apply-pool-size 进行调优。
c.如果通过上面的观察还没有发现瓶颈,则可以继续下面的观察如IO操作是否慢

d.如果发现write duration时间长,则继续如下分析。
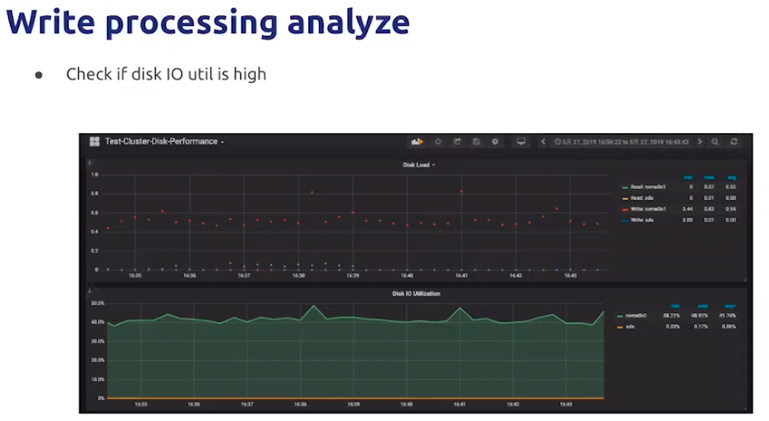
disk IO Util 达到60%以上说明磁盘压力较大
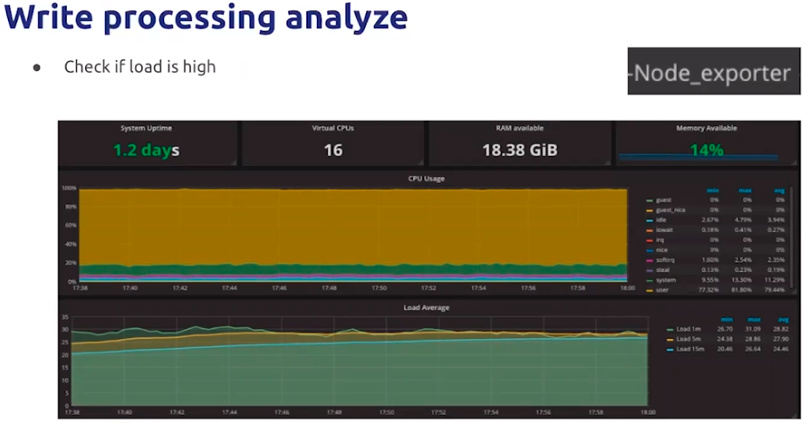
e.检查CPU load负载是否高

max-background-jobs
- RocksDB 后台线程个数。>>>针对too many memtables
- 默认值:8
- 最小值:1
max-background-flushes
- RocksDB 用于刷写 memtable 的最大后台线程数。
- 默认值:2
- 最小值:1
max-sub-compactions
- RocksDB 进行 subcompaction 的并发个数。 >>> 针对 too many level0 files
- 默认值:3
- 最小值:1
compression-per-level
- 每一层默认压缩算法,默认:前两层为 No,后面 5 层为 lz4。
- 默认值:[“no”, “no”, “lz4”, “lz4”, “lz4”, “zstd”, “zstd”]
level0-file-num-compaction-trigger
- 触发 compaction 的 L0 文件最大个数。
- 默认值:4
- 最小值:0
level0-slowdown-writes-trigger
- 触发 write stall 的 L0 文件最大个数。
- 默认值:20
- 最小值:0
level0-stop-writes-trigger
- 完全阻停写入的 L0 文件最大个数。
- 默认值:36
- 最小值:0
f.如果上面分析都没有问题,有可能是log commit慢
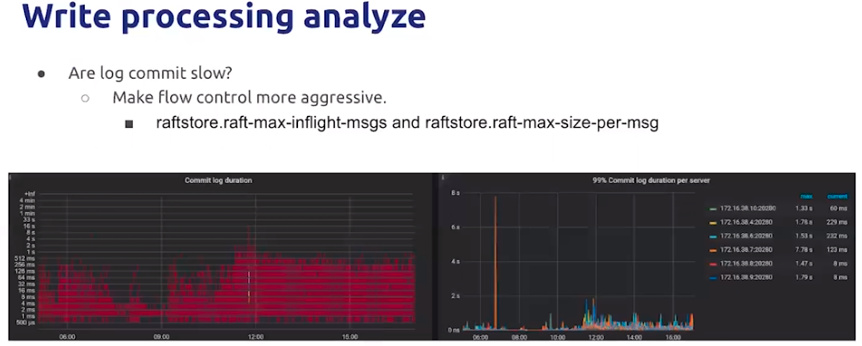
原因可能是网络延迟或ratfstore 流控
raft-max-size-per-message
- 产生的单个消息包的大小限制,软限制。
- 默认值:1MB
- 最小值:0
- 单位:MB
raft-max-inflight-msgs
- 待确认日志个数的数量,如果超过这个数量将会减缓发送日志的个数。
- 默认值:256
- 最小值:大于0
2.2 读请求处理
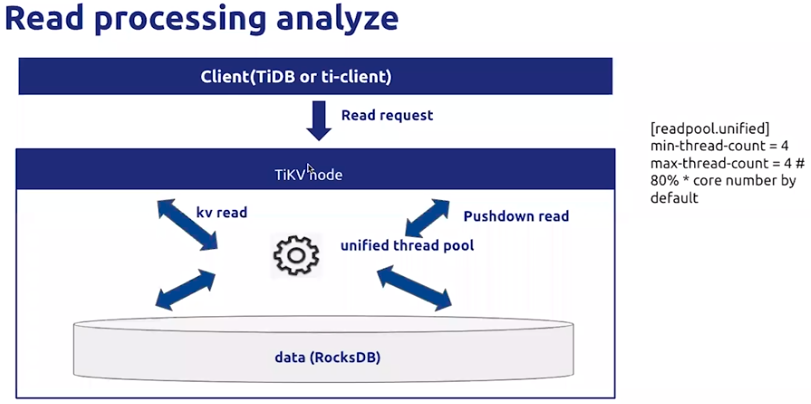
统一线程池(unified thread pool):kv read,Pushdown read
通过参数min-thread-count & max-thread-count控制。
readpool.unified
统一处理读请求的线程池相关的配置项。该线程池自 4.0 版本起取代原有的 storage 和 coprocessor 线程池。
min-thread-count
- 统一处理读请求的线程池最少的线程数量。
- 默认值:1
max-thread-count
- 统一处理读请求的线程池最多的线程数量。
- 默认值:CPU * 0.8,但最少为 4
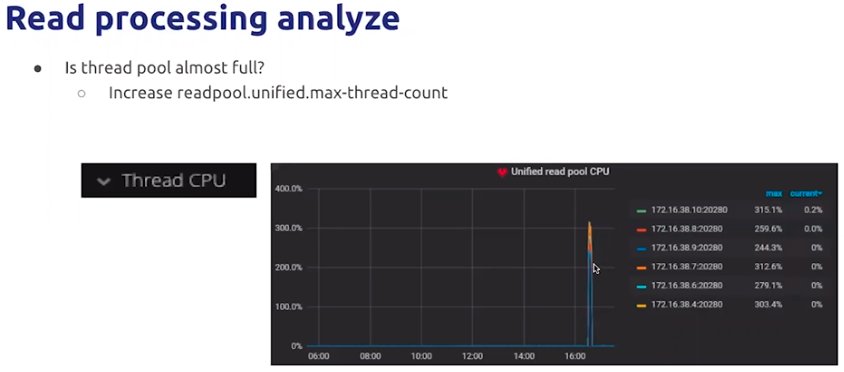
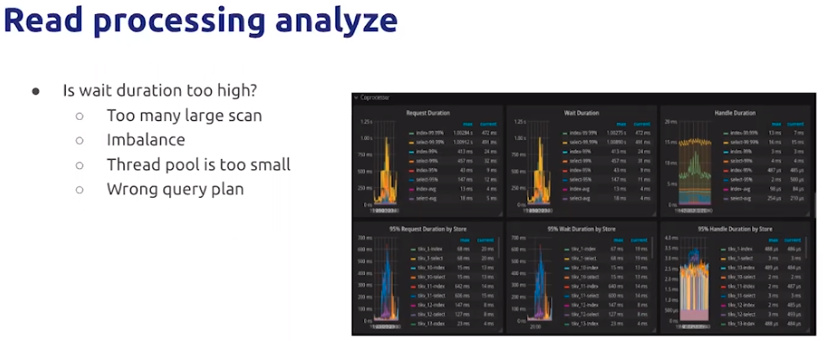
等待时间高,可以观察:大查询、负载均衡情况、统一线程池大小是否太小、查询的执行计划是否正确

再观察cache 命中率是否太低
学习过程中遇到的问题或延伸思考:
- 问题 1:
- 问题 2:
- 延伸思考 1:
- 延伸思考 2: