出现热点,不一定一定会产生问题,tidb也有一定能力识别热点,通过调度来解决。

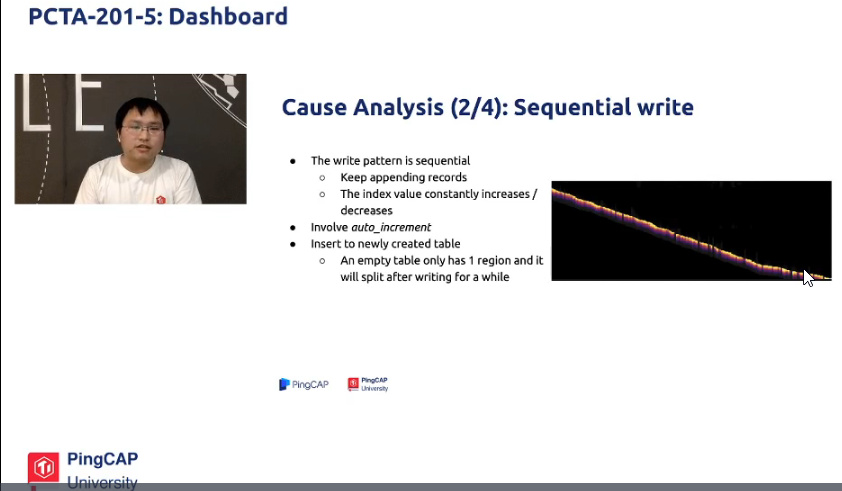
热点问题之一:顺序写。现象是写入集中在某个tikv实例,负载高,io压力大。往新表写数据也会出现这个问题,表新创建时只会存在一个region,只有达到一定量才会分裂,即使是随机写。
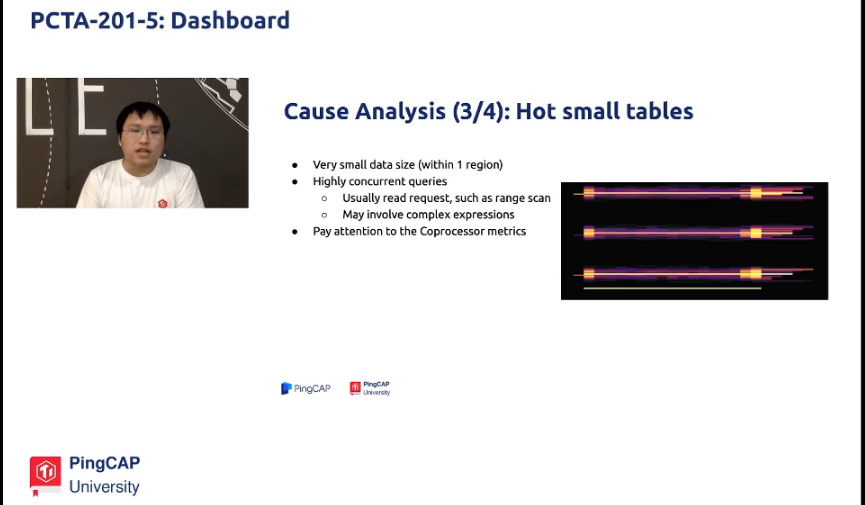
热点问题二:小的热表
热点问题三:region 分布倾斜

解决办法一:分区表,hash分区,可以很好避免顺序写带来的问题。不同的分区可以认为是不同的表。

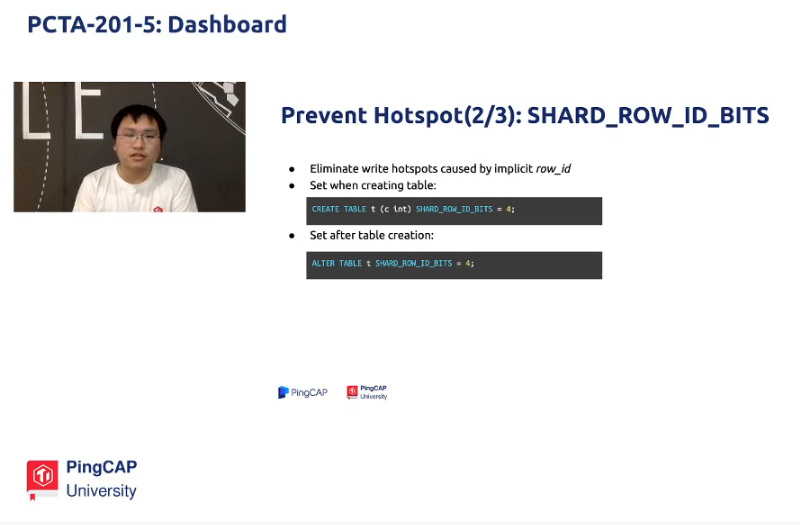
解决办法二:shard_row_id_bits。可以在表创建前和后修改。写入数据时会有一定随机,不是严格的递增
create table t (c int) shard_row_id_bits = 4;
alter table t shard_row_id_bits = 4;
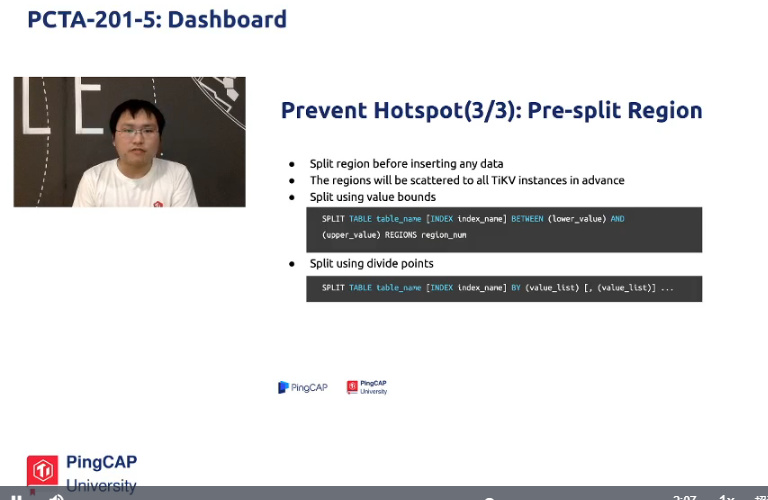
解决办法三:预分类region,效果最好。在写入前把region分布到所有tikv实例。
解决办法四:follower read,将读请求路由到读副本
set session variable tidb_replica_read
read from only followers
set @@tidb_replica_read=‘follower’;
read from all
set @@tidb_replica_read=‘leader-and-follower’

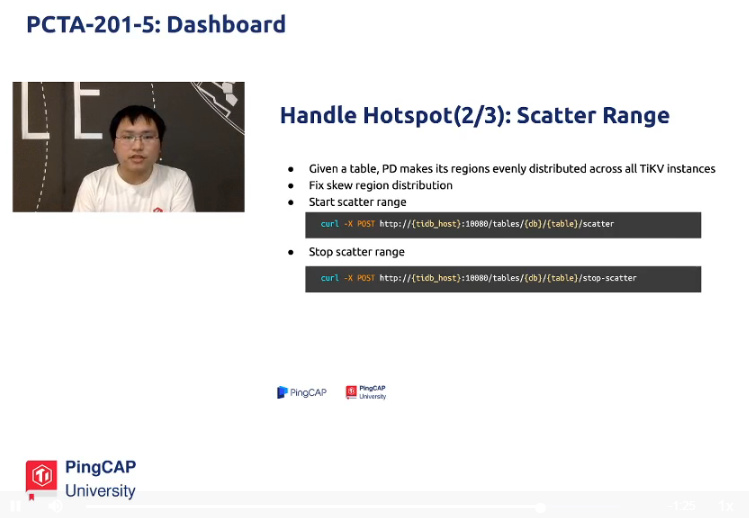
解决办法五:scatter range,给定一个表,pd 使它所有region在tikv 均匀分布
curl -x POST http://{tidb_host}:10000/tables/{db}/{table}/scatter
curl -x POST http://{tidb_host}:10000/tables/{db}/{table}/stop-scatter
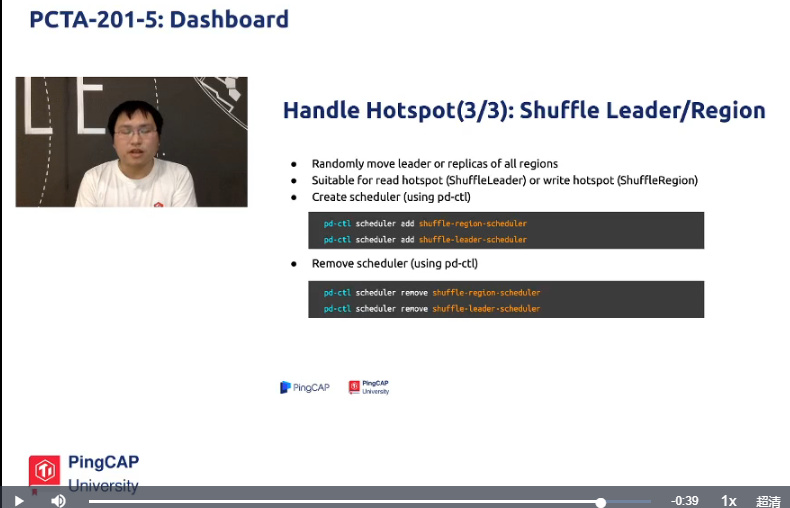
解决办法六:shuffle leader/region。将所有region leader和副本打散.最后一招,工作效率较低
create scheduler
pd-ctl scheduler add shuffle-region-scheduler
pd-ctl scheduler add shuffle-leader-scheduler
stop scheduler
pd-ctl scheduler remove shuffle-region-scheduler
pd-ctl scheduler remove shuffle-leader-scheduler