课程名称:3.7.3 Optimize query health(查询优化器)
学习时长:
20分钟
课程收获:
能够使用系统表 STATEMENTS_SUMMARY 和 SLOW_QUERY 定位不健康的查询以及分析原因。
课程内容:
一、Query health
- 影响因素
- 某个节点是热点,导致数据库瓶颈
- 统计信息过期,导致执行计划发生变化
- 读写冲突
- 通过查询延迟来判断判断是否健康
- 查询延迟不稳定,时快时慢
- 查询延迟过高
- 查询延迟组成部分

二、Find the unhealthy query
1.STATEMENTS_SUMMARY(STATEMENTS_SUMMARY_HISTORY)
- 部分表结构
- 是系统内存表,重启TiDB Server后将丢失数据
- 记录了SQL digest和plan digest聚合后每种SQL类型的执行信息、汇总数据
- 为了保持数据及时行,会定期清理数据,默认保留30分钟内的历史数据
- STATEMENTS_SUMMARY_HISTORY与STATEMENTS_SUMMARY表结构相同,用于保存历史时间段的数据,从而排查过去的异常和对比执行情况

- SQL Digest & Plan Digest
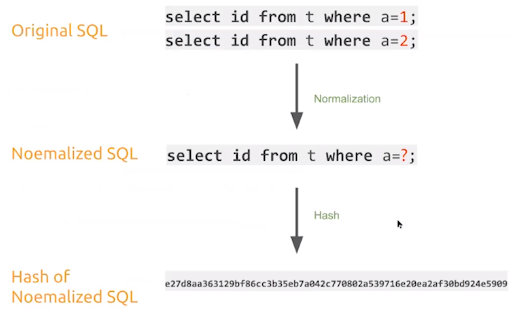
- 同类型的SQL他的指纹是一样的
- Plan指纹与SQL指纹相类似,通过Plan指纹快速定位是否有query的执行计划发生了变更
- SLOW-QUERY-FILE
- Slow-query系统表数据是从慢日志文件中解析的
- TiDB会将执行时间超过慢日志时间阈值的query及其执行信息记录到其中,包括执行时间及query当时的执行计划信息
- 慢日志文件格式兼容MySQL,一些MySQL慢日志分析工具可以TiDB慢日志上工作,例如pt-query-digest
- SLOW_QUERY
- 部分表结构

- 是TiDB的系统表
- 是从慢日志中解析得到的
- 用于方便用户通过SQL查询慢日志信息,避免直接搜索慢日志文件
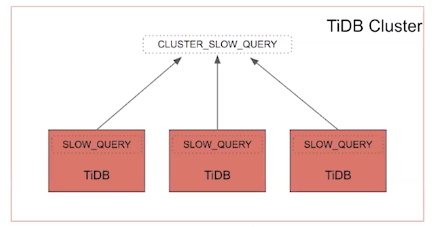
- CLUSTER TABLE
多个TiDB实例时可以通过集群的CLUSTER_SLOW-QUERY-FILE和CLUSTER_SLOW_QUERY查询所有实例的信息
- STATEMENTS_SUMMARY查询示例:
- 查询SQL总时间最长
SELECT sum_latency,avg_latency,query_sample_text FROM information_schema.statements_summary ORDER BY sum_latency DESC LIMIT 3; - 查询某个具体SQL的平均延迟及总数量
SELECT Aavg_latency,exec_count,query_sample_text FROM information_schema.statements_summary WHERE digest_text LIKE ‘SELECT count(*) FROM employee%’; - 查询queries执行计划是否发生变更
SELECT digest,COUNT(),MIN(QUERY_SAMPLE_TEXT),MIN(plan),MAX(plan) FROM SEATEMENTS_SUMMARY GROUP BY digest HAVING COUNT() >1; - 查询test用户TOP-N的慢查询
SELECT query_time ,query ,user FROM cluster_slow_query WHERE is_internal = false AND user like “test%” ORDER BY query_time desc LIMIT 2; - 查询统计信息过期的慢查询
SELECT query ,query_time ,stats FROM cluster_slow_query WHERE is_interna = false AND stats like ‘%pseudo%’; - 查询执行计划变更的慢查询
SELECT COUNT(distinct plan_digest) AS count ,disgest ,MIN(query) FROM cluster_slow_query GROUP BY digest HAVING count > 1 LIMIT 3; - 发现某个时间段QPS降低或上升可能是由于大查询导致,通过下面SQL仅查看异常时间段的查询
SELECT * FROM (SELECT count(*),min(time),sum(query_time) AS sum_query_time, sum(Process_time) AS sum_process_time,sum(Wait_time) AS sum_wait_time,sum(Commit_time),min(query),digest FROM information_schema.CLUSTER_SLOW_QUERY WHERE time >=‘2020-03-10 13:24:00’ AND time < ‘2020-03-10 13:27:00’ AND Is_internal = false GROUP BY digest) AS t1 WHERE ti.digest NOT IN (SELECT digest FROM information_schema.CLUSTER_SLOW_QUERY WHERE time >= ‘2020-03-10 13:20:00’ AND time < ‘2020-03-10 13:23:00’ GROUP BY digest) ORDER BY t1.sum_query_time DESC limit 10\G;