课程名称:3.7.5 TiDB 的分表
学习时长:15min
课程收获:分区表的种类以及使用方法,以及分区裁剪的原理
课程内容:
-
使用分区表
-
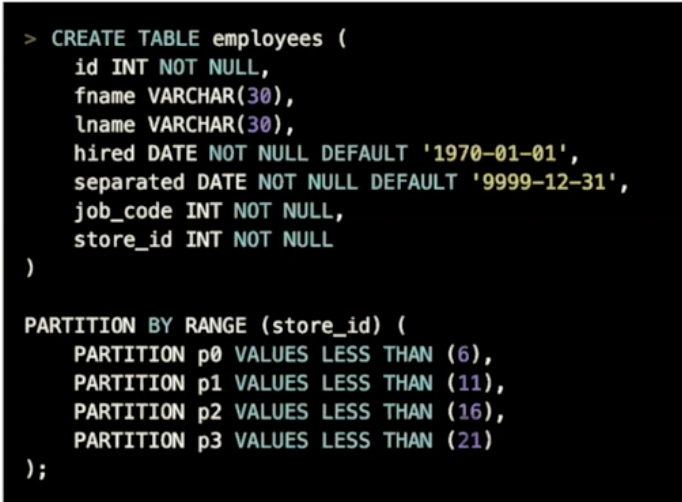
range partition
-
可以按单个列进行分区,或按多个列的组成的函数进行分区
-
less than + 整型
-
less than 支持unix_timestamp或year之类的
-
分区表达式包含的列必须包含在唯一索引中
-
适用场景
- 适用于需要按范围删除数据,删除数据变成删除分区
- 数据有时间列,并且需要按照时间范围查询
- 如果小表有读热点,可以使用分区来解决热点
-
-
range columns partition 按列范围分区
- 只支持单个列作为range表达式
- 支持按整型,字符串,时间进行分区
-
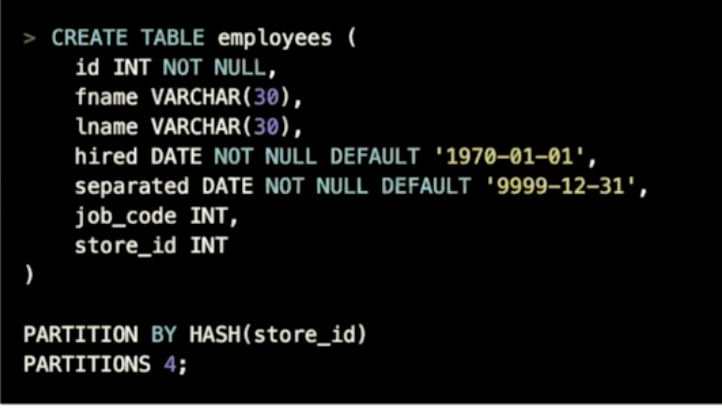
hash partition
-
单点查询性能高,范围查询性能差
-
分区表达式包含的所有列,必须包含在所有唯一索引中
-
NULL值默认会被划分到第0个分区
-
表达式分区必须返回整型
-
适用场景
- 用于单点查询,范围查询会导致全表扫描
- 由于通过hash函数分布数据,每个查询都只会落在一个分区上
- 可解决小表读热点
-
-
-
分区表内部原理
-
分区裁剪
- 通过不扫描不匹配的分区来达到优化
- 不好的SQL会导致分区裁剪失败,导致全表扫描
-
范围分区的裁剪
-
假设partition by range(col)
- col=7可以裁剪成功
- col between 1 and 10可以裁剪成功
- (col < 10 and c > 5) or ( col > 11 and col < 13)可以裁剪成功
- col+3 = 5 or col + 10 < 7 会导致裁剪失败
-
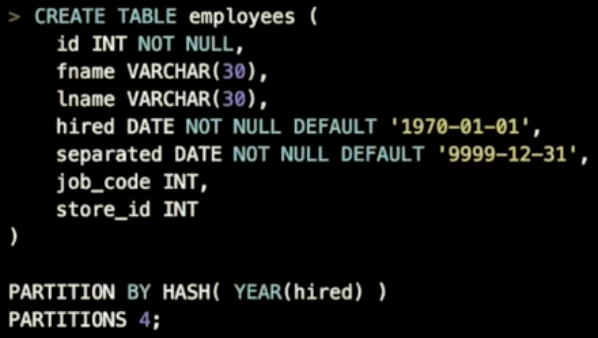
假设 按 col_a + col_b或function(col_a)进行分区
- col < val并不能推断出fn(col) < fn(val),裁剪会失败
- TiDB只支持unix_timestamp 和 to_days 这样的单调函数
- 所以,最好使用unix_timestamp(col)或to_days(col)来分区
-
-
哈希分区裁剪
-
优化器需要了解分区表达式中所有列的值
-
如果分区表达式是 col
- col=7可以,因为可以直接定位到分区
- col between 3 and 7会失败,因为并没有指定具体值,而是范围值
- col < 10 and col > 3 也会失败
-
分区表达式是a+或year(a)+b
- a=5 and b=6会裁剪成功
- a=6会失败
- year(a)=7 and b=5会也是失败
-
-
关于分区裁剪,需要注意
-
分区裁剪发生在优化器逻辑优化阶段,一些运行时才能得到结果的条件并不能作为分区裁剪的条件,比如
- select * from t2 where x < (select * from t1 where t2.x < t1.x and t2.x < 2)
- x在逻辑优化阶段并不能确定值
-
分区裁剪不支持index join(TiDB5.0可能会支持)
- 因为outer表的值用于对inner表分区裁剪,而此时outer表的值还不知道
-
-