课程名称:3.7.2 The lifecycle of a SQL and relevant metrics(TiDB 的 SQL 的生命周期和关键监控指标)
学习时长:
20分钟
课程收获:
如何定位到性能问题
课程内容:
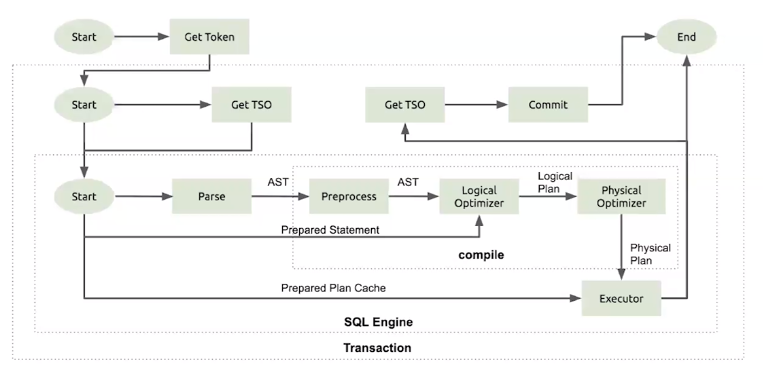
一、TiDB
-
流程图
-
Before Execution
(1)获取Token- 用于限制同时执行的SQL数,避免并发过大导致TiDB崩溃
- 通过’token-limit’配置限制
- 通过Grafana(Get Token)查看:耗时较高说明达到了Token上限,有SQL等待
(2)获取TSO
- 开始事务和提交事务都会向PD获取TSO(异步获取)
- 通过Dashboard(SQL Statement和Slow Queries)体现
- 通过Grafana(PD TSO Wait Duration)查看:此值高说明TiDB的负载高
- 通过Grafana(PD TSO RPC Duration)查看:此值高说明TiDB和PD之间的网络慢或PD的负载高
-
Parse & Compile
(1)Parse- Parse耗时在Dashboard(SQL Statements与Slow Queries)体现、在Grafana(Pares Duration)体现
- 一般只有insert时高
(2)Compile
- 包括预处理和Compile阶段
- 预处理包括合法性验证和类型推导
- Compile一般在复杂查询时慢
(3)Prepared Statements
- 开启后可节省Parse和预处理的开销
- 通过Grafana中的Prepare Statement Count查看是否生效
(4) Prepared Plan Cache
- 开启后可节省optimizing的开销
- 通过Grafana中的Plan Cache Hits查看是否生效
-
Execution
(1)Execution Duration- 通过Execution Duration可以看出整体耗时
(2) Expensive Executors OPS
- 通过Expensive Executors OPS可以看出复杂算子的OPS
- 这些算子可以调整并发度降低延迟(tidb_{operator}_concurrency)
(3)KV Request
- 通过KV Request可以看出TiKV请求的耗时
- Region Error可以导致延迟(TiClient Region Error OPS)
- Lock Resolve可以导致延迟(Lock Resolve OPS),锁冲突高
-
DiskSQL
是TiDB向TiKV发送请求和接收数据的接口
(1)DistSQL Duration- 可以看出DiskSQL请求延时
- 通过系统变量’tidb_distsql_scan_concurrency’控制并降低延迟
(2)Scan Keys
- 体现出扫描的数据量会直接影响延迟
- 通过Dashboard(SQL Statements与Slow Queries)体现
- 通过Grafana(Scan Keys)体现
(3)Coprocessor、Get和Batch Get
通过KV Request可以看出OPS -
Transaction
(1)通过KV Transaction Duration可以看到事务在TiKV的耗时(2)Local Latch耗时因素
- 是TiDB在事务commit之前对事务进行排序用的锁
- 当所冲突较多时可以打开,默认是关闭的
- 通过Dashboard(SQL Statements与Slow Queries)体现
- 通过Grafana(Local Latch Wait Time)体现
(3) 事务重试
- 事务重试只在出现一部分错误时会尝试,例如写冲突
- 通过Dashboard(SQL Statements与Slow Queries)体现次数
- 通过Grafana(Transaction Retry Num)体现次数
二、TiKV
-
流程图
-
KV Requset
gRPC Message Duration(反应TiKV处理请求的延迟)- 包括kv_get/kv_batch_get和coprocessor
- TiDB上的KV Duration延迟约等于TiKV上的gRPC Message Duration延迟network RTT延迟,如果TiDB上的KV Duration延迟与TiKV上的gRPC Message Duration延迟不对等,说明TiDB和TiKV之间的网络延迟高
-
Transaction
(1)Prewrite & Commit
通过Dashboard(SQL Statement和Slow Queries)体现单个事务的量
(2)Resolve Lock- 通过Dashboard(SQL Statement和Slow Queries)体现单个事务的量
- 通过Grafana(Lock Resolve OPS)体现单个事务的量
-
Raft Store
Raft Store发生在写流程中,用来把Raft log同步到所有副本
(1)Raft propose- Propose等待事件
- Apply等待事件
(2)Raft IO
- Append log把日志追加到Raft log结尾
- Apply log是把日志应用到数据库上
- Commit log是提交日志
-
Coprocessor
(1) Coprocessor执行时间- 从Request Duration上查看,通常与处理的数据量相关
- 通过Dashboard(SQL Statement和Slow Queries)体现
(2)Coprocessor等待时间
- 从Wait Duration上查看,如果等待时间高可以尝试打开Coprocessor cache
- 通过Dashboard(SQL Statement和Slow Queries)体现
-
Rocks DB
每个TiKV有两个Rocks DB实例,一个存储Raft日志,另一个存储用户数据
(1)Read- 先读取Memtable,没命中读取Block cache,没命中读取SST
- 从这些监控项中可以找出对应的耗时以及命中次数,根据实际情况调整配置
(2)Write
- 观察Write duration
(3)Compaction
- 通过Compaction operations可以看到Compaction次数
- 通过Compaction duration可以看到Compaction耗时
