SQL排查思路
- 发现SQL执行时间长,先查询TIDB和tikv的网路延迟是否增大,之后可以判断是否出现在tikv侧,查看监控是否是tikv的存储或者raft的问题等
- 当发现SQL的延迟上涨,优先检查TiDB和TiKV的通信延迟,这个延迟代表着TiKV执行命令且回复到TiDB的大致时间,然后通过对比TiKV侧统计的命令执行时间,可以确定网络部分是否正常,大部分情况这2侧时间是一致的
- 当延迟出现在TiKV侧,通过分析TiKV存储引擎的各项指标,可以判断落盘是否出现了问题,如果不是,那么延迟出现在TiKV的其他部分,包括raft同步,等待锁延迟等等
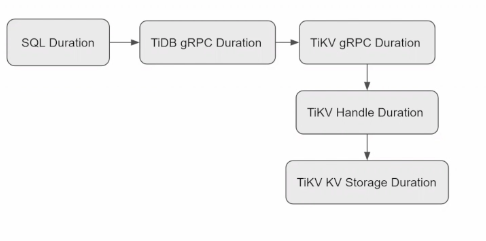
- TiKV架构
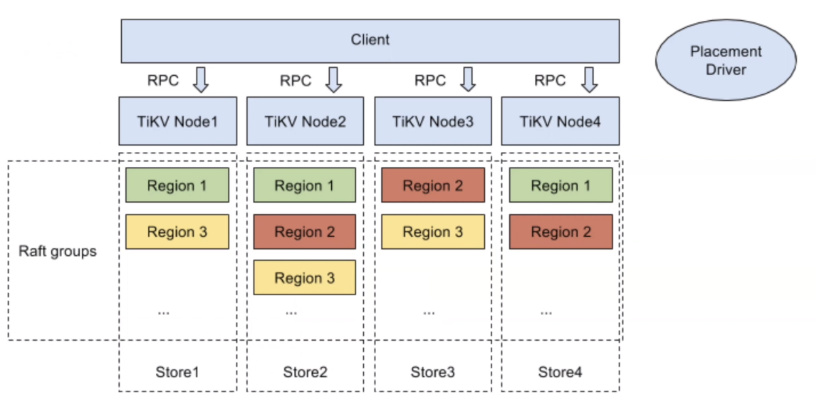
- TiKV Storage Layer
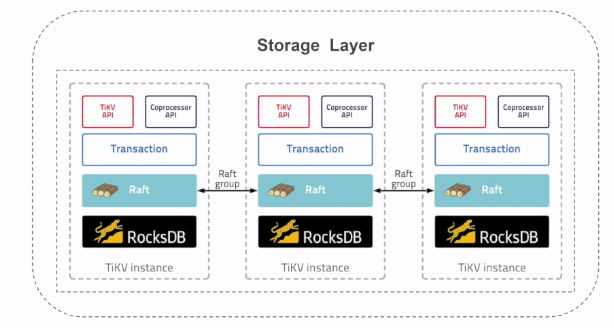
- TiKV 模块
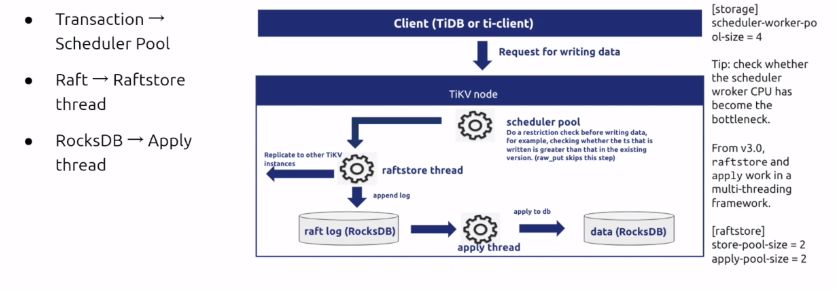
TiKV调优
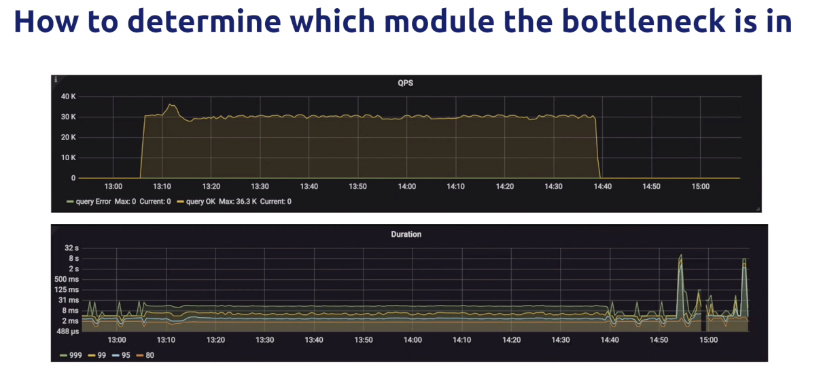
- 当出现异常时候,比如客户端某些SQL较高,我们应该首先在grafana面板中找到对应的时间段,查TiKV的执行延迟和QPS,查看Duration是否符合预期,一般情况99pth读延迟是100ms以下,99pth写延迟是在500ms以下,超出部分就是异常部分
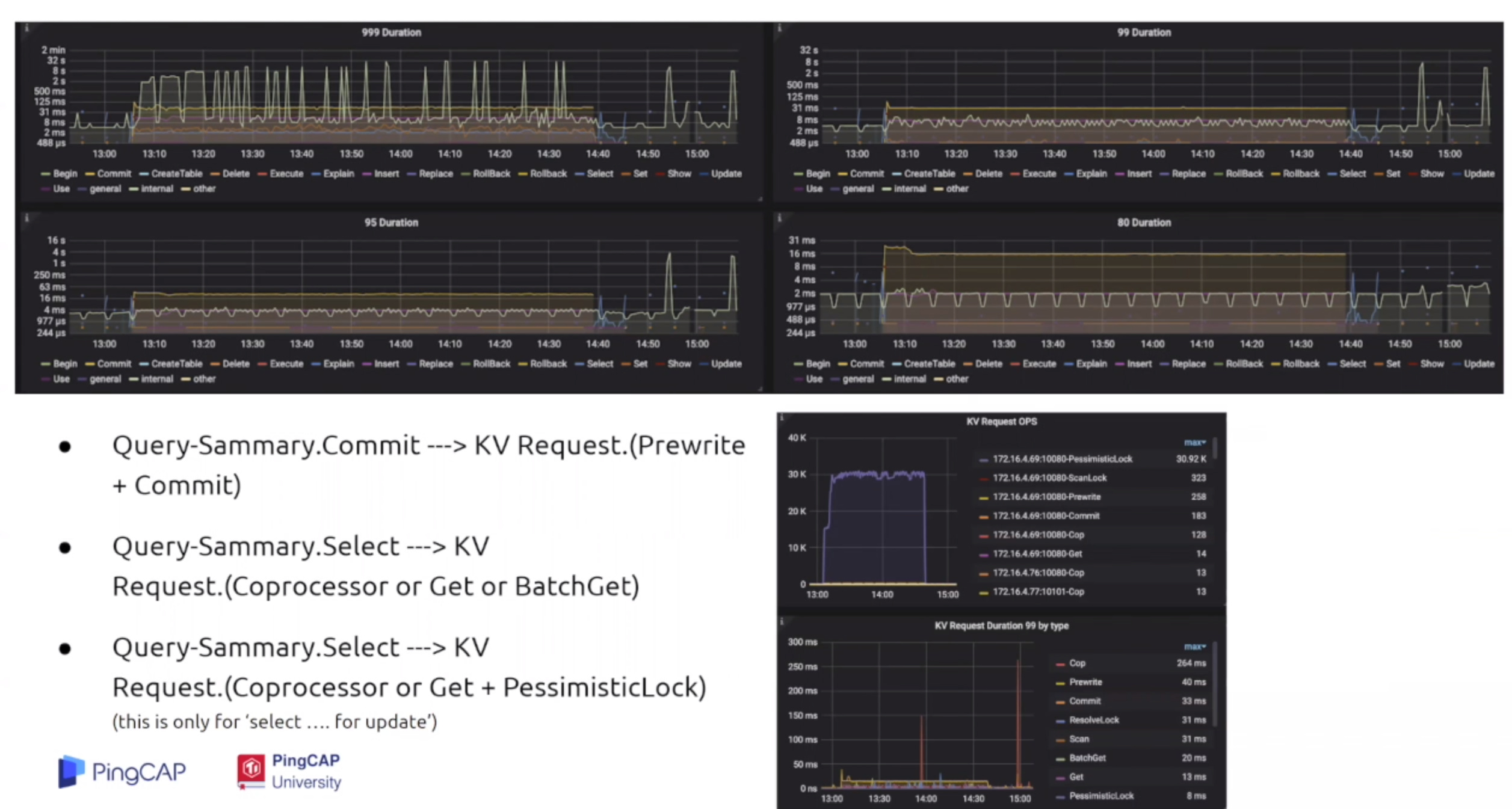
- 通过Query-Sammary中的监控来判断是什么写入缓慢,可以重点关注Select和Commit操作,后者会启动两阶段提交,SQL的 Select操作和 KV Request中的请求存在对应关系,通过KV Request Duration这个面板可以判断延迟的主要消耗是TiDB进程还是TiKV的进程,如果这一项没有异常,那就证明TiKV的处理是很快的,那就可以缩小问题到TiDB侧,同时也可以通过KV Request QPS 和Query QPS来对比,从侧面推断查询计划是否正确

- gRPC是TiKV的请求入口,那我们就可以通过gRPC请求入口的message数量以及gRPC Duration来验证上一步在TiKV Request的延迟是否正确,假设问题出在TiKV侧,以prewrite请求为例,prewrite请求会被gRPC转发给事务层的Scheduler库,这里的Scheduler latch wait dutarion是TiKV为了防止多个事务对同一个key进行读写检测造成写倾斜而加的锁,Scheduler Command duraiton就是prewrite请求执行事务冲突检测以及写入raft store的时间之和,如果这些metric都挺正常,就可以继续往下分析

- 这个面板统计了包括了从raft开始propose,然后发送复制消息,然后follower,然后follower回复ack给leader,leader将数据写入rocksdb,并且写入成功这一系列操作的总耗时,就是事务层下层的总耗时,如果这层的延迟较高,那么就可以推断出延迟不是出现在事务层,而是在raft store层或者是raft store以下的层级
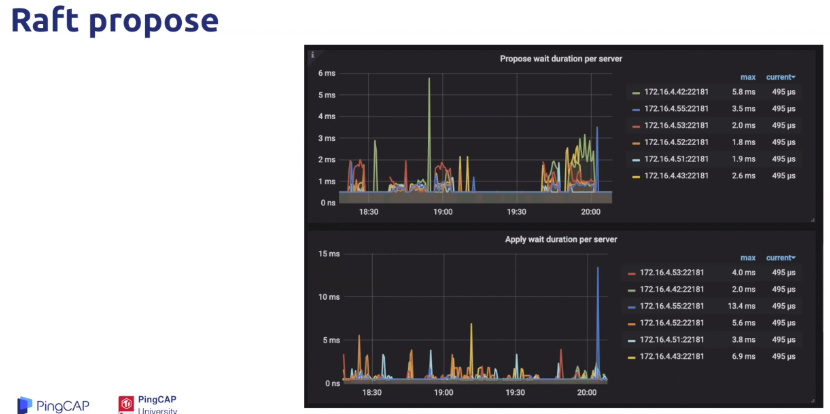
- 确认问题是出现在store之后,我们就可以细化分析每个步骤,现在raft propose,这里两个指标分别代表了raft store线程和apply线程的执行情况,前者含义为transcation层开始向raft层写入数据到raft层接收到消息并开始处理等待时间,而后者是raft层的leader和follower达成一致,开始异步的写入数据到Apply线程接收到消息准备真正的写入底层的存储引擎及rocksdb的等待时间。这里我们可以优先查看wait,而不用raft IO中真正处理消息所花费的时间,是因为这些wait指标隐含了消息在队列中等待的时间,也从侧面反应出线程的繁忙程度,对于写入请求,当我们看到这部分的时候,基本就可以判断写入延迟造成的原因了,如果是apply延迟很高,那很可能是apply线程数的配比太小,如果是propose的延迟很高,那很可能是盘太差,导致了性能的延迟高,或者是raft线程数的配比太小
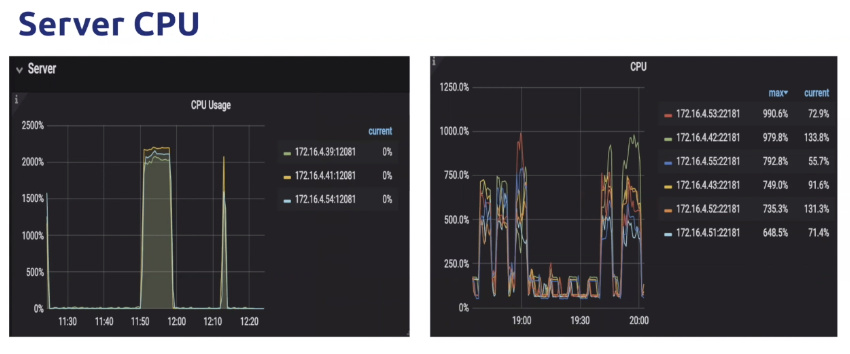
- 如果TiKV中的CPU占用已经达到物理机CPU的上限,那么各个模块的上涨就是理所应当的
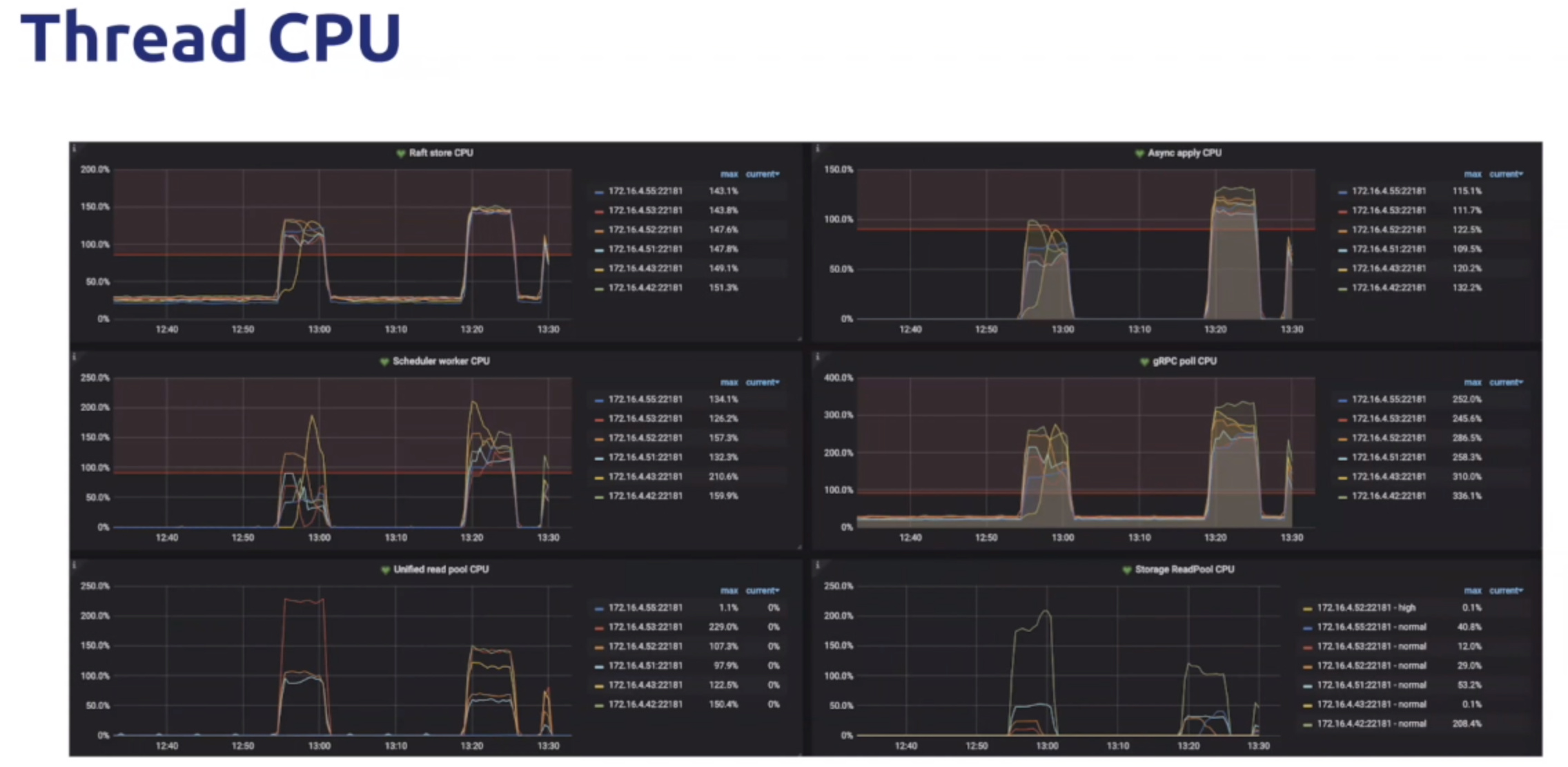
- 如果apply延迟很高,通常4个原因
- apply线程的数量,可以通过Async apply CPU来看是否接近了配置的Apply process这个选项,如果利用率已经达到了这个选项所代表的线程池上限80%以上的话,那就可以调大线程池,就是调大apply的线程数量
- 整机CPU资源利用率太高,导致线程争抢不到足够的cpu资源,可以通过server cpu判断出来
- 产生了write stall,这是因为写入被rocksdb阻塞限流了
- TiKV部署的盘太差了,达到了吞吐上限
- 如果raft store延迟较高,也是有4个原因
- 线程CPU不足
- 心跳过于频繁,可以开启。。。来减少心跳数,该功能是4.0及以上版本默认开启,整个集群需要全部开启或者全部关闭
- 磁盘性能不好
- rocksdb 发生了write stall
常见问题
rocksdb写入流程
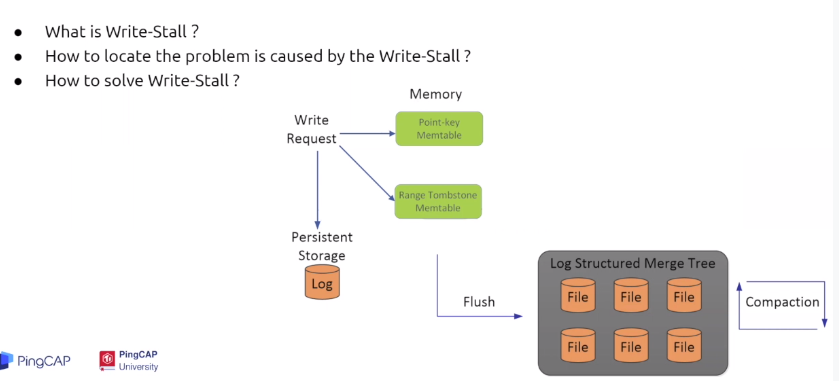
- rocksdb的写入流程
这里认为写入的数据就是简单的多对key-value pair ,一对key-value首先被写入到memory table中,这是一个内存数据结构,用于将数据持久化到盘之前保存数据,一旦memory table写满,后台的线程会将此memory table的数据刷入ssd文件中,成功后销毁之前写入过的memory table,成功将memory table写入的ssd文件我们称为L0层文件,但是如果写请求过多,以致于快过了rocksdb能处理的线程,rocksdb就会限制写入,这就是rocksdb 的write stall来源。如果没有write stall 的限制,写方会导致rocksdb很快占用大量的磁盘空间,同时也降低了磁盘的IO性能,如果想判断rocksdb是否正在被write stall限制,而导致TiKV持久化缓慢,可以通过rocksdb本身的log文件判断,这个log文件一般存储在tikv/data/db目录 - 产生write stall的原因
- 过多memory table,当需要落盘的memory table超过了最大的缓存数量限制,那就必须触发write stall,来避免来产生更多的memory table
- 过多的L0层文件,当处于L0的lst连接数量达到预值也会触发,否则会导致更多写盘影响后续的compaction性能
- 过多等待compaction数据,这是因为compaction的速度已经达到极限,更多的写入会带来更多的compaction,等过了这段compaction高峰,才能继续写入
避免write stall
- 增加memory table缓存数量
- 增加racksdb线程
读请求调优
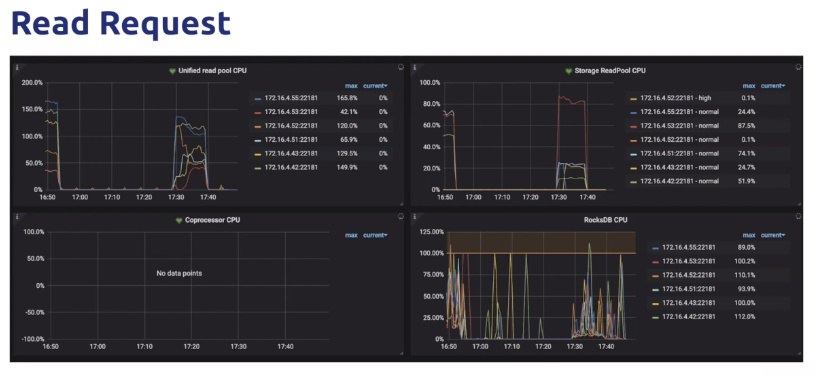
- 简单的查询,被Storage ReadPool处理
- 复杂的聚合计算和范围查找,被coprocessor处理
- 4.0及以后版本支持统一线程池,即unified read pool,同时支持这2类请求的查询,避免更多的线程分配
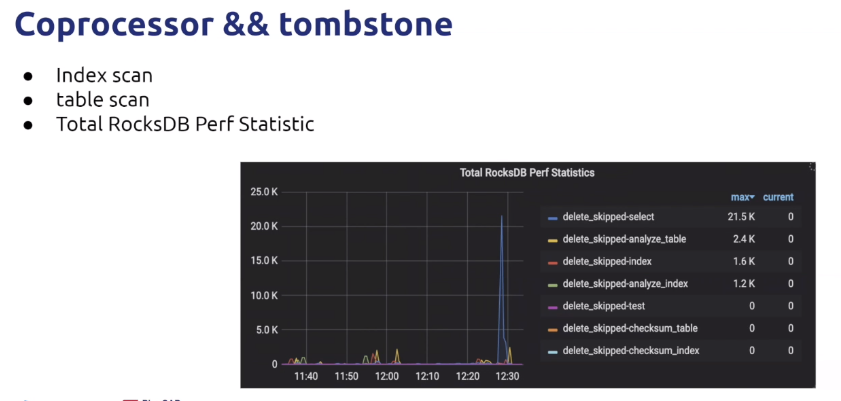
- 错误的查询计划也会导致过多的查询请求发送给TiKV