课程名称:3.7.1 Metrics that DBAs should notice(运维中的关键监控)
学习时长:
40分钟
课程收获:
熟悉哪些对运维过程中需要关注的性能相关的监控指标
课程内容:
一、系统信息

- CPU使用率
需要低于80% - CUP load
需要小于CPU总核数 - 内存使用率
- TiKV节点内存使用率小于60%
- TiDB节点内存使用率小于80%
- 网络使用率
不占满整个主机网卡 - IO Util
Util值低于80%
二、TiDB

- Query Summary
- Duration:.99对于OLTP需要小于100毫秒以内
- Slow query:正常不应出现慢查询
- Ideal CPS:如实际QPS与理想QPS相同,问题出现在TiDB端,数据库增加并发提高CPS;如果实际QPS低于理想QPS,问题出现在客户端
- Server
Get token duration:小于1ms,需要调大token-limit参数(默认为1000)
- Exector
- Parse duration:小于10ms
- Compile duration:小于30ms
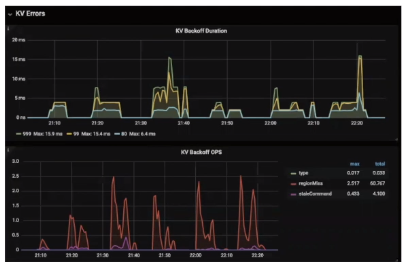
- KV Errors
- Lock Resolve OPS:小于500,出现过高的锁冲突时解锁冲突,需要关注事务间冲突是否合理,如果业务本身有很多冲突建议使用悲观锁
- KV Backoff OPS:小于500,可能由Region问题、TiKV段异常导致
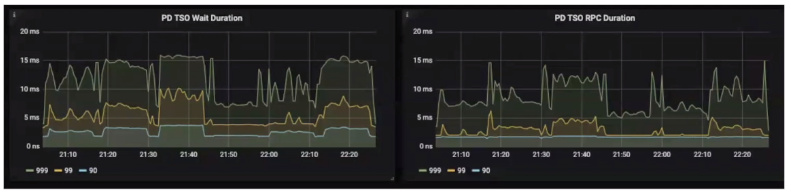
- PD Client
PD TOS.99 Wait Duration:小于5ms,过高说明TiDB压力高
三、TiKV
- Cluster
Region:小于50K,否则会使单个TiKV节点的心跳开销和Raft状态机的开销存在过大可能,建议通过region merge功能合并region,降低没有流量的region心跳开销 - gRPC
.99 gRPC message duration:小于100ms,重点关注,越低越好,但coprocessor requests请求可以大于100ms - Thread CPU
- Raft store CPU:小于(75%×’raftstore.store-pool-size’)
- Async apply CPU:小于(75%×’raftstore.apply-pool-size’)
- Scheduler worker:小于(80%×’storage.sheduler-worker-pool-size’)
- gRPC pollCPU:小于(80%×’server.grpc-concurrency’)
- Unified read poll CPU:小于(80%×’readpool.unified.max-thread-count’)
- Storage ReadPoll CPU:小于(80%×’readpool.storage.normal-concurrency’)
- Raft IO
- Append log duration:.99latency小于10ms(具体看磁盘速度和业务容忍度)
- Apply log duration:.99latency小于30ms(关注线程数及系统繁忙)
- Commit log duration:.99latency小于30ms(涉及网络延迟情况)
- 需要关注.999,可以看出毛刺问题
- Raft propose
- Propose wait duration:.99latency小于20ms(Raft模块繁忙度)
- Apply wait duration:.99latency小于50ms(与Apply模块繁忙度成正比)
- 需要关注.999,可以看出毛刺问题
- Errors
Server is busy:不应该出现busy情况,会标明相关问题
四、PD
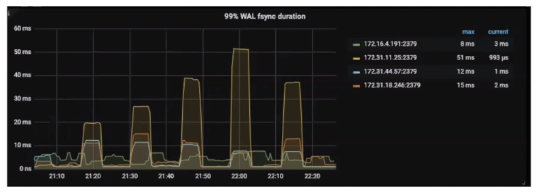
- etcd
.99 WAL fsync duration:小于5ms(显示刷盘速度) - Heartbeat
.99 Region heartbeat latency(PD负载较高,查看Region数量及PD本身问题)
五、Dashboard
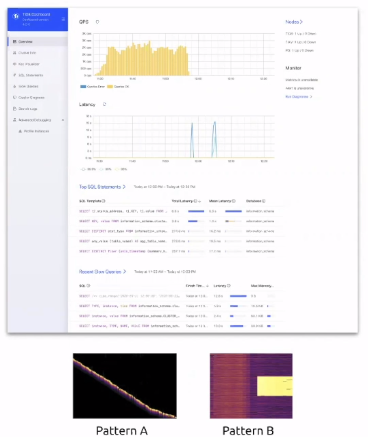
通过http://PdAddr:PdPort/dashboard界面登陆
- Summary
- QPS/Latency
- Top SQL
- Lates Slow Query
- keyviz
Pay attention to hot sport issue - SQL statements
Execute count/Avg latency - Slow Query
Execute plan