课程名称:3.6.1 Data migration tools introduction (TiDB 数据迁移工具介绍)
学习时长:
20min
课程内容:
Dumpling
-
逻辑导出
- 导出为SQL或csv文件
- 导出为SQL或csv文件
-
相比mydumper优点


- 支持导出多种数据形式,包括 SQL/CSV
- 支持全新的 table-filter,筛选数据更加方便
- 支持导出到 Amazon S3 云盘
- 针对 TiDB 进行了更多优化:
- 支持配置 TiDB 单条 SQL 内存限制
- 针对 TiDB v4.0.0 以上版本支持自动调整 TiDB GC 时间
- 使用 TiDB 的隐藏列
_tidb_rowid优化了单表内数据的并发导出性能 - 对于 TiDB 可以设置 tidb_snapshot 的值指定备份数据的时间点,从而保证备份的一致性,而不是通过
FLUSH TABLES WITH READ LOCK来保证备份一致性。

Lightning
- 导入数据工具
- 以下场景可以使用Lightning
- 快速大量导入数据
- 备份恢复
- 架构
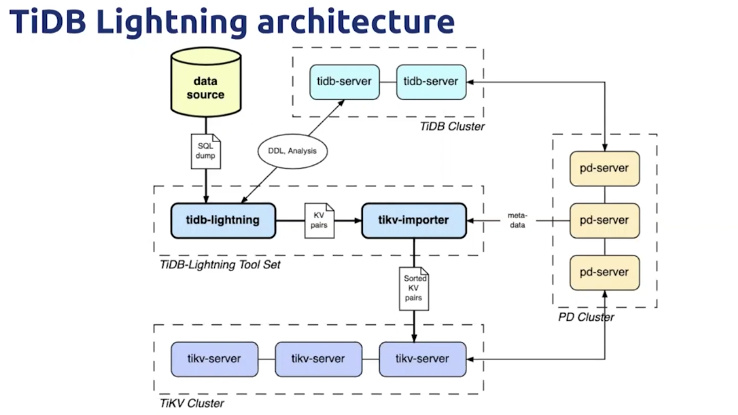
TiDB Lightning 整体工作原理如下:


- 在导数据之前,
tidb-lightning会自动将 TiKV 集群切换为“导入模式” (import mode),优化写入效率并停止自动压缩。 -
tidb-lightning会在目标数据库建立架构和表,并获取其元数据。 - 每张表都会被分割为多个连续的 区块 ,这样来自大表 (200 GB+) 的数据就可以用增量方式并行导入。
-
tidb-lightning会为每一个区块准备一个“引擎文件 (engine file)”来处理键值对。tidb-lightning会并发读取 SQL dump,将数据源转换成与 TiDB 相同编码的键值对,然后将这些键值对排序写入本地临时存储文件中。 - 当一个引擎文件数据写入完毕时,
tidb-lightning便开始对目标 TiKV 集群数据进行分裂和调度,然后导入数据到 TiKV 集群。引擎文件包含两种: 数据引擎 与 索引引擎 ,各自又对应两种键值对:行数据和次级索引。通常行数据在数据源里是完全有序的,而次级索引是无序的。因此,数据引擎文件在对应区块写入完成后会被立即上传,而所有的索引引擎文件只有在整张表所有区块编码完成后才会执行导入。 - 整张表相关联的所有引擎文件完成导入后,
tidb-lightning会对比本地数据源及下游集群的校验和 (checksum),确保导入的数据无损,然后让 TiDB 分析 (ANALYZE) 这些新增的数据,以优化日后的操作。同时,tidb-lightning调整AUTO_INCREMENT值防止之后新增数据时发生冲突。表的自增 ID 是通过行数的 上界 估计值得到的,与表的数据文件总大小成正比。因此,最后的自增 ID 通常比实际行数大得多。这属于正常现象,因为在 TiDB 中自增 ID 不一定是连续分配的。 - 在所有步骤完毕后,
tidb-lightning自动将 TiKV 切换回“普通模式” (normal mode),此后 TiDB 集群可以正常对外提供服务。
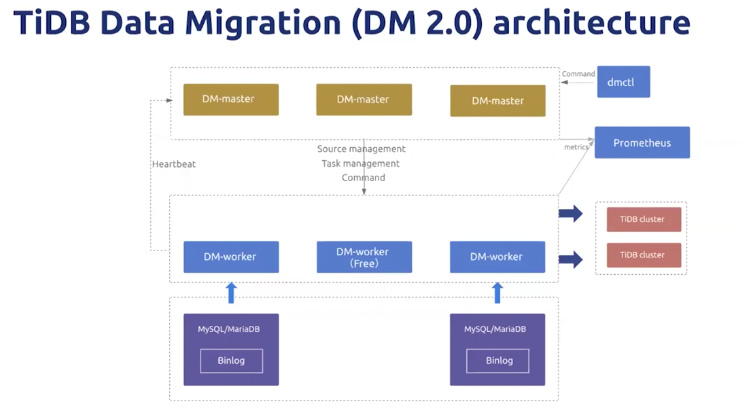
DM2.0


- 架构