课程名称:课程版本(101/201/301)+ 课程名称
学习时长:1H
课程收获:
学习 TiDB 中的一些优化规则,和部分优化规则的原理和使用。
课程内容:
TiDB SQL Layer

- 优化器 - 抽象语法树转为执行算子
- 统计信息 - 指导优化器选择计划
- Execution engine - 计算算子
Optimization Tuning Guide
- Explain Result
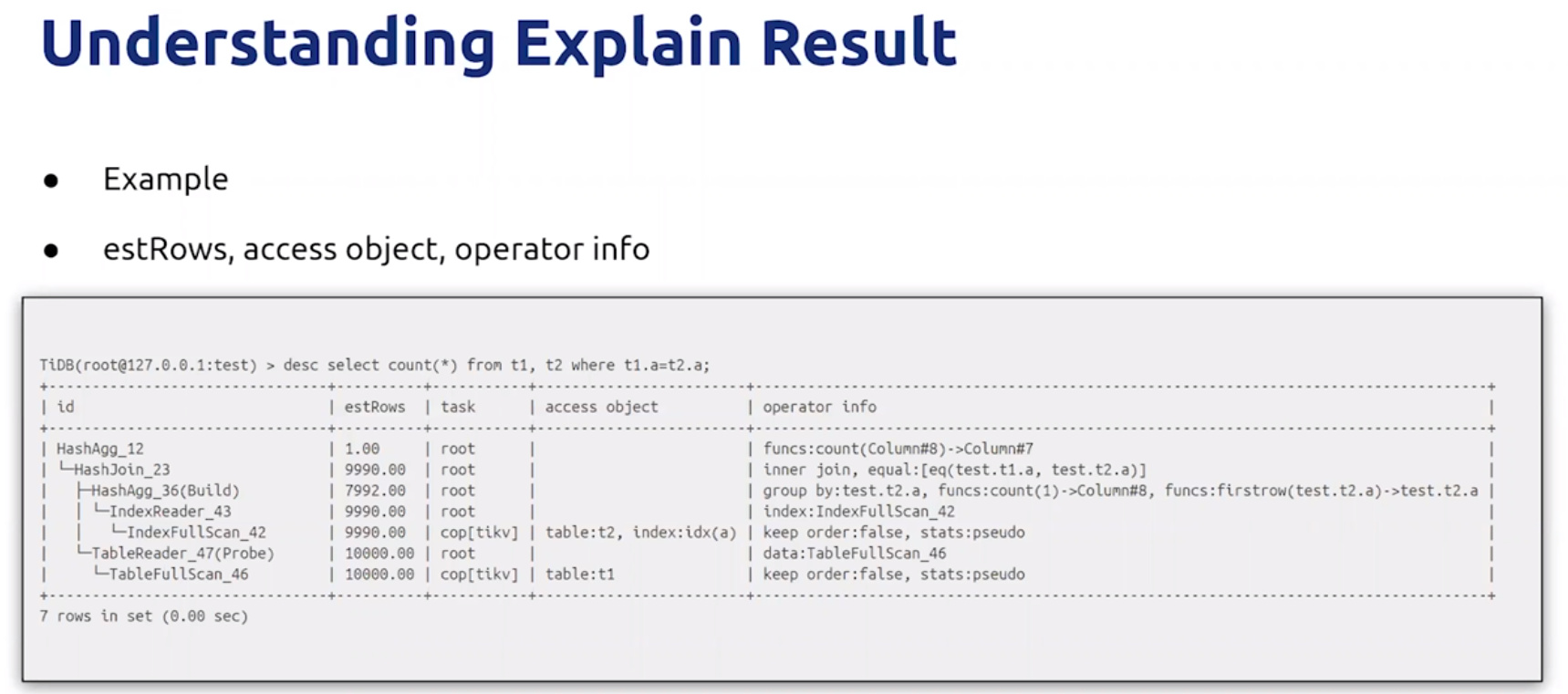

Query Optimizer
- 红色表示复杂规则

- Logical optimization
- Max Min Elimination

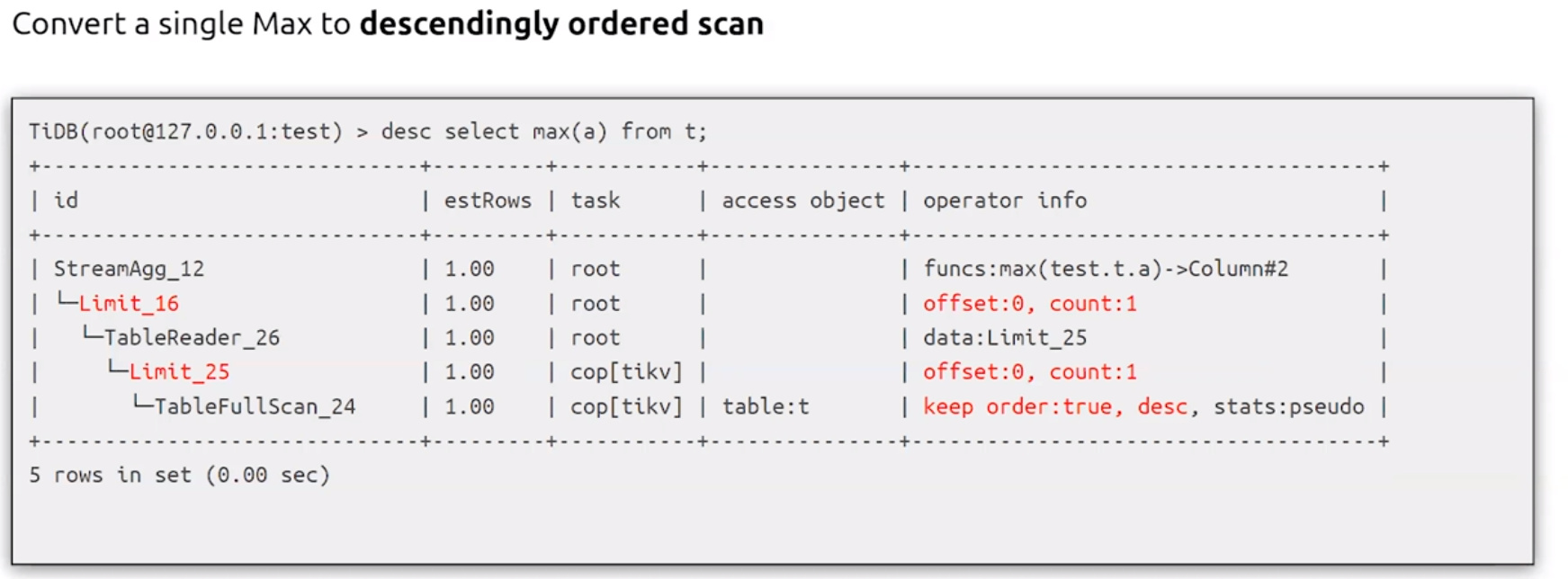
- Subquery Transformation
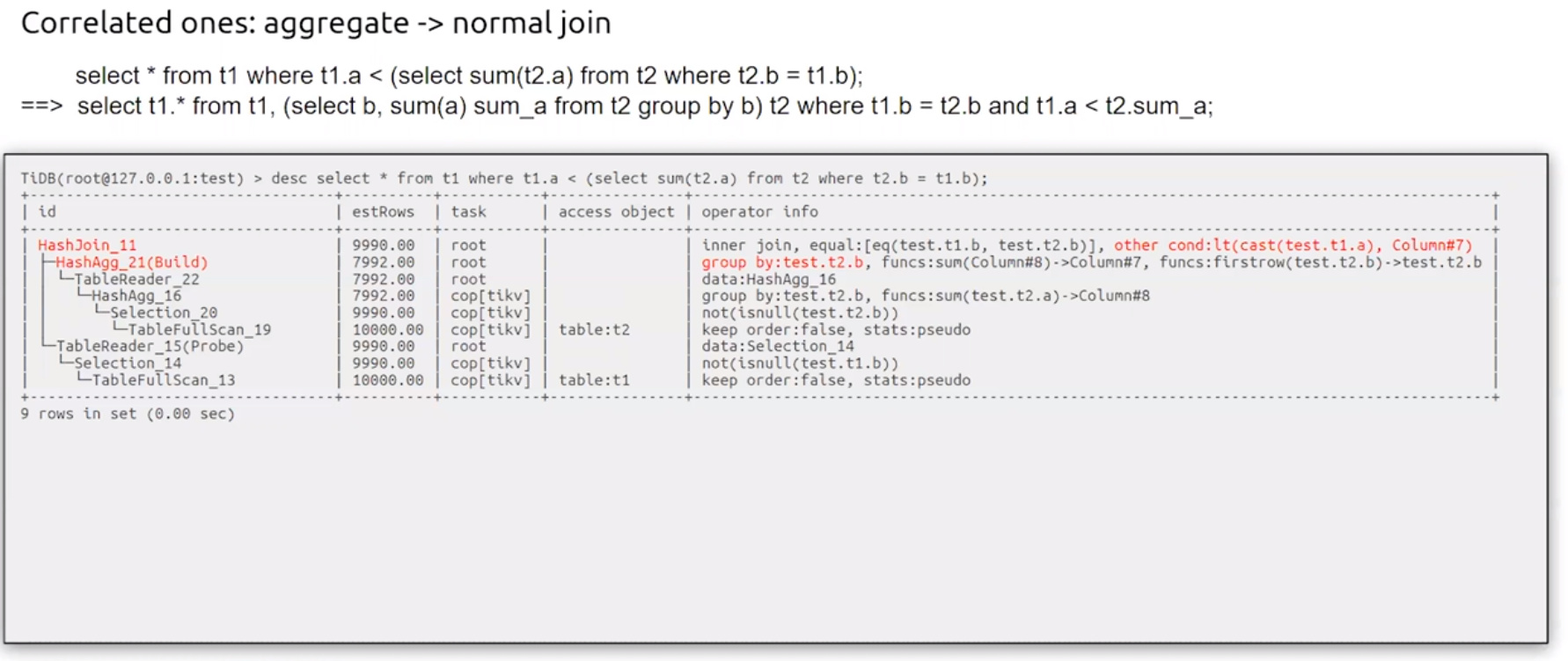

* 并不总是哪能够有优化效果
* 使用 optimiztion_rule_blacklist 关闭第一种
* 使用 tidb_opt_insubq_to_join_and_agg to 0 关闭第二种
* 子查询的列尽量不要有null,不然会进行笛卡尔积,损耗资源
- Aggregate Push Down
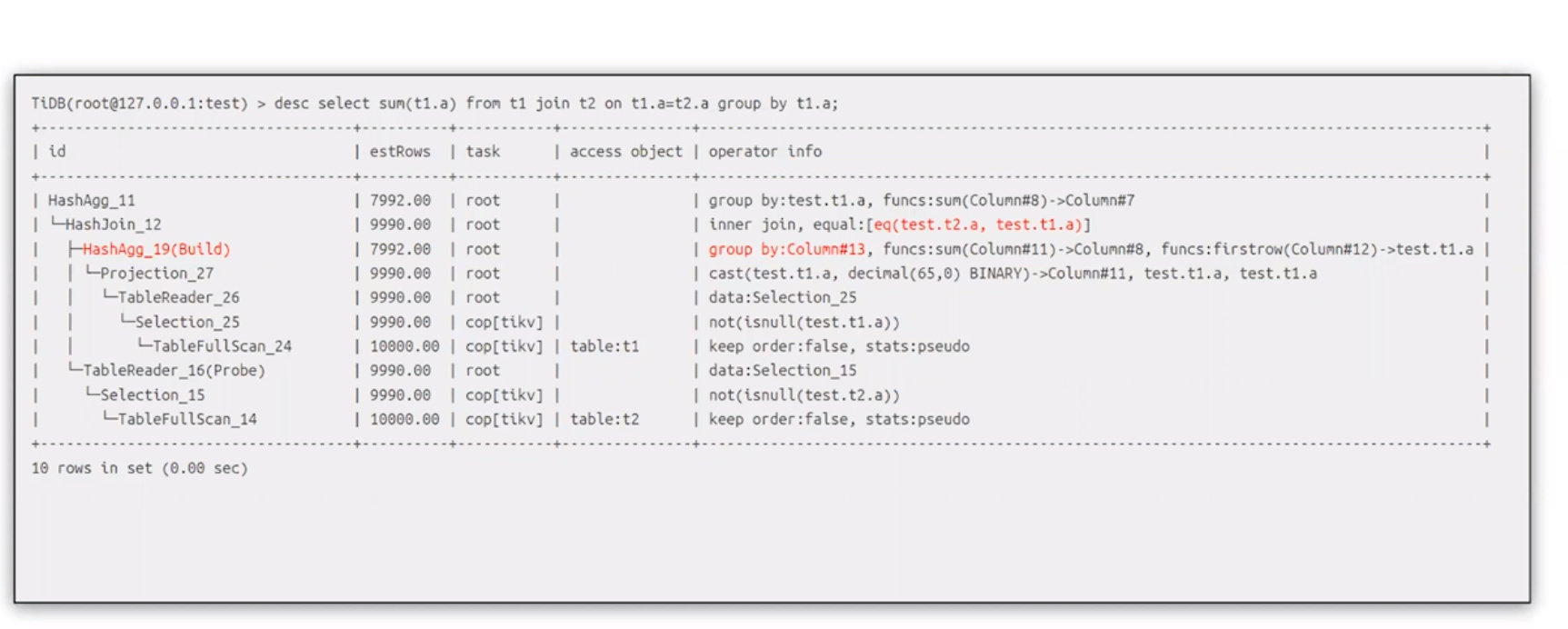
* 对于 join,显著减少join输入
* 对于 union,显著减少union输入
* 默认禁用,set tidb_opt_agg_push_down to 1 开启
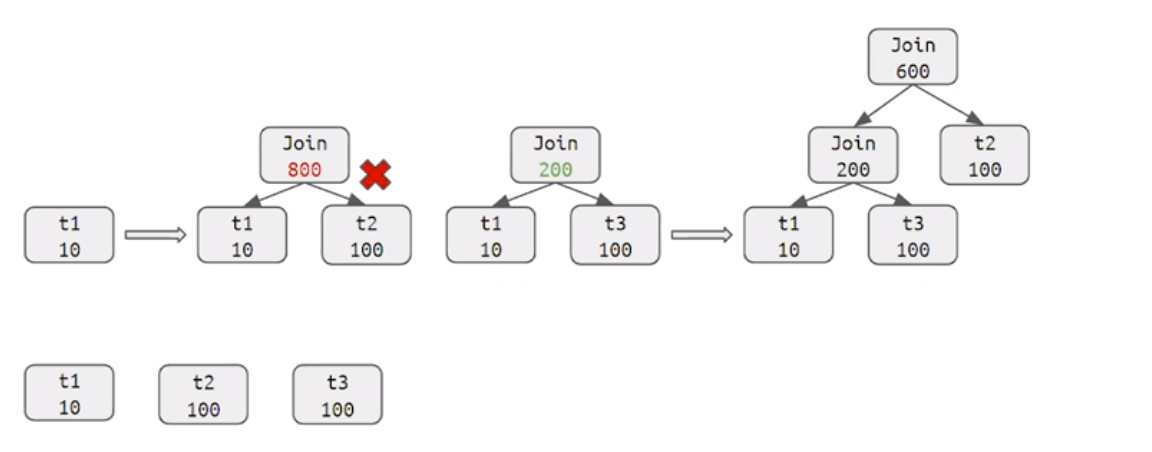
- Join Reorder
- 拿到join节点
- join足够小就使用DP算法
- 否则使用贪婪算法

- Physical optimization
- Soer → Join(t1.col1=t2.col1){t1,t2}
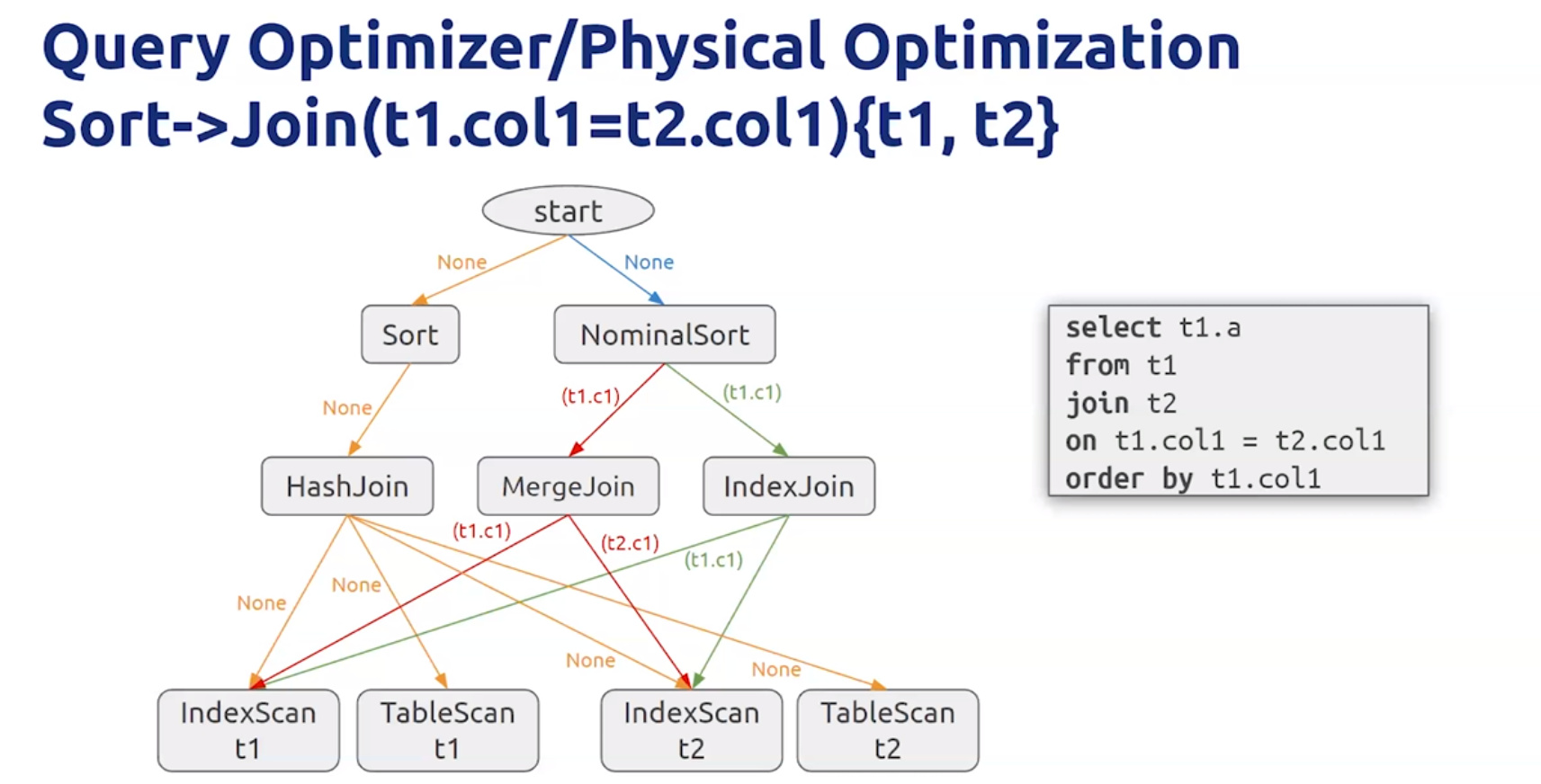
- 物理优化会影响性能
- 使用 Hints / SPM 来控制
- Index selection
- 选择错误
- 收集统计信息
- TiFlash 和 TiKV选择错误时 ,调节 tidb_opt_seek_factor
- 使用Hint/SPM
- 选择错误
Execution Tuning Guide
- Execution Engine
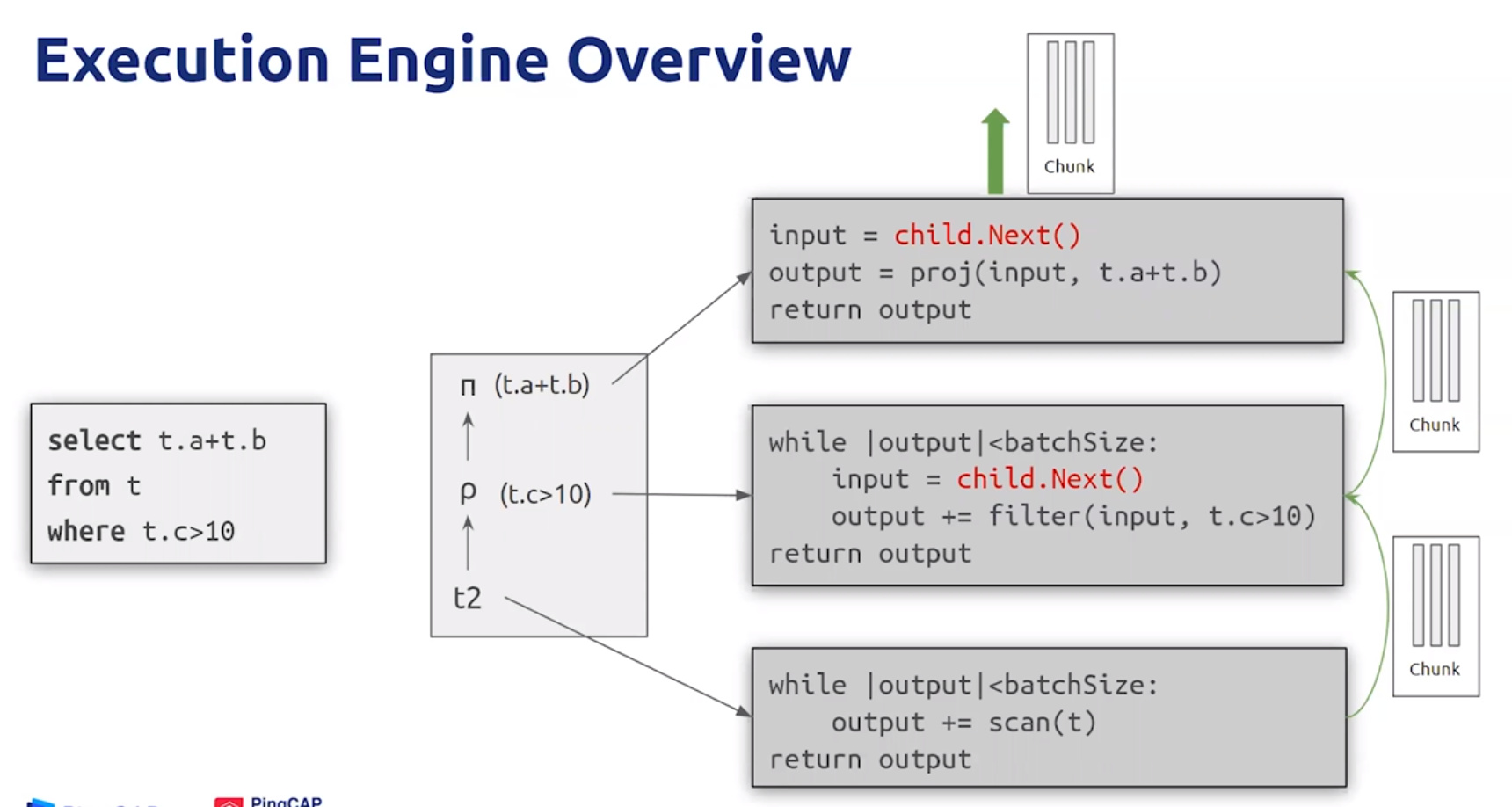
- 一组一组的读数据
- 算子并行化:Hash Join,Index Join,Hash Aggregate,etc.
- Hash Join
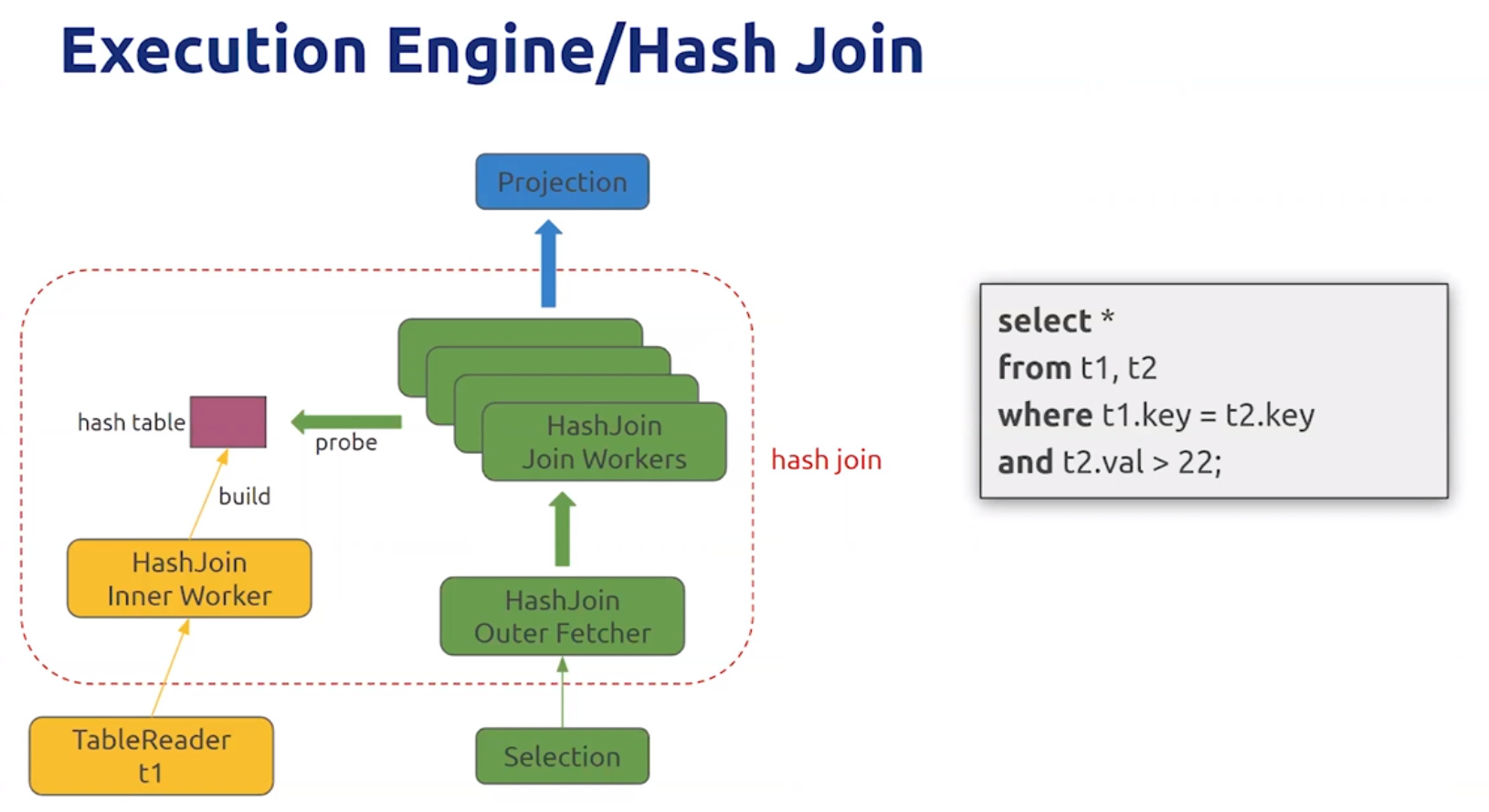
- tidb_hash_join_concurrency 控制 join work数量,默认为5
- Index Join
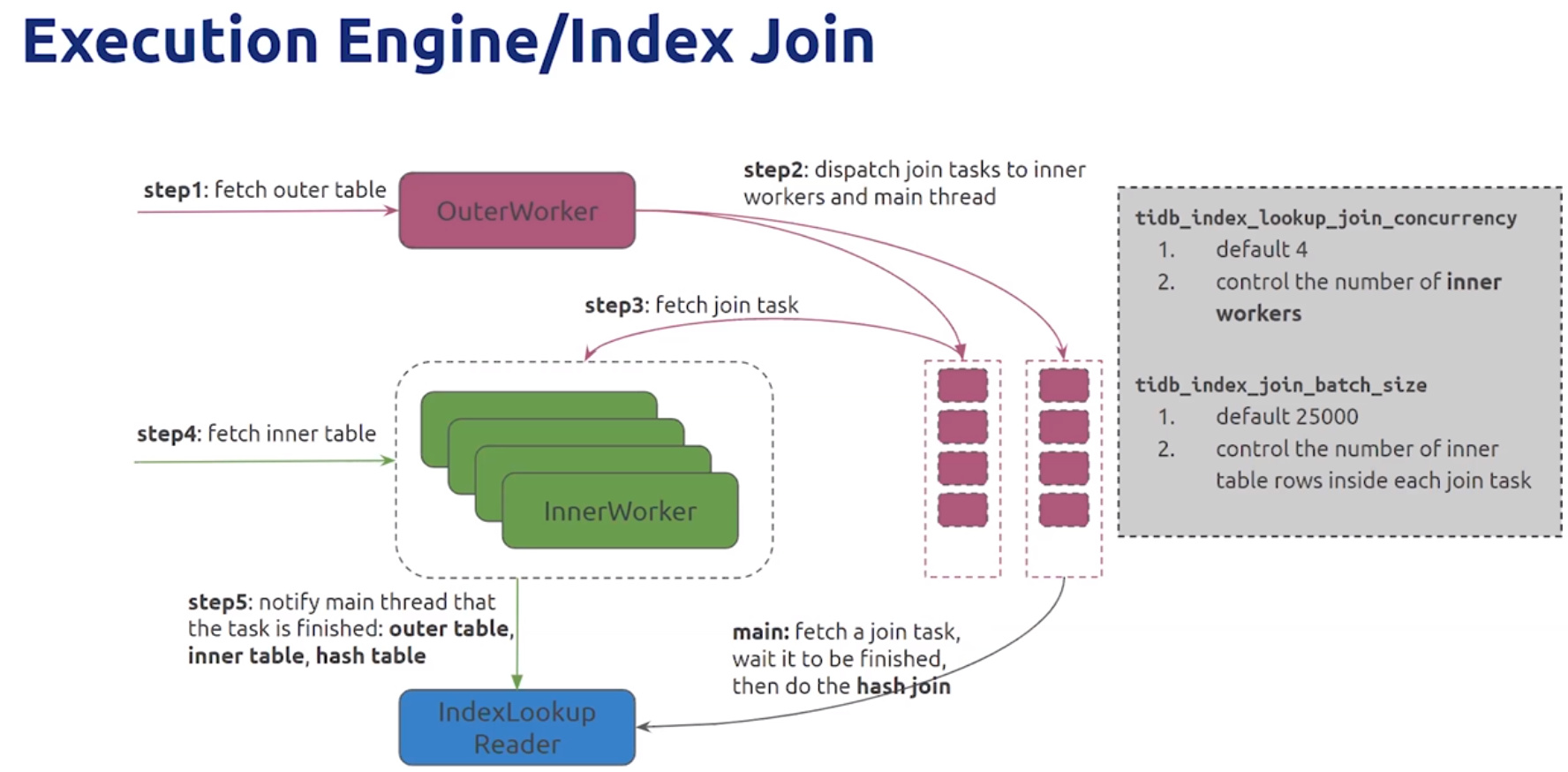
- tidb_index_lookup_join_concurrency: 默认为5,控制inner workers数量
- tidb_index_join_batch_size: 默认25000,不需过多改动
- Merge Join
- 单线程
- 数据需要按照join key 有序
- 内存消耗少
- NestedLoopApply
- 单线程
- 逐行
- 低效

- Hash Aggregate

- tidb_hashagg_final_concurrency,默认4个,控制 final workers数量
- tidb_hashagg_partial_concurrency,默认4个,控制partial workers数量
- Stream Aggregate
- 单线程
- 消耗内存少
- 数据需要按照key排序
- Index Lookup Reader
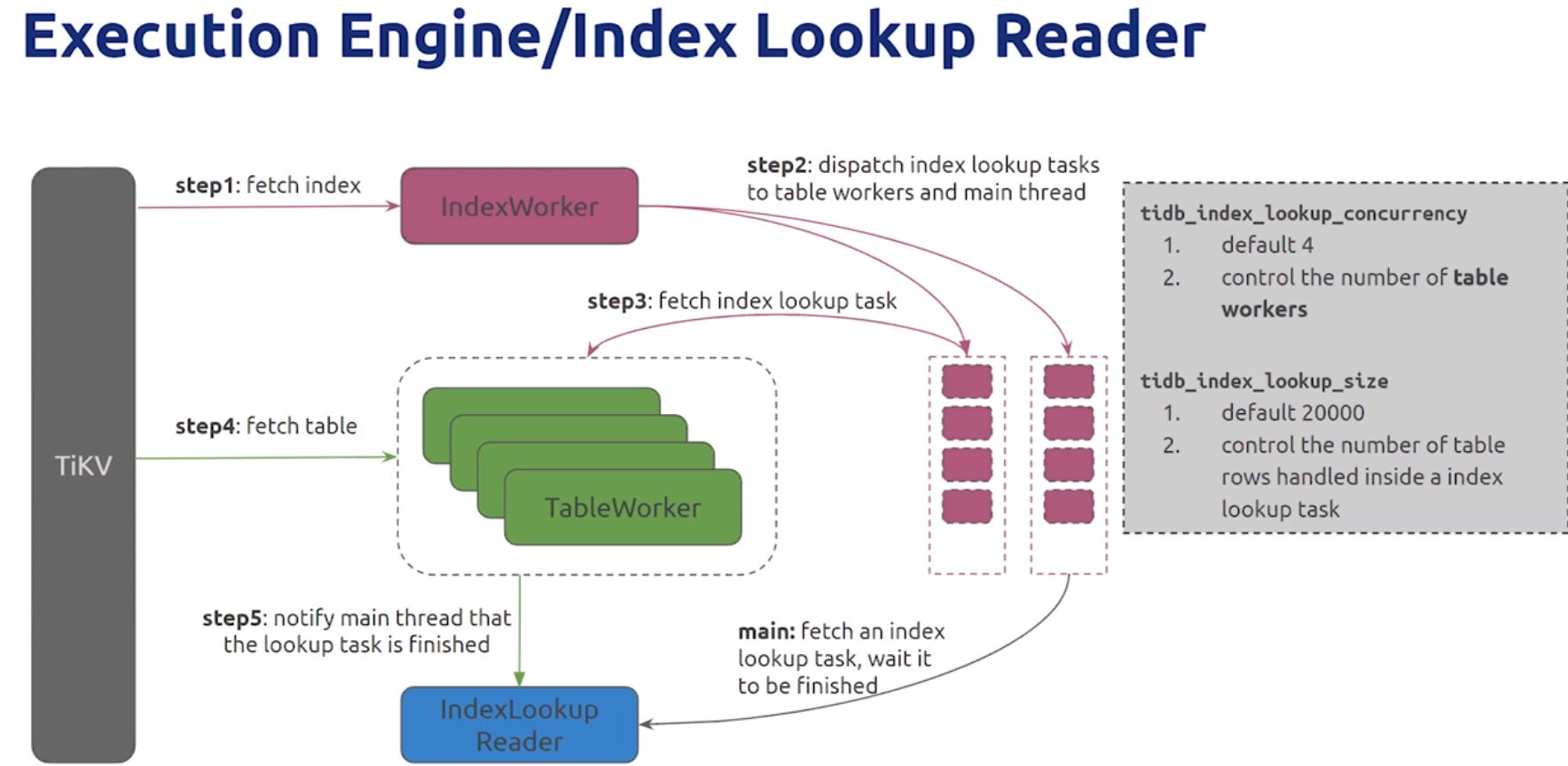
- tidb_index_lookup_concurrency,默认4个,控制table workers 数量
- tidb_index_lookup_size,默认20000
Control the execution plan
- Hint
- Index hint(use/force/igonre index),与mysql相似* 在表名后面使用
- 注释形式使用 (/ + HINT_NAME(arg1, arg2) /),在Select字段中
- SQL Plan Management
- 控制一组SQL,而不是针对某一句SQL
- CREATE BINDING syntax
- SHOW BINDING 查看所有BINDING
学习过程中遇到的问题或延伸思考:
- 问题 1:
- 问题 2:
- 延伸思考 1:
- 延伸思考 2: