为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:v4.0.8
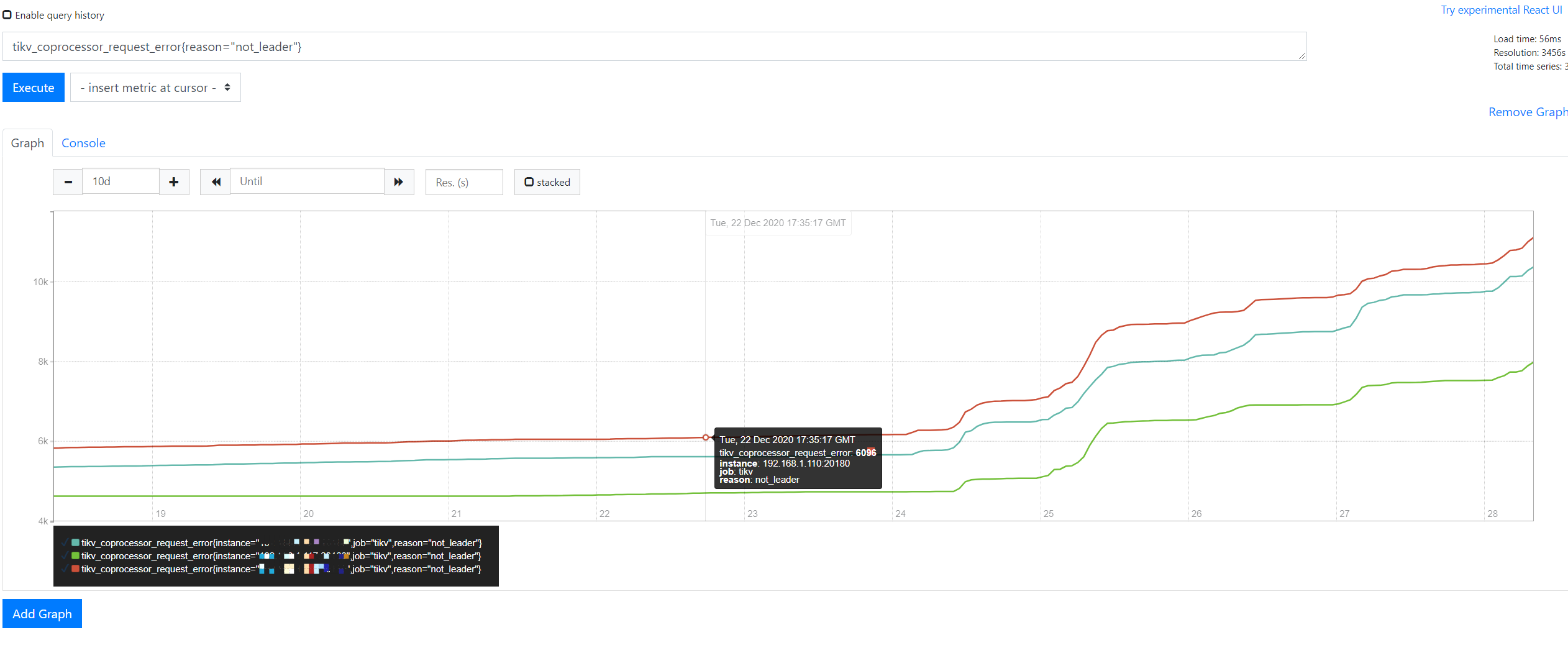
- 【问题描述】:tikv持续出现 tikv_coprocessor_request_error{reason=“not_leader”} 报错
上周四进行了生产环境升级,先创建了一个数据库,创建表时由于sql格式写的不正确报错,随后删掉了新建的数据库后重新创建数据库并执行修改正确的sql语句创建表,执行成功。
这几天tidb数据库能正常提供服务,但是监控指标出现了大量的 tikv_coprocessor_request_error{reason=“not_leader”} 报错,并且 tikv 的 cpu使用率下降了很多,麻烦帮忙看看怎么处理这个问题,谢谢
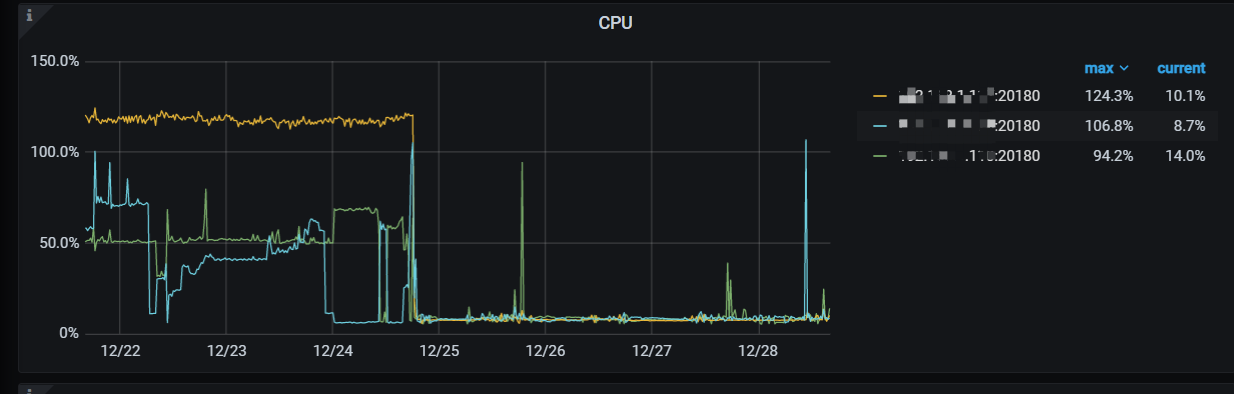
tikv的cpu使用率,升级后下降了很多
可以参考下这个回复,not leader 属于正常的报错情况,如果对业务没有影响的话,可以忽略。
目前看没有影响业务,但是升级之前这个错误指标很稳定,升级后这个 not_leader 报错持续增加,总不能任由这个错误一直持续吧。。 。
。
而且观察coprocessor 的qps也降了很多。。
升级之前是什么版本?
能不能找一些 tidb.log 以及 tikv.log 中关于 not leader 的部分日志看下
tikv-logs.zip (53.0 KB) tidb-logs.zip (25.2 KB)
日志已上传,这些日志都包含not leader的部分
是从什么版本升级到 v4.0.8 版本的?麻烦提供下这个信息,方便确认是否是什么改进导致的影响。
版本没有变化,上周四执行的操作只是我上面所说的业务数据库和表操作,没有对 tidb 集群做任何变更。
那可能是之前库中的数据被删除之后,后续因为 region merge 以及调度的原因,导致 tidb-server 中缓存的 region cache 过期,region 对应的 leader 已经调度到别的 store 节点上了,所以 tidb 在访问 tikv 的时候会有 not leader 的信息。
可以考虑重启一下 tidb-server 节点清理下 tidb-server 节点上的 region cache 信息,让 tidb-server 重新获取最新的 region 信息。
如果重启 tidb-server 之后还是没有改善,可以提供一下 PD 相关的监控看下:
导出监控步骤:
- 打开监控面板,选择监控时间
- 打开 Grafana 监控面板(先按
d 再按 E 可将所有 Rows 的 Panels 打开,需等待一段时间待页面加载完成)
-
https://metricstool.pingcap.com/ 使用工具导出 Grafana 数据为快照
PD_2020-12-30T03_47_05.730Z.json (2.1 MB)
昨晚重启了tidb-server后问题依旧存在,我已经导出了1周的pd监控数据。
另外,我在tidb日志中看到很多client去操作不存在的database,不知道是否是这个原因影响的?
这些 client 操作不存在的 database 是应用的连接么?如果可以的话,可以修复一下这个,排除这个的影响。
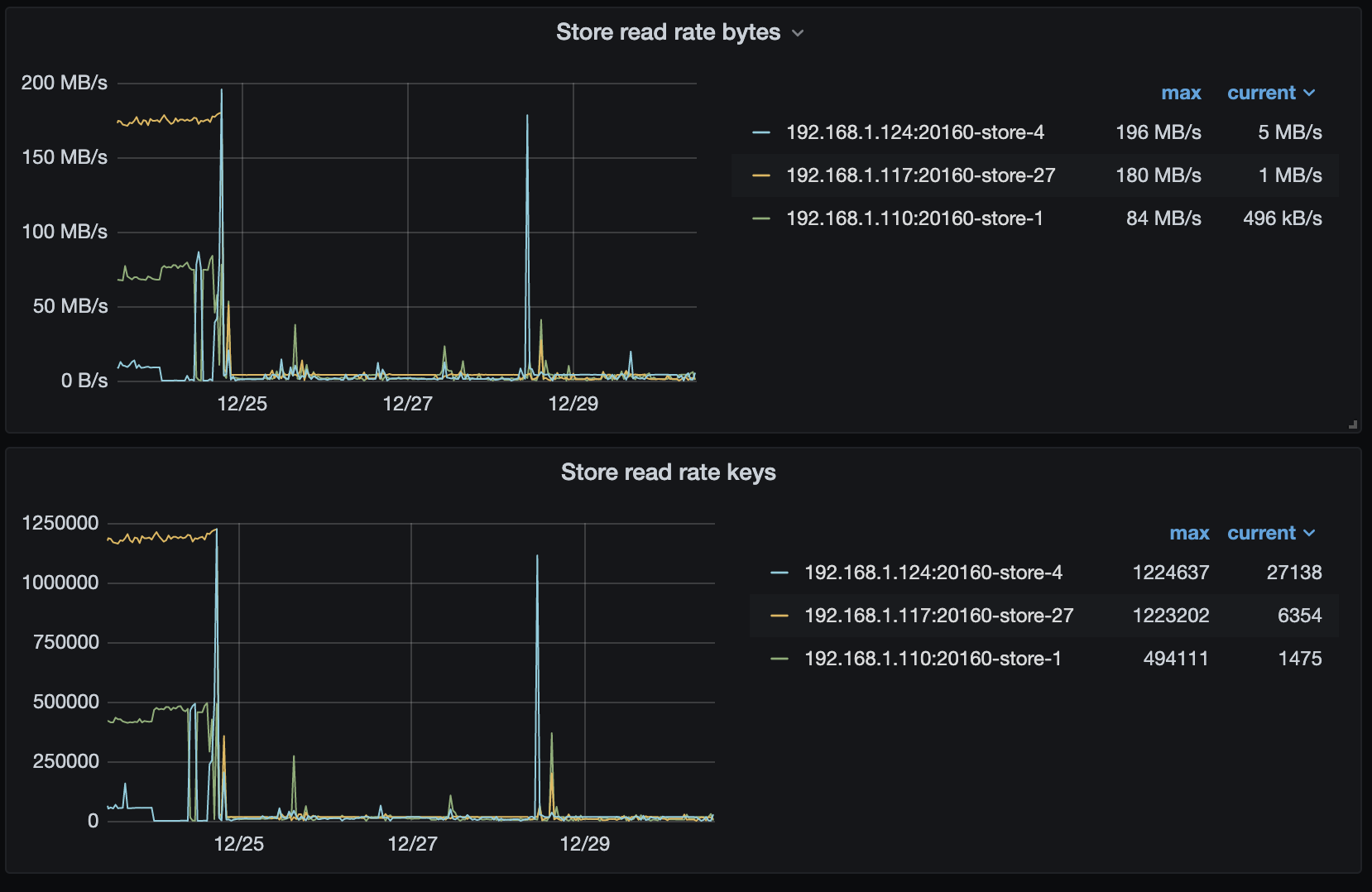
看了 PD 的监控,没有发现 leader 频繁调度的情况。不过从监控这边看到 25 号之前,各个节点上的读取数据量大很多。
可以的话,麻烦再导一下 Overview 以及 TiDB 和 TiKV-Details 的监控看下
client 操作不存在的 database 是应用连接的,我们内部看看这个问题。
25号之前使用量大,是应为25号升级了应用,优化了查询。
tivk和tidb监控如下:
tidb-tikv-grafana.zip (1.2 MB)