课程名称:3.6.1 Data migration tools introduction (TiDB 数据迁移工具介绍)
学习时长:15min
课程收获:
使用数据迁移工具将数据迁移到 TiDB 中,包括逻辑导出导入,物理加载数据到 TiDB,实时同步 mysql 数据到 TiDB。
课程内容:
1.Dumpling
- Dumpling 简介
Dumpling是使用 go 开发的数据备份工具,项目地址可以参考Dumpling。
Dumpling 的更多具体用法可以使用 --help 选项查看,或者查看 Dumpling 主要选项表。
使用 Dumpling 时,需要在已经启动的集群上执行导出命令。本文假设在127.0.0.1:4000有一个 TiDB 实例,并且这个 TiDB 实例中有无密码的 root 用户。
Dumpling 包含在 tidb-toolkit 安装包中,可在此下载。 - 与Mydumper相比Dumpling 的改进
- 支持多种数据导出形式,sql和csv
- 支持全新的表过滤,数据筛选更便利
- TiDB更多的优化
- 支持配置TiDB单条SQL的内存限制,避免OOM
- 4.0以上版本自动支持调整TiDB的GC时间
- 使用TiDB的隐藏列 _tidb_rowid 优化单表内存数据库的并发导出性能
- 支持设置 tidb_snapshot指定导出时间点,从而保持数据的一致性(而不是通过 flush tables with read lock实现)

2.TiDB Lightning
- TiDB Lightning 简介
TiDB Lightning 是一个将全量数据高速导入到 TiDB 集群的工具,可在此下载。
TiDB Lightning 有以下两个主要的使用场景:一是大量新数据的快速导入;二是全量备份数据的恢复。目前,Lightning 支持 Dumpling 或 CSV 输出格式的数据源。你可以在以下两种场景下使用 Lightning:- 迅速 导入 大量新 数据。
- 恢复所有备份数据。
TiDB Lightning 整体架构
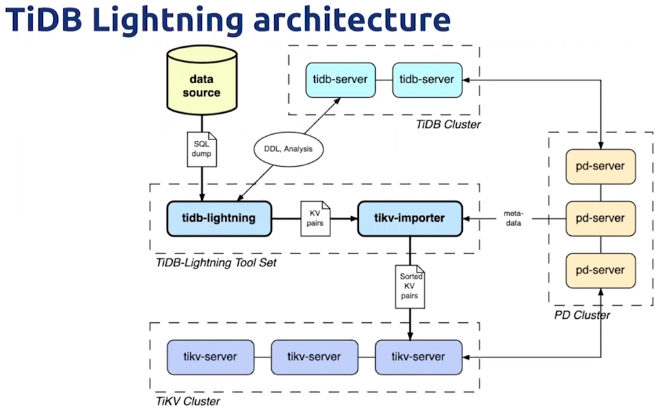
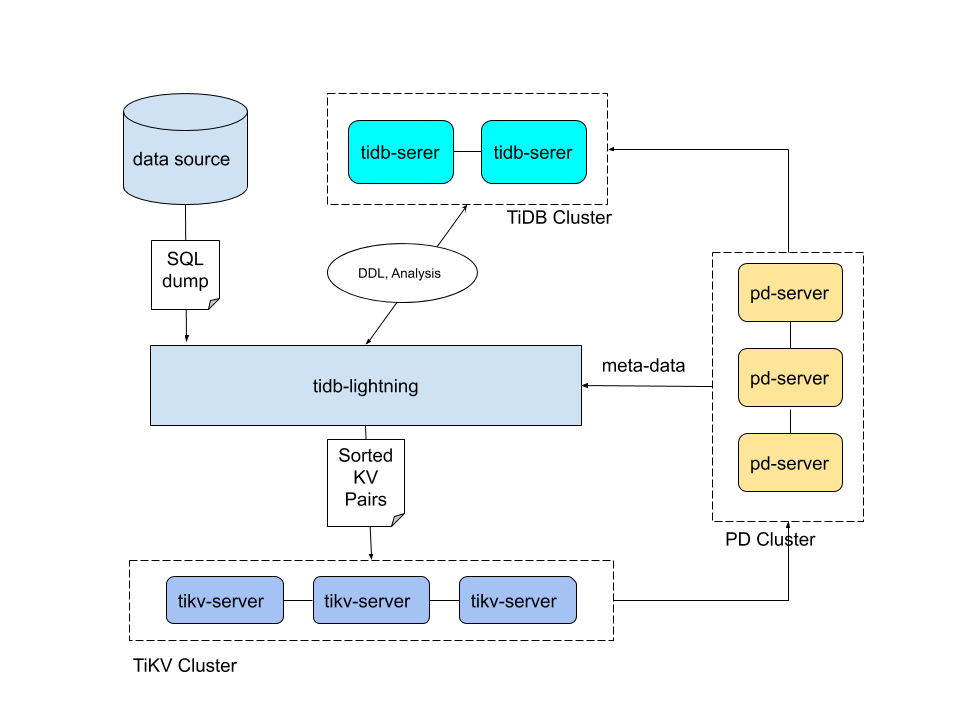
TiDB Lightning 整体工作原理如下:
- 在导数据之前,
tidb-lightning会自动将 TiKV 集群切换为“导入模式” (import mode),优化写入效率并停止自动压缩。 -
tidb-lightning会在目标数据库建立架构和表,并获取其元数据。 - 每张表都会被分割为多个连续的 区块 ,这样来自大表 (200 GB+) 的数据就可以用增量方式并行导入。
-
tidb-lightning会为每一个区块准备一个“引擎文件 (engine file)”来处理键值对。tidb-lightning会并发读取 SQL dump,将数据源转换成与 TiDB 相同编码的键值对,然后将这些键值对排序写入本地临时存储文件中。 - 当一个引擎文件数据写入完毕时,
tidb-lightning便开始对目标 TiKV 集群数据进行分裂和调度,然后导入数据到 TiKV 集群。引擎文件包含两种: 数据引擎 与 索引引擎 ,各自又对应两种键值对:行数据和次级索引。通常行数据在数据源里是完全有序的,而次级索引是无序的。因此,数据引擎文件在对应区块写入完成后会被立即上传,而所有的索引引擎文件只有在整张表所有区块编码完成后才会执行导入。 - 整张表相关联的所有引擎文件完成导入后,
tidb-lightning会对比本地数据源及下游集群的校验和 (checksum),确保导入的数据无损,然后让 TiDB 分析 (ANALYZE) 这些新增的数据,以优化日后的操作。同时,tidb-lightning调整AUTO_INCREMENT值防止之后新增数据时发生冲突。表的自增 ID 是通过行数的 上界 估计值得到的,与表的数据文件总大小成正比。因此,最后的自增 ID 通常比实际行数大得多。这属于正常现象,因为在 TiDB 中自增 ID 不一定是连续分配的。 - 在所有步骤完毕后,
tidb-lightning自动将 TiKV 切换回“普通模式” (normal mode),此后 TiDB 集群可以正常对外提供服务。
如果需要导入的目标集群是 v3.x 或以下的版本,需要使用 Importer-backend 来完成数据的导入。在这个模式下, tidb-lightning 需要将解析的键值对通过 gRPC 发送给 tikv-importer 并由 tikv-importer 完成数据的导入; TiDB Lightning 还支持使用 TiDB-backend 作为后端导入数据。TiDB-backend 使用和 Loader 类似, tidb-lightning 将数据转换为 INSERT 语句,然后直接在目标集群上执行这些语句。
3.TiDB Data Migration
-
简介
TiDB Data Migration (DM) 是一体化的数据迁移任务管理平台,支持从 MySQL 或 MariaDB 到 TiDB 的全量数据迁移和增量数据复制。使用 DM 工具有利于简化错误处理流程,降低运维成本。 -
DM功能
支持表路由,将上游库表迁移到指定下游的库表(不同库表名字)
黑白名单过滤库表
binlog event 过滤
DM的在线DDL功能
分库分表的合并迁移功能 -
DM2.0架构
DM 主要包括三个组件:DM-master,DM-worker 和 dmctl。


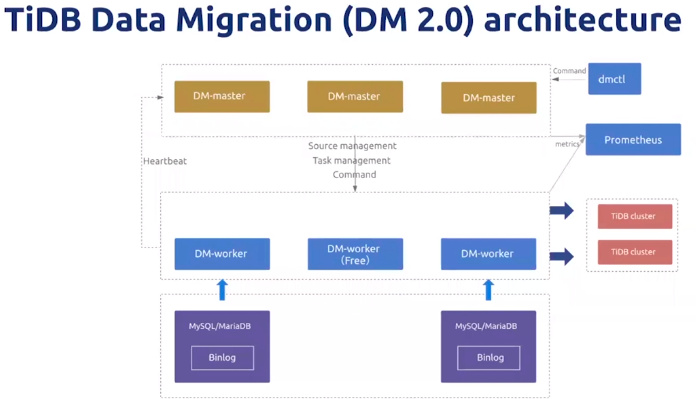
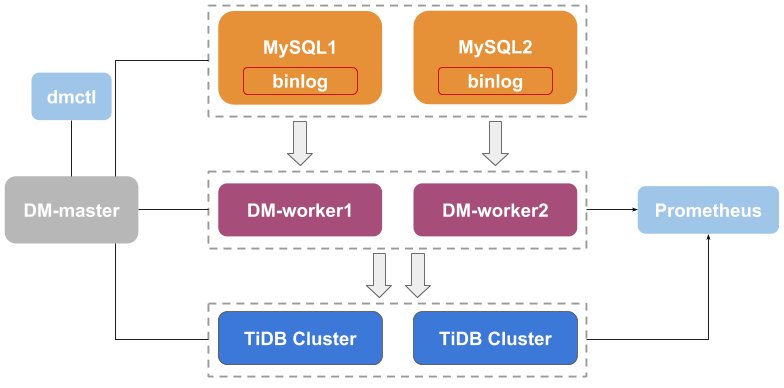
DM-master 负责管理和调度数据迁移任务的各项操作。
- 保存 DM 集群的拓扑信息
- 监控 DM-worker 进程的运行状态
- 监控数据迁移任务的运行状态
- 提供数据迁移任务管理的统一入口
- 协调分库分表场景下各个实例分表的 DDL 迁移
DM-worker 负责执行具体的数据迁移任务。
- 将 binlog 数据持久化保存在本地
- 保存数据迁移子任务的配置信息
- 编排数据迁移子任务的运行
- 监控数据迁移子任务的运行状态
DM-worker 启动后,会自动迁移上游 binlog 至本地配置目录(如果使用 DM-Ansible 部署 DM 集群,默认的迁移目录为<deploy_dir>/relay_log)。关于 relay log,详见 DM Relay Log。
dmctl 是用来控制 DM 集群的命令行工具。
- 创建、更新或删除数据迁移任务
- 查看数据迁移任务状态
- 处理数据迁移任务错误
- 校验数据迁移任务配置的正确性
学习过程中遇到的问题或延伸思考:
- 问题 1:
- 问题 2:
- 延伸思考 1:
- 延伸思考 2: