课程名称:301+ 3.7TiDB 监控与调优(2)
学习时长:
90
课程收获:
- TiDB Server 优化
- TiKV Server 优化
- 性能调优 - 故障排查实战
课程内容:
TiDB Server 优化
最优的参数配置需要在考虑实际情况性能测试的结果得出
操作系统参数
CPU ,保持性能模式,numa节点绑定

mem,关闭通明大页,THP关闭,数据访问模式通常稀疏内存访问不是连续访问的模式

提高内存回收效率
IO
调度模式更改为NOOP

NOATIME
TIDB系统参数
set的参数 global,
- concurrency
并发在系统负载较低的时候可以提高性能,但是在资源紧张时候反而会降低性能
analyze通常会花费很长时间,提高并发可能导致影响在线业务
算子的并发度调整,index join的结果集通常比hashjoin的小很多
控制index更新的并发度,因为会影响在线业务延时
- batch size TIDB中的数据处理是以batch为单位处理的,受到内存的限制,过多申请造成内存压力较大
init 第一批的结果,如果发现返回还有更多数据,会按照max申请。AP和TP的设置不同。单批次越大,资源占用越多
max
- limit 限流值,限流较低会导致资源无法有效利用,但是过大会加大TIKV的资源占用。
乐观事务重试次数过多会导致事物完成时间更长,V4.0默认使用悲观事务
- backoff 可重试业务的重试前等待





tIDB 配置参数
配置文件中的配置参数
- performance 设置单独低优先级TIDB server 用来OLAP业务,降低对OLTP业务的影响
限制单个大事务提交的并发度,可以提高大事务成功的概率
- tikv client,使用多连接提高吞吐,但是过犹不及。不同workload使用不同并发更好
- prepare plan cache,占用内存节省CPU ,空间换时间,而且复杂查询中不同参数可能导致计划失效。


TiKV Server 优化
KV调用下层
事务层基于2PC
consensus 共识层为RAFT replication log
两个存储引擎,都是基于rocksDB ,一个用来存放raftlog 一个存放数据
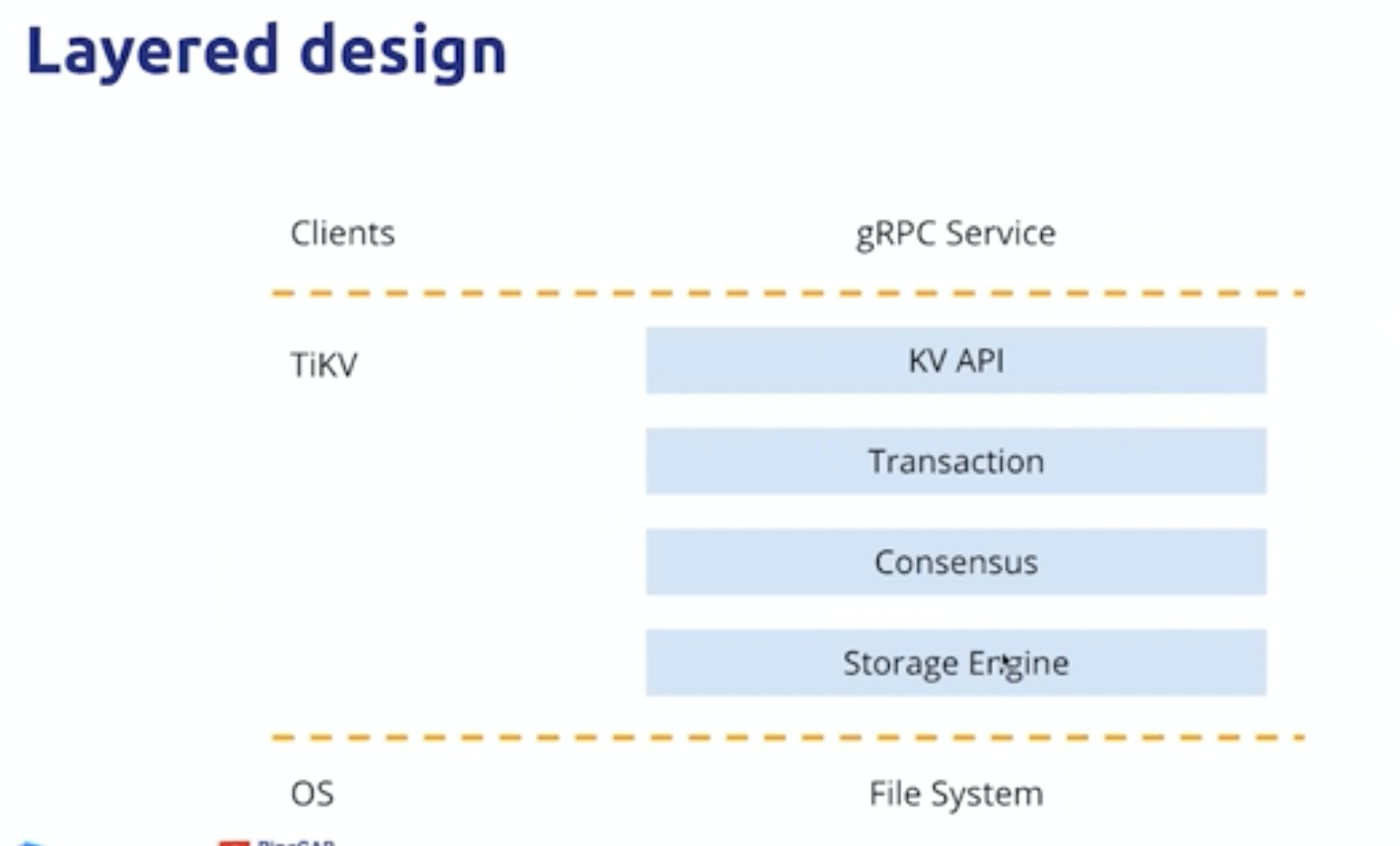
模块层
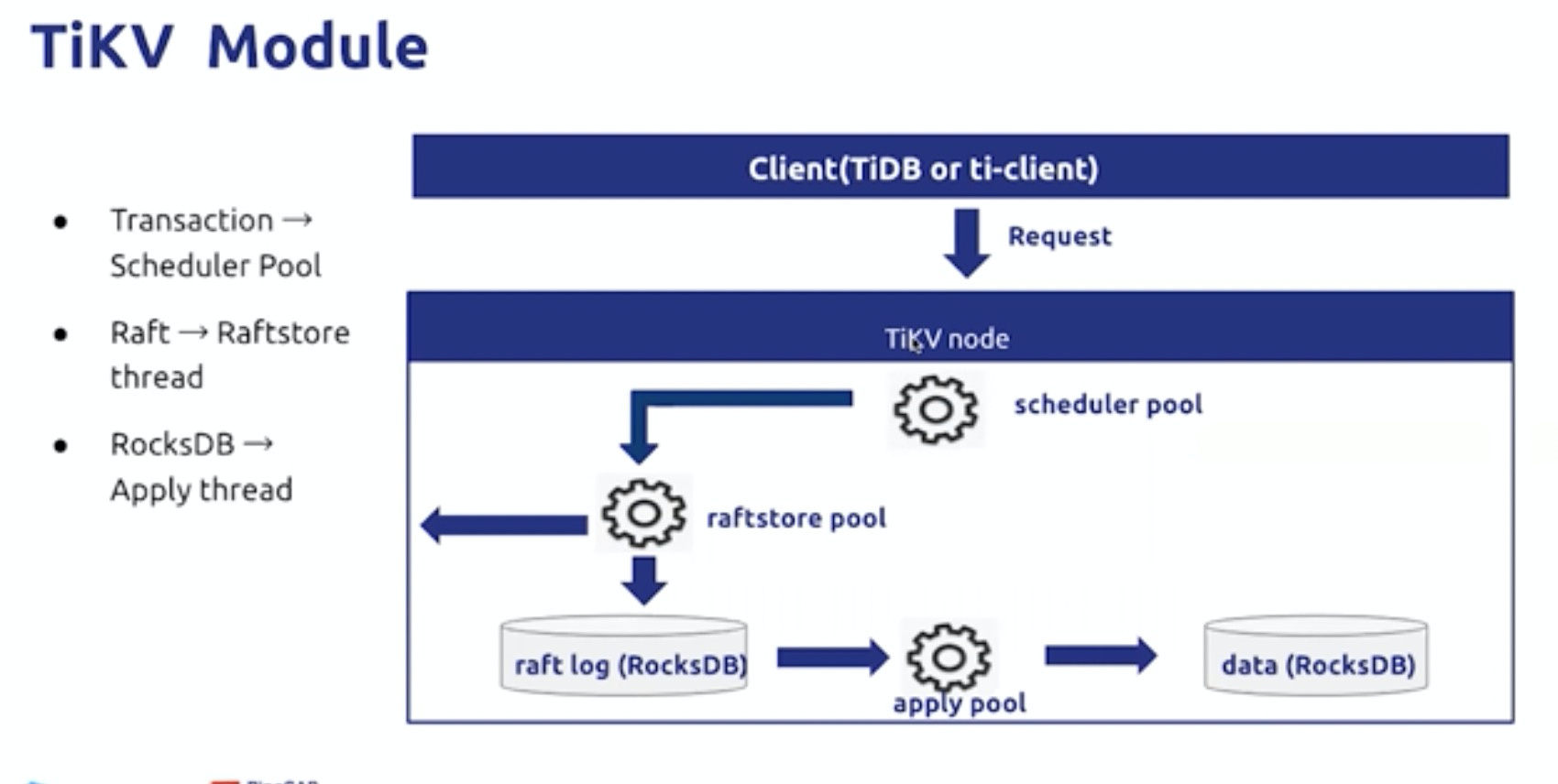
写请求
按照数据流动方向,分层向下,分析各个线程池是否已经成为瓶颈,80%是建议调整的基线。最终到达IO层的瓶颈(io util,io load)以及CPU Load 。调整压缩级别可以使用CPU 换区IO性能。
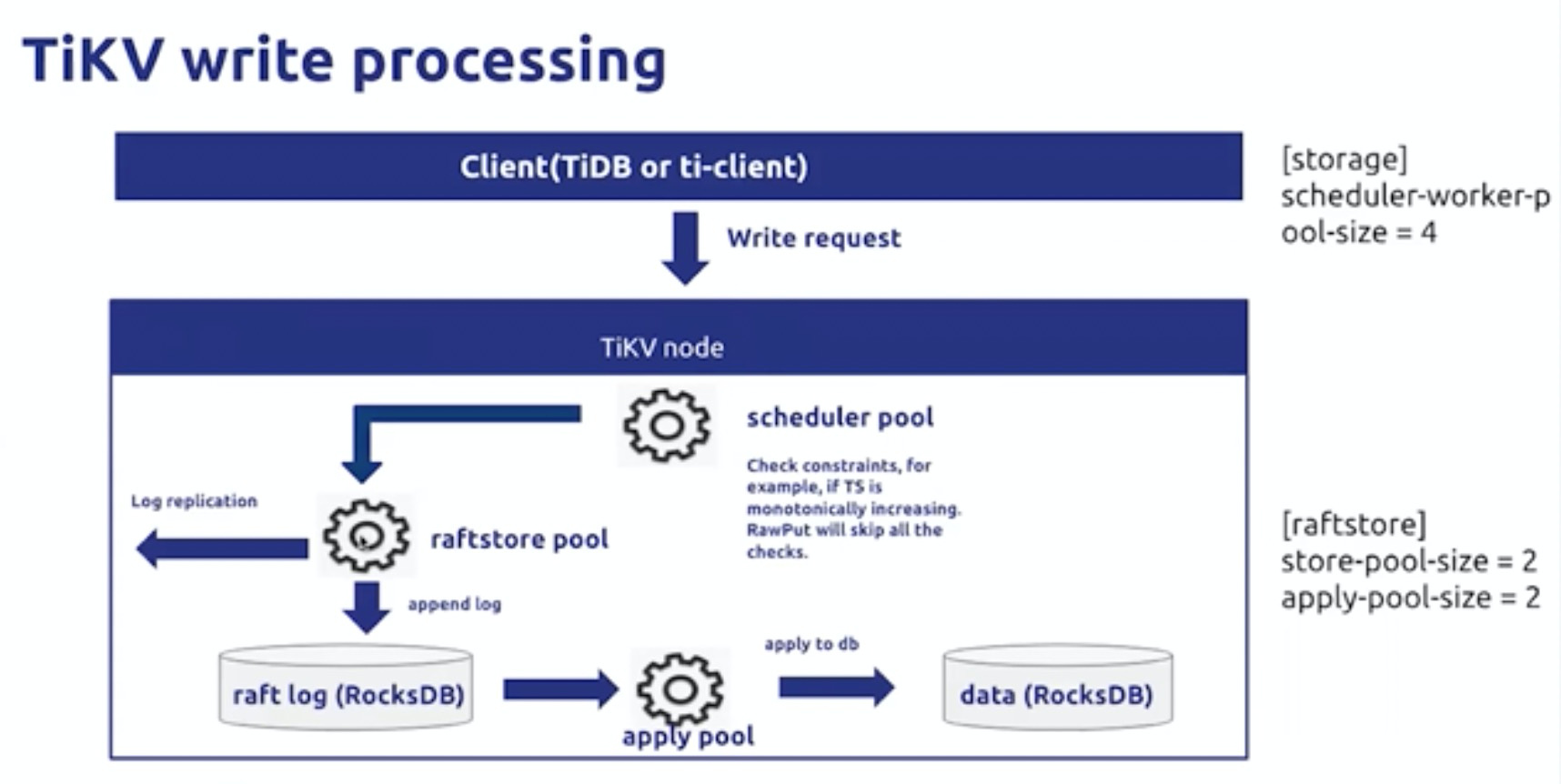
rocksDB 的store考虑,

还需要考虑网络延时,影响RAFT达成一致的效率
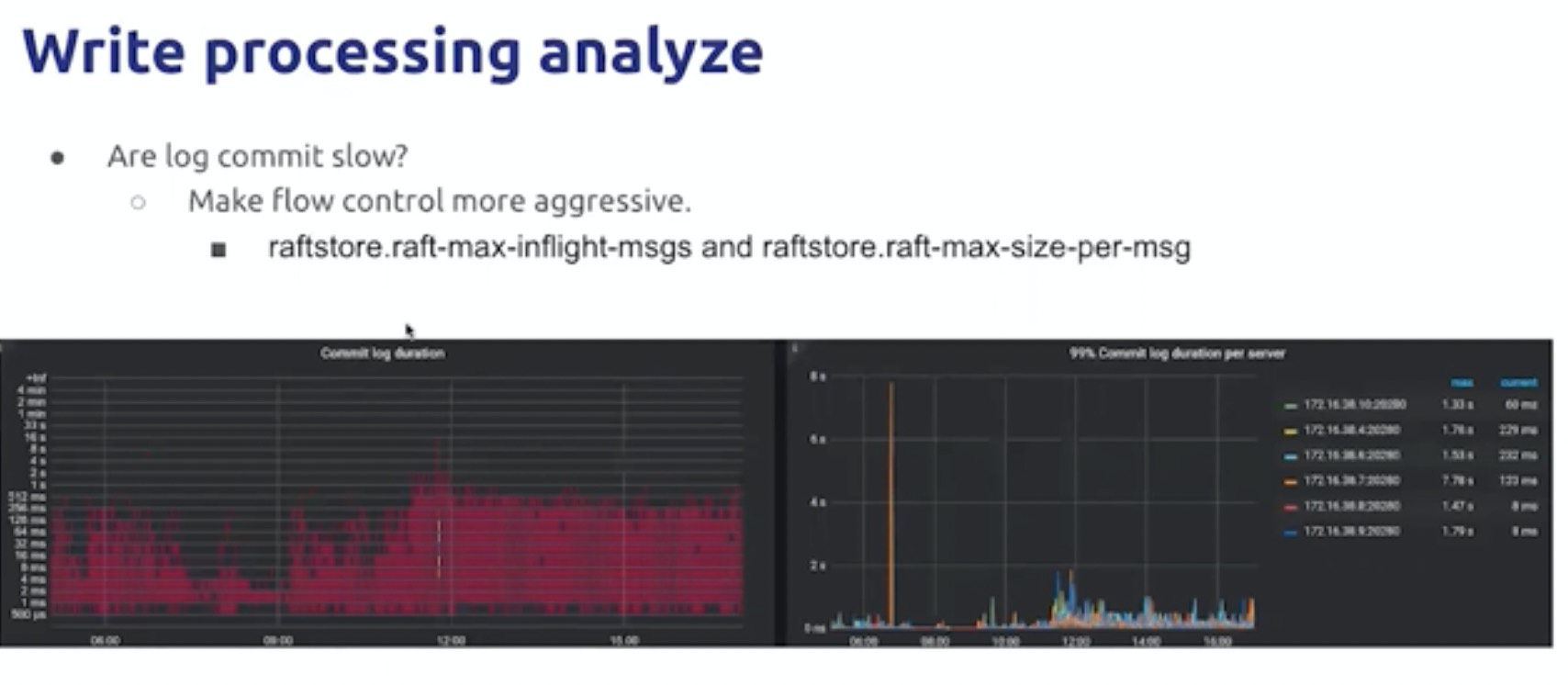
rocksDB流控和网络延迟
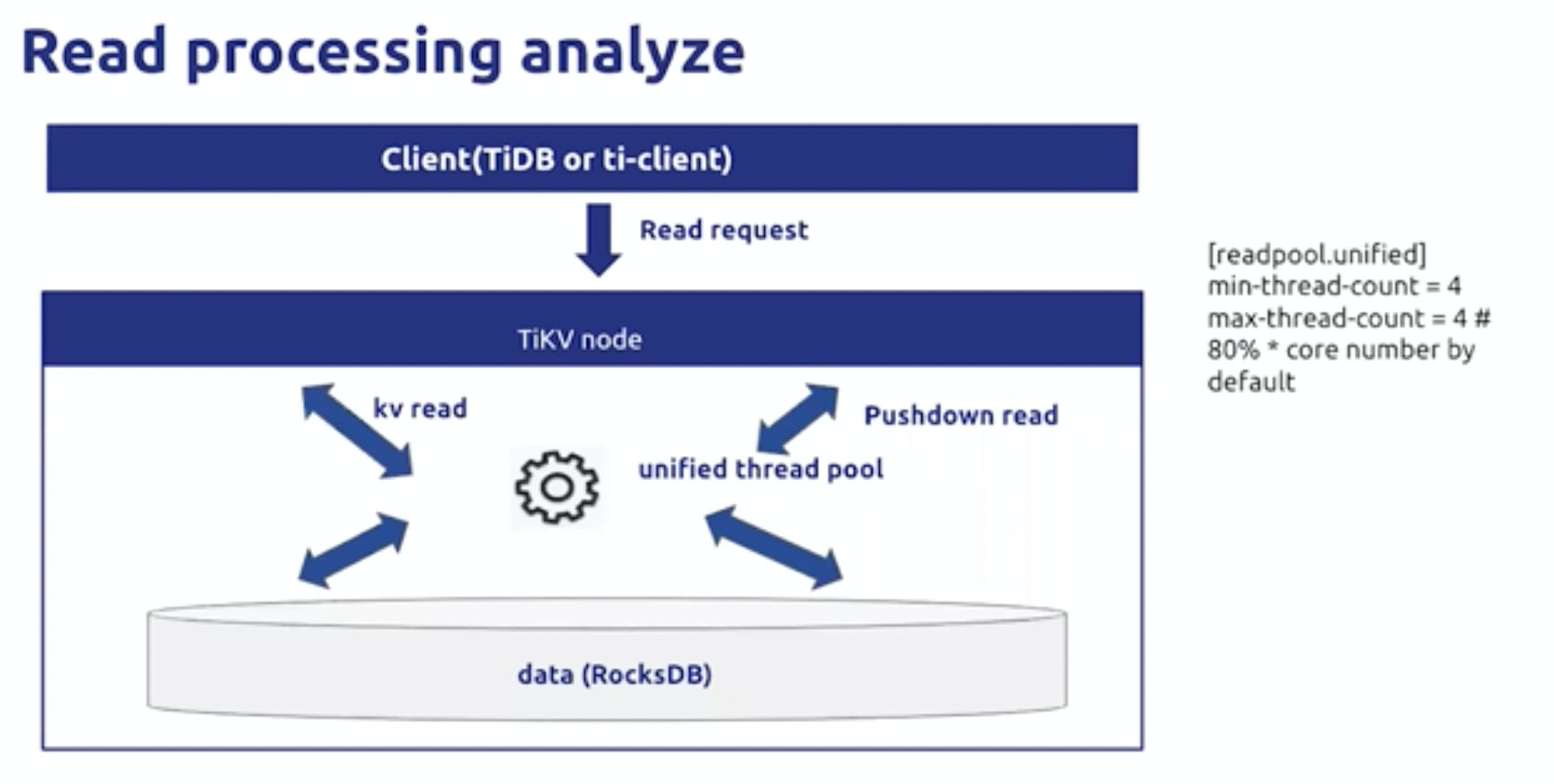
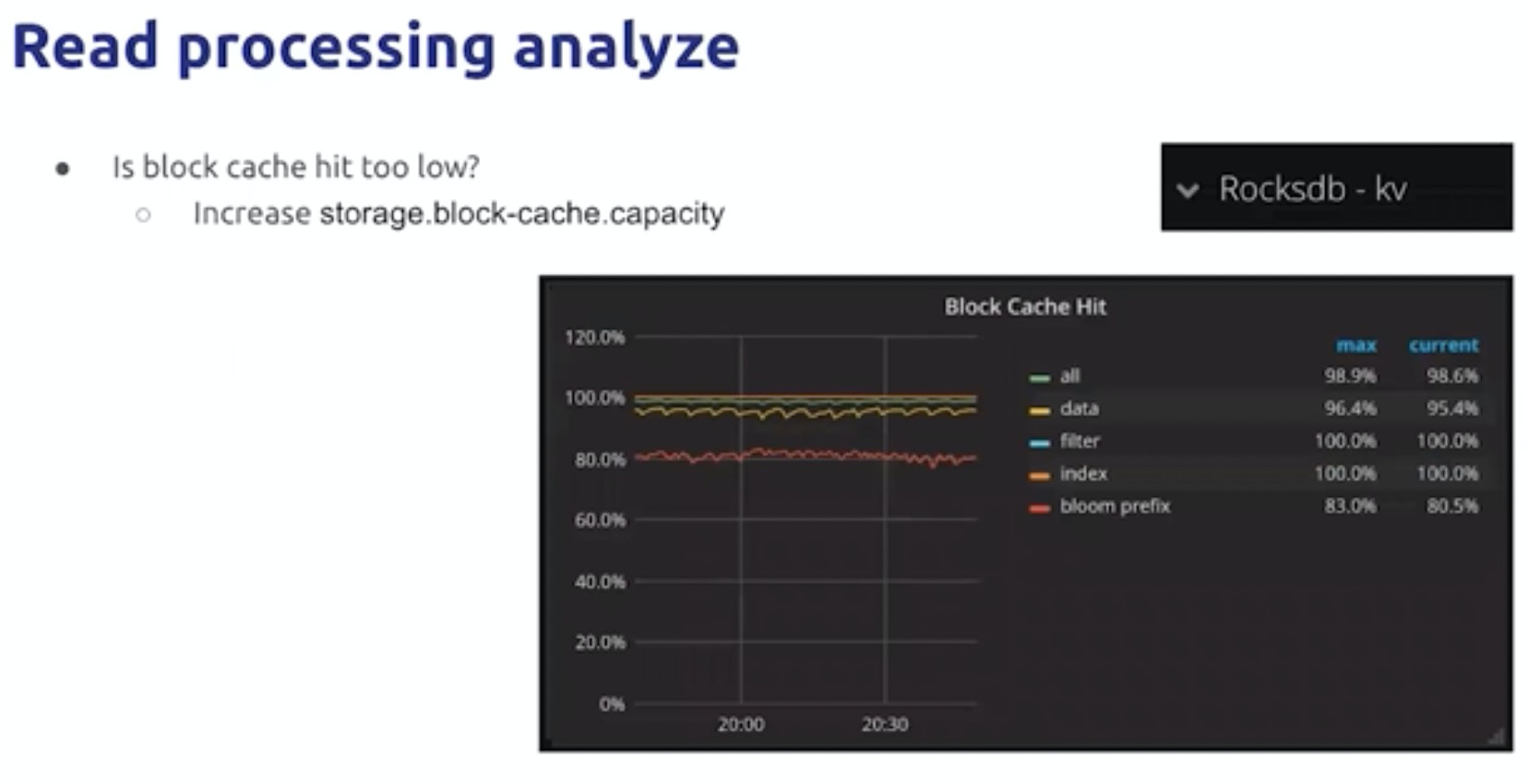
读请求

block cache 命中率
block cache是是有线程共享的,提高配额会使得所有线程受益
性能调优 - 故障排查实战
常见瓶颈
-
CPU
-
MEM
-
IO band
-
NetWork band



示例:
CPU
-
NUMA ISSUE:
PD TSO WAIT & compile TIME 不相关的两个指标加长;CPU使用率不高
内存访问时延很长
-
TIDB CPU 最大线程数限制
-
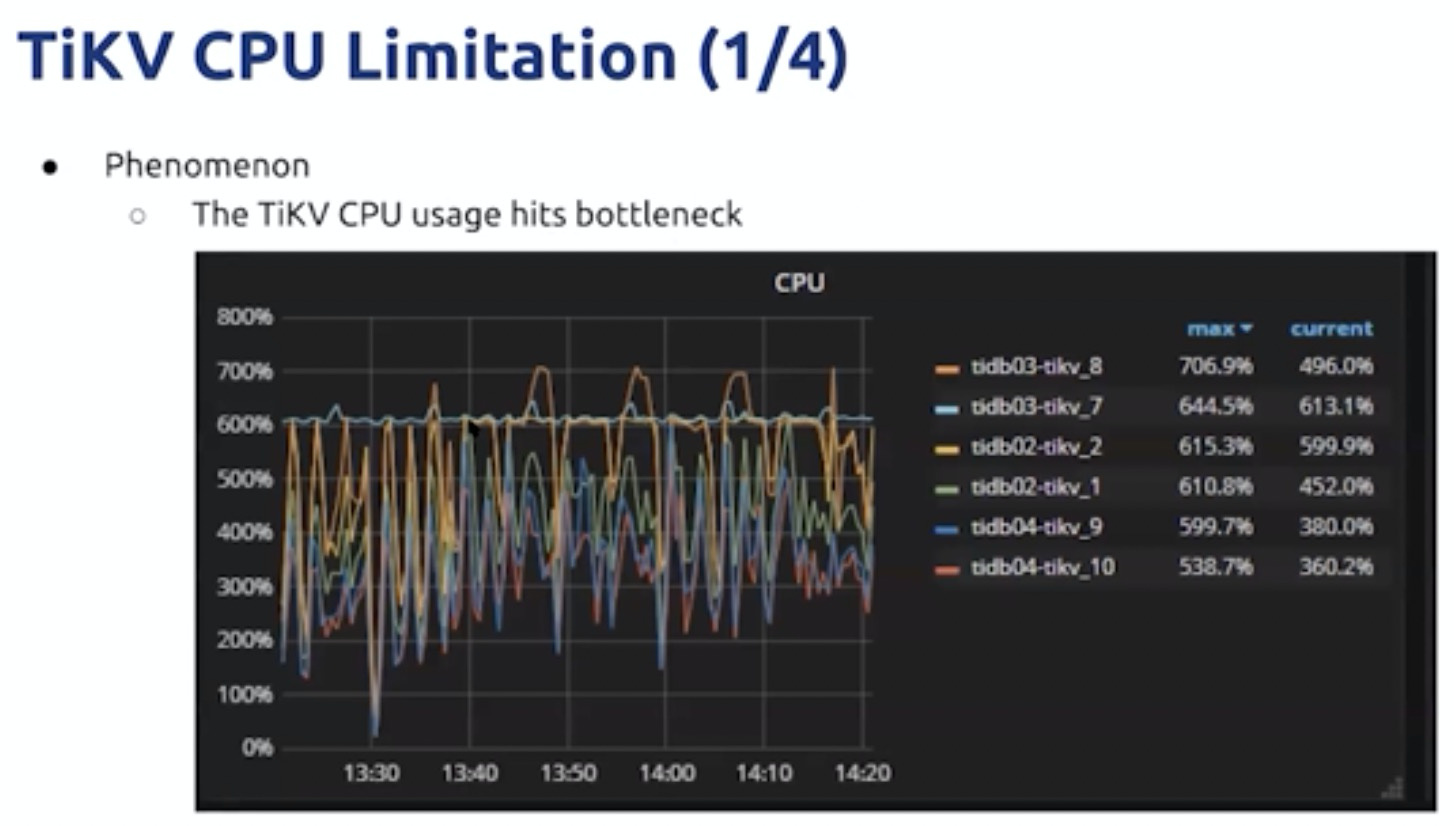
TIKV CPU
下推计算使用率达到瓶颈,
coprocoser 全表扫描








IO

因为是网络存储,所以要考虑GRPC的延迟,利用定位问题端
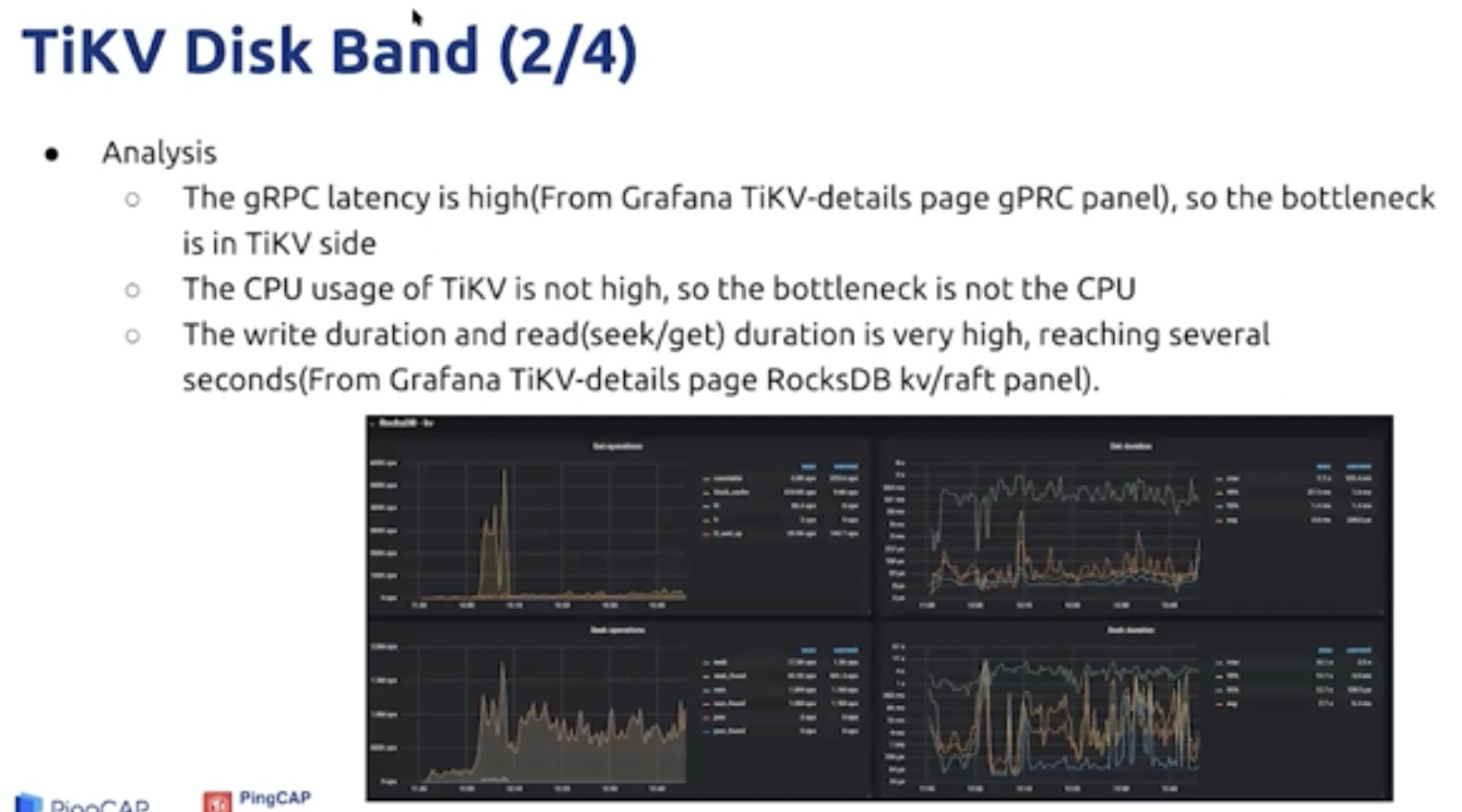
write stall 写入限流,
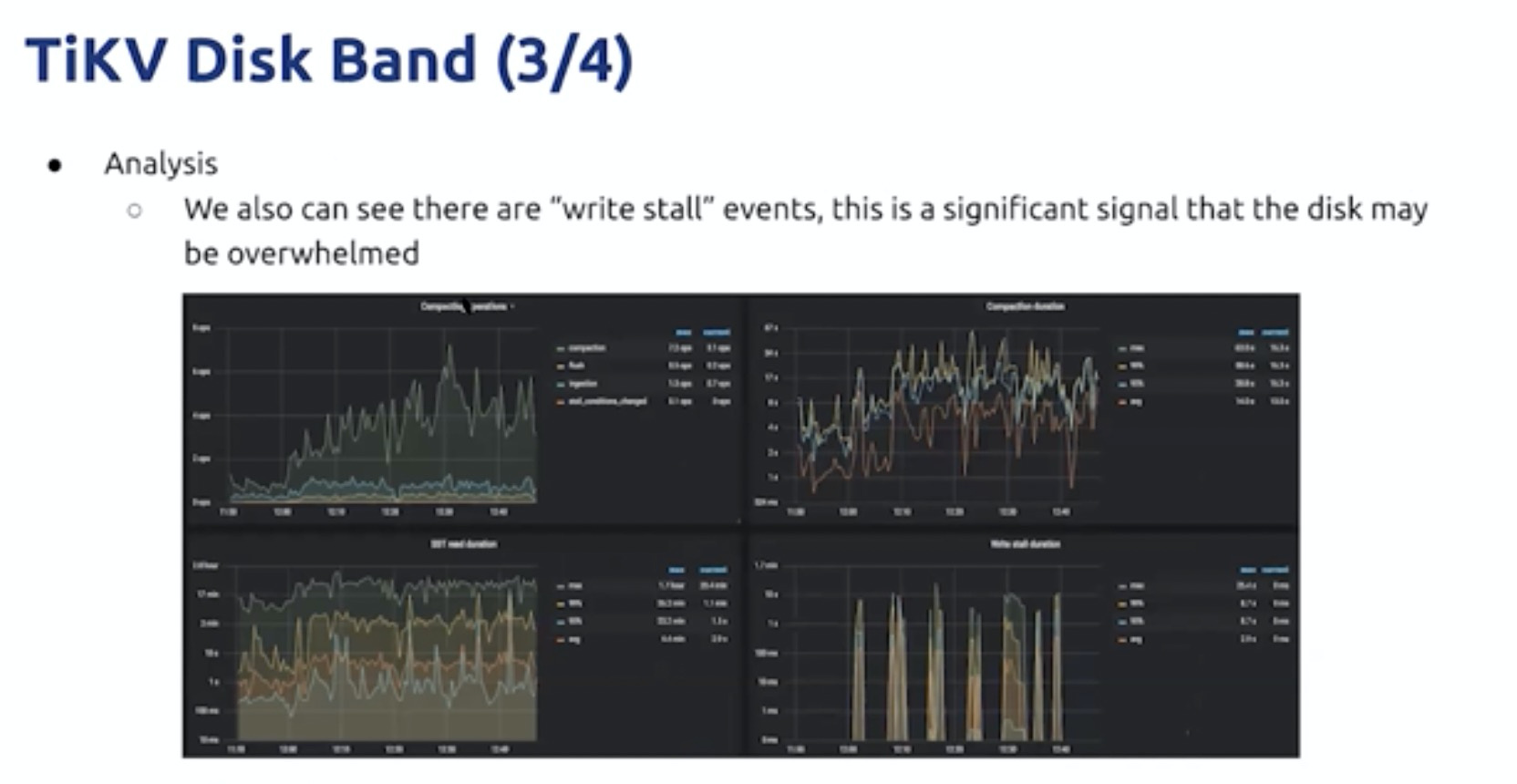
磁盘过载

无法扩容底盘性能,可以横向增加TIKV节点。
学习过程中遇到的问题或延伸思考:
- 问题 1:
- 问题 2:
- 延伸思考 1:
CPU负载高利用率低:说明等待执行的任务很多,但是通常任务多CPU使用率也会比较高,如果低就说明CPU根本没工作,哪些很多的任务处于等待状态,可能进程僵死了。可以通过命令ps –axjf查看是否存在D状态的进程,该状态时不可中断的睡眠状态。这种状态无法被KILL。而有时候你通过top命令也看不出来,只能显示LOAD高,但是没有哪个进程的CPU使用率明显高,你可以通过ps –ux来查看。
CPU利用率高负载低:说明任务少,但是任务执行时间长,有可能是程序本身有问题,如果没有问题那么计算完成后则利用率会下降。 - 延伸思考 2: