为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:4.0.0
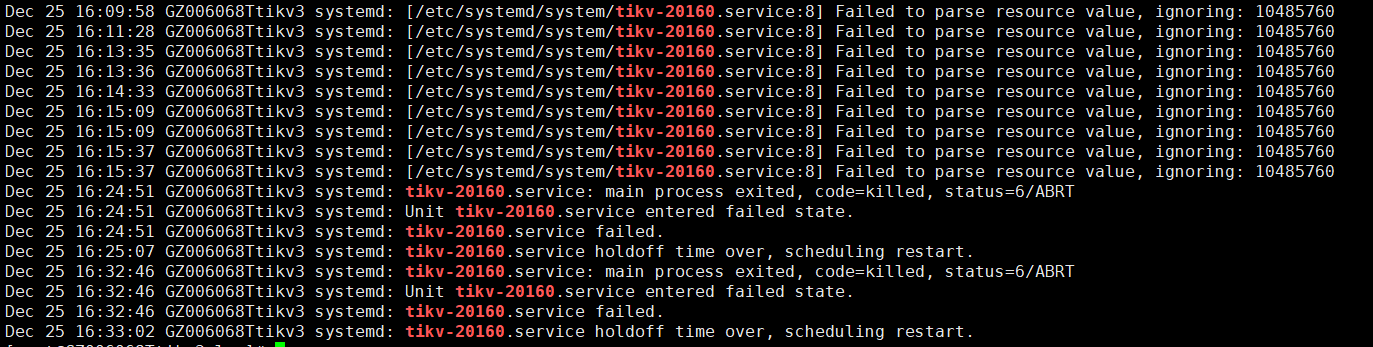
- 【问题描述】:集群3台tikv突然依次短时间内多次重启,日志中勉强找到一些信息,看上去是程序断言报错,目前整个cluster重启后依然报该错误,麻烦大佬看下排查思路,谢谢
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
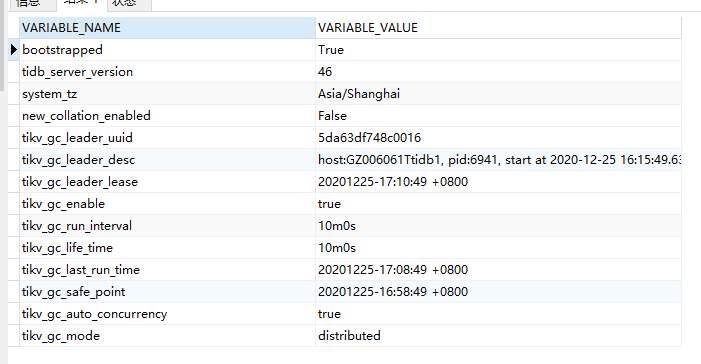
刚跟开发沟通,他们在故障发生之前导入了一张40G左右的表,目前tikv日志中有大量gc_worker.rs:484] [“unsafe destroy range finished cleaning up all”]日志打印,观察gc的safe point在缓慢推进