课程名称:3.1.1 TiDB Cluster Monitoring(本地化部署的 TiDB 集群监控)
学习时长:
30分钟
课程收获:
了解 TiDB 的监控系统的架构,了解 Overview 面板的各项参数的意义,了解报警规则与报警邮件的配置
课程内容:
一、TiDB的监控系统
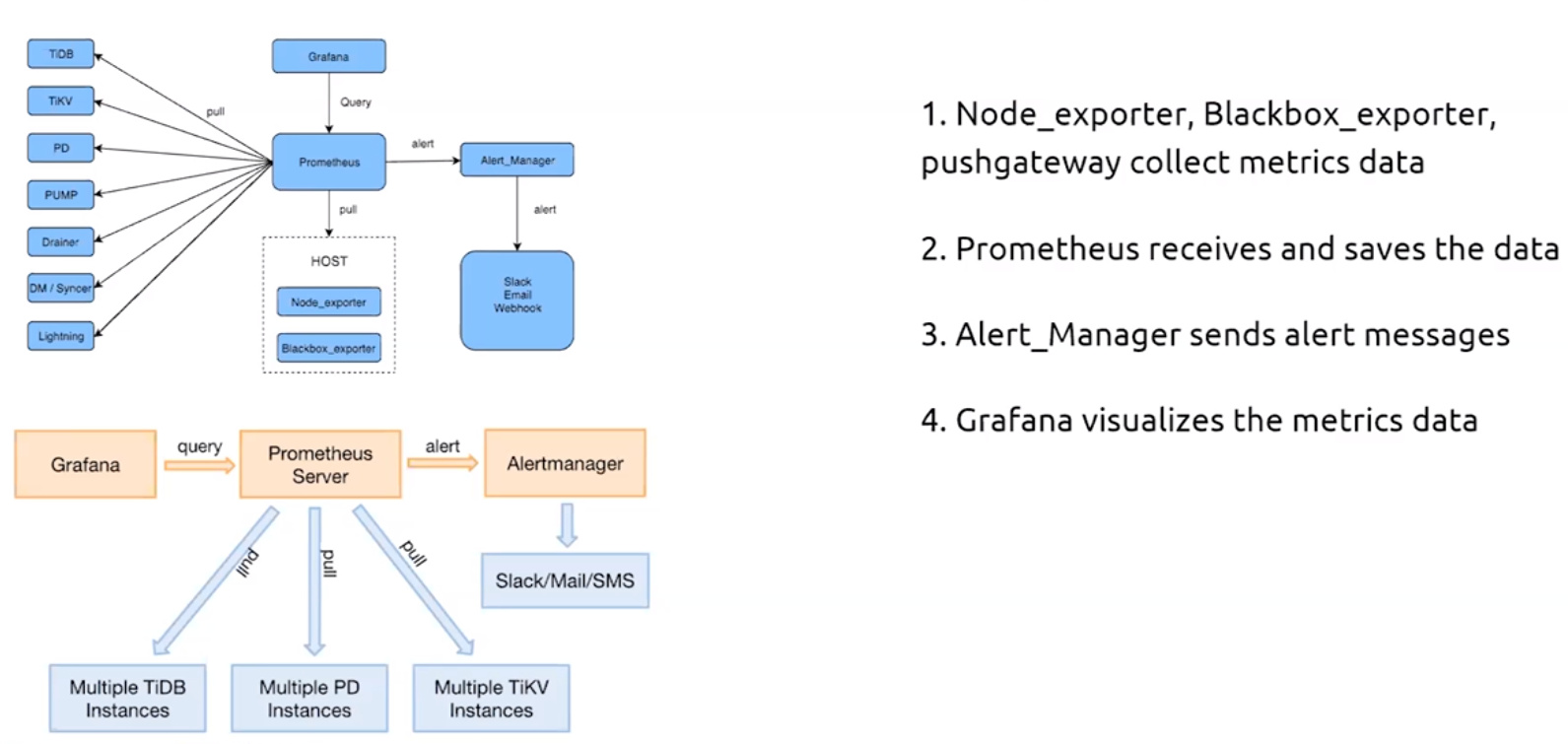
- TiDB监控系统使用了两个开源项目:Prometheus(普鲁米修斯)和Grafana
- Prometheus是监控告警工具,存放TiDB Cluster把监控数据
- Grafana是可视化分析工具,把监控数据展示成图表
- 组件介绍
- Prometheus是监控系统+时序数据库
- Grafana是可视化分析工具
- Alert_Manager从Prometheus获取监控规则,并在需要时报警
- Pushgateway收集TiDB监控数据推送给Prometheus
- Node_exporter收集硬件相关的监控数据推送给Prometheus
- Blackbox_exporter收集网络相关的监控数据推送给Prometheus
二、Grafana的监控视图
1.页面图表实时刷新
- 左上角是面板名称可选择相应分类(全局、PD、TiDB、TiKV等)
- 时间范围的选择关系到数据正确与否
- Overview面板
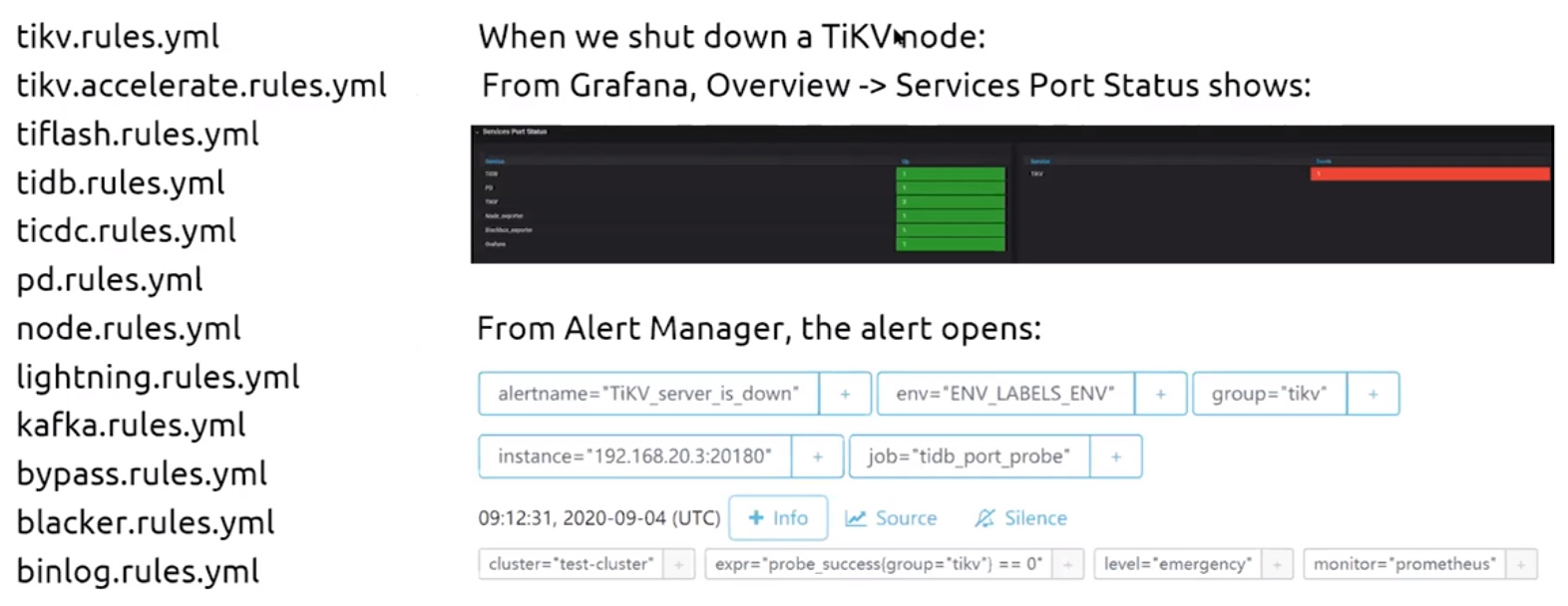
- Service Port Status展示所有组件运行状态,通过红色绿色标记状态是否正常
- PD可以看到Region调度相关信息、PD相应信息及TiKV状态
- TiDB不仅展现整体系统表现如OPS、QPS等,同时展示与TiKV和PD交互的性能表现,还会展示内存与锁相关信息
- TiKV展示存储相关性能表现包括coprocessor的状态
- System Info展示操作系统层面信息
- Service Port Status
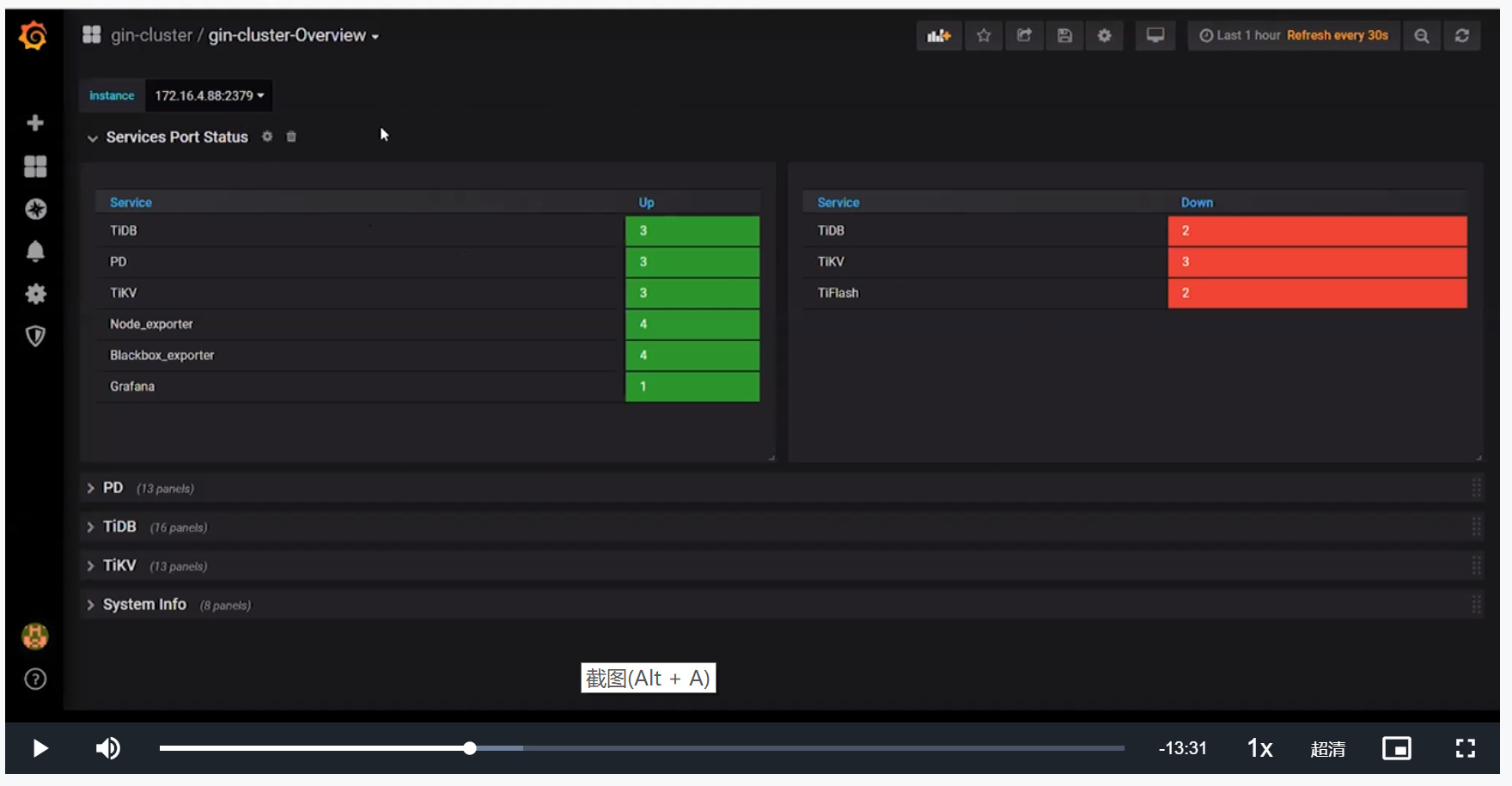
- 只有一个Services UP图表,左边是组件名称,右边展示错误组件(红绿色标注)
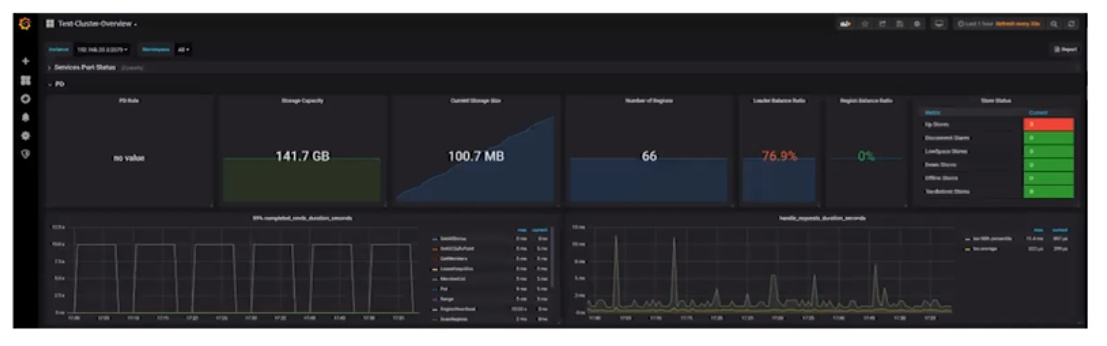
- PD面板
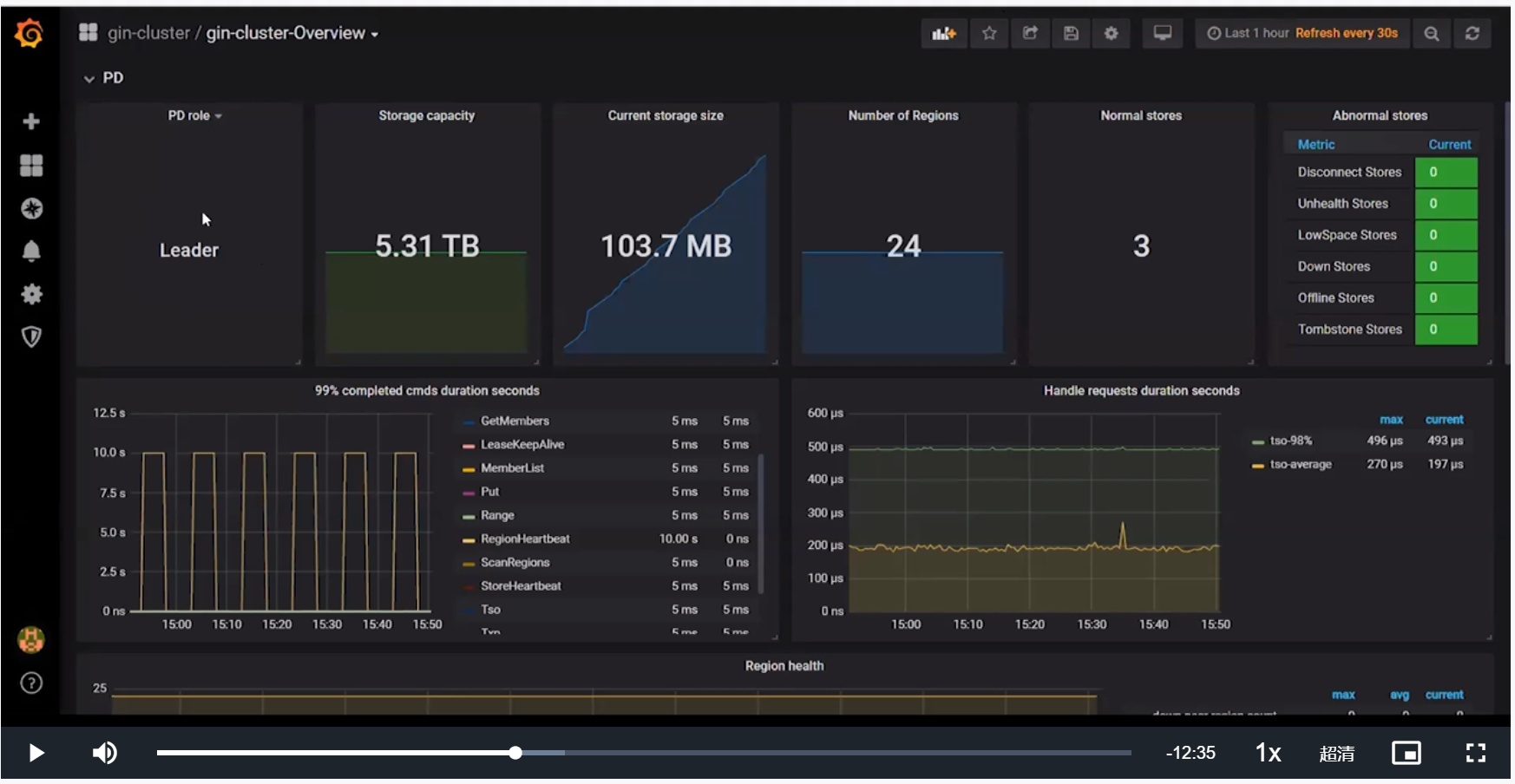
- PD role代表当前PD的角色
- Storage capacity代表TiDB Cluster下面总共的磁盘大小
- Current storage size代表当前已使用大小
- Number of Regions代表总共的Regions数量
- Normal stores代表TiKV数量
- Abnormal stores代表TiKV是否存在错误
- 99% completed cmds duration seconds代表99%的请求完成时间
- Haddle requests duration seconds代表分发TSO的性能
- Region Health记录Region健康信息
- Hot write Region’s leader distribution记录Region热点情况
- Hot read Region’s leader distribution记录Region热点情况
- Region heartbeat report记录Region心跳情况
- 99% Region heartbeat latency记录Region心跳延迟
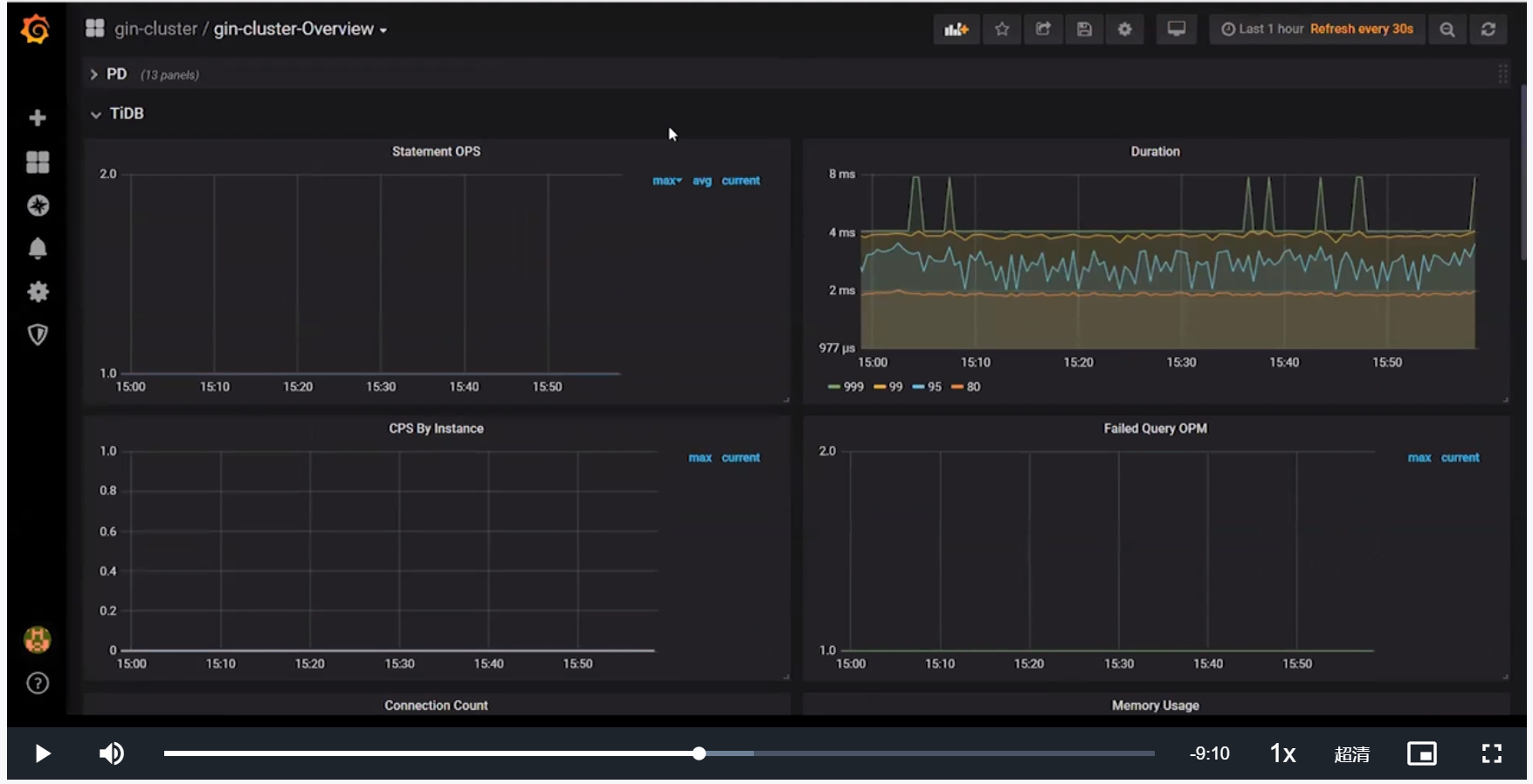
- TiDB面板
Statement OPS展示Statement级别的速度(每秒执行次数)
Duration展示从发送请求到接受请求的时间,如果是多个请那就是多个请求的时间(Statement执行时间)
Connection Count展示TiDB接受的总的Connection数量
Memory Usage如果过大会导致OM的发生,导致TiDB进程崩溃
PD TSO Wait Duration展示PD请求的效率
Lock Resolve OPS展示清理锁的数量,TiDB遇到锁会尝试清理锁 - TiKV面板
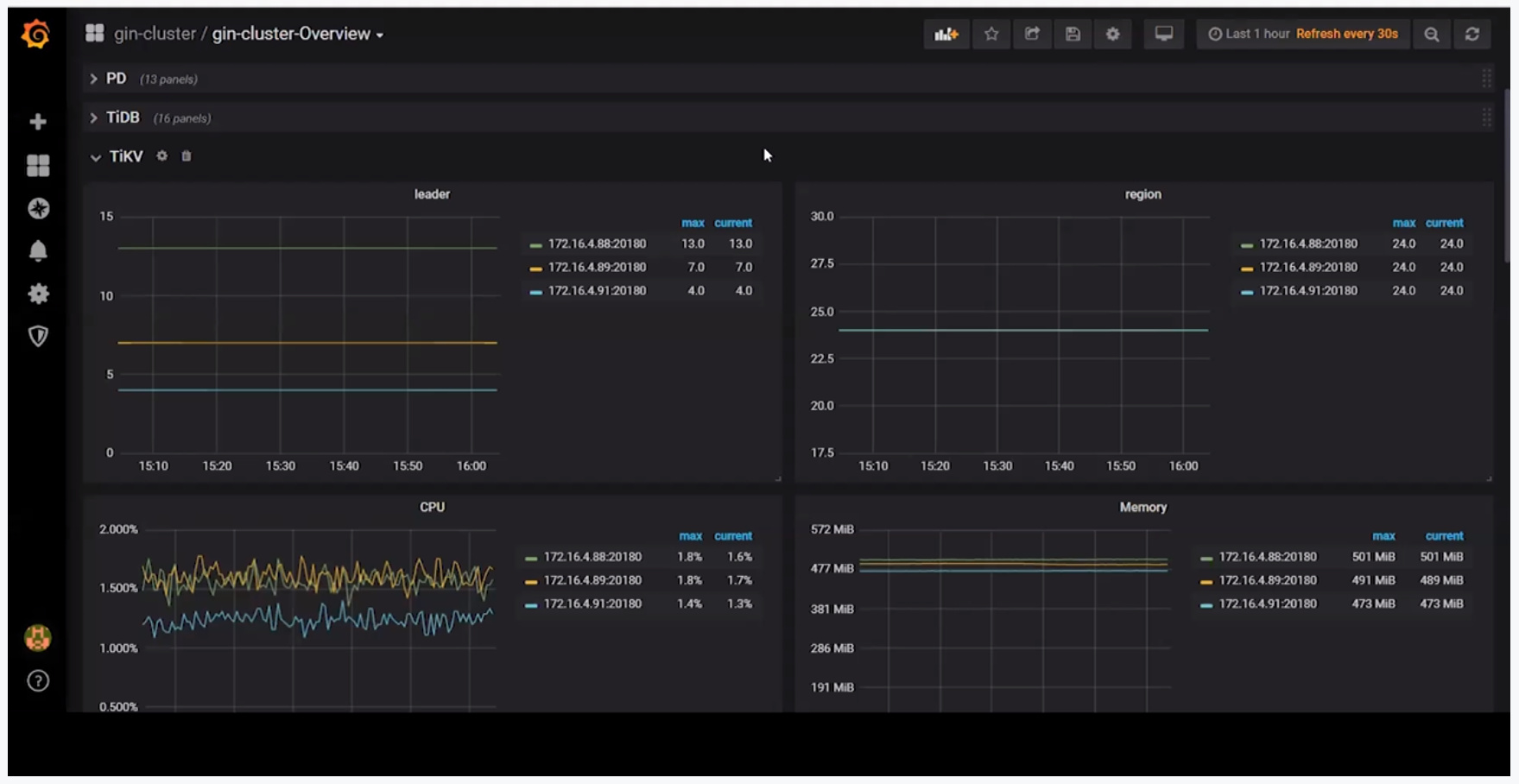
- leader & region展示leader/region分布是否均衡
- CPU & Memory展示每个TiKV的CPU和内存的使用情况
*store size展示每一个TiKV占用磁盘情况 - server report failures展示Server的错误情况
- schedule pending commands展示每个TiKV实例上正在pending的命令的数量
- raft store CPU展示数据副本之间的同步状态,如果过高则表示正进行大量的同步工作
- System Info

三、TiDB监控系统
- Alert Manager
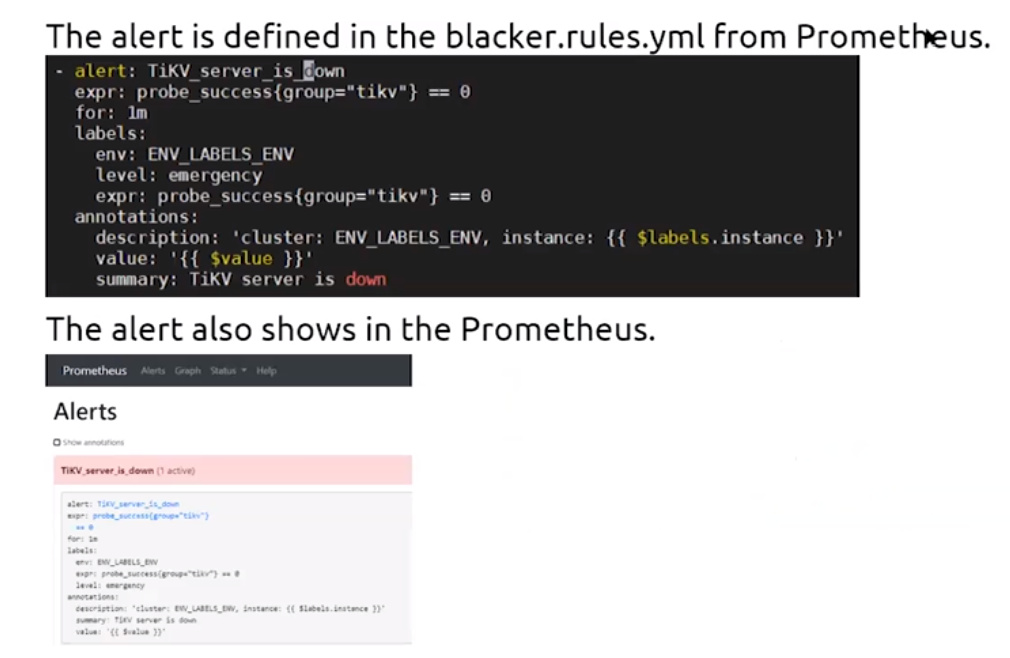
根据配置发送告警邮件或信息,分别包含Prometheus的规则配置和Alert Manager的报警配置 - Alert Rules
配置带Prometheus中,包含严重、关注和警告三个级别 - Alert Rules Defination Files
通过名字区分
模拟告警的详细信息
- Send Out The Alert
配置相关邮箱、微信等