课程名称:301 + 3.1.1 TiDB Cluster Monitoring(本地化部署的 TiDB 集群监控)
学习时长:20min
课程收获:了解 TiDB 的监控系统的架构,了解 Overview 面板的各项参数的意义,了解报警规则与报警邮件的配置
课程内容:
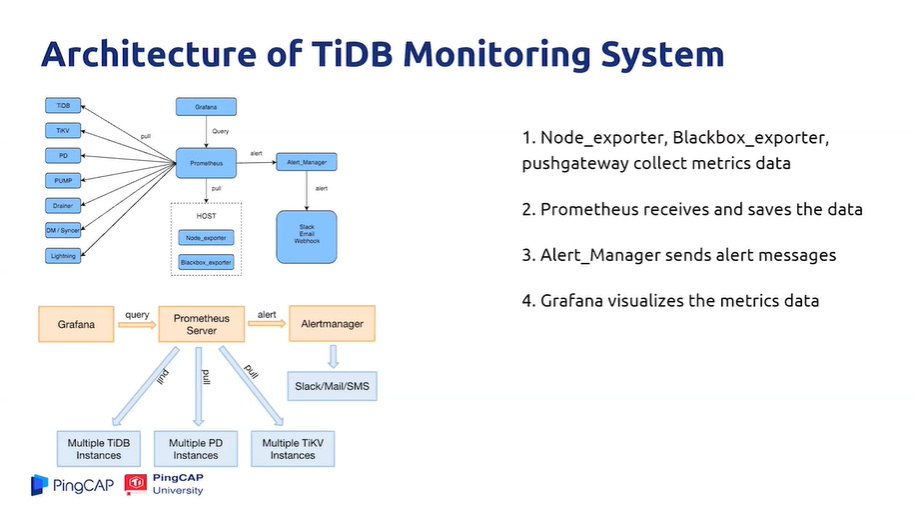
TiDB 监控系统:
- TiDB 监控系统使用了两个开源项目,Prometheus 和 Grafana。
- Prometheus:监控和报警工具,使用时序数据库保存监控数据,TiDB Cluster 将监控数据保存在 Prometheus 中。
- Grafana:可视化分析工具,可以将保存在 Prometheus 中的监控数据展示成图表。
- Alert_Manager:从 Prometheus 获取监控规则,并在需要时报警,根据配置发送邮件、slack 或 SMS。
- Pushgateway:从各个 TiDB 组件收集监控数据,并将数据提供给 Prometheus。
- Node_exporter:收集硬件相关的监控数据,并将数据提供给 Prometheus。
- Blackbox_exporter:收集网络相关的监控数据,并将数据提供给 Prometheus。
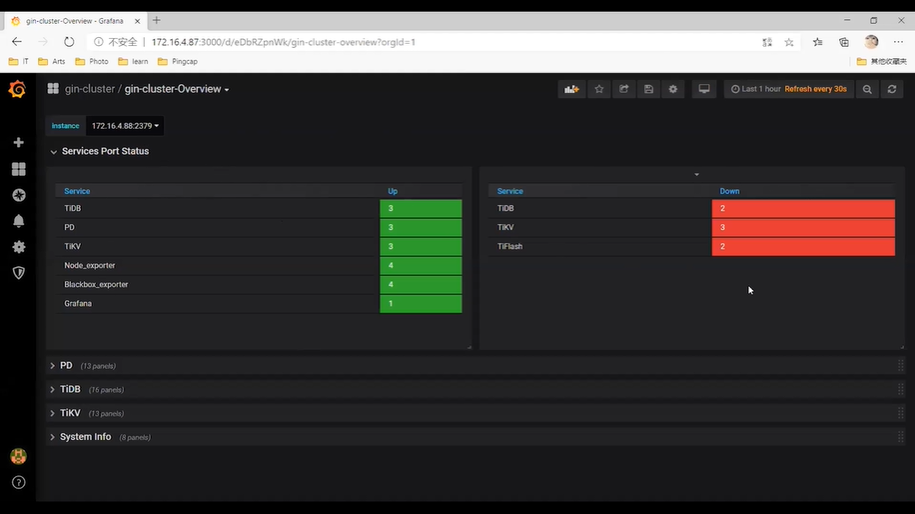
Grafana Overview 面板:
services port status:展示所有组件的运行状态。左边绿表示正常,右边红表示异常。
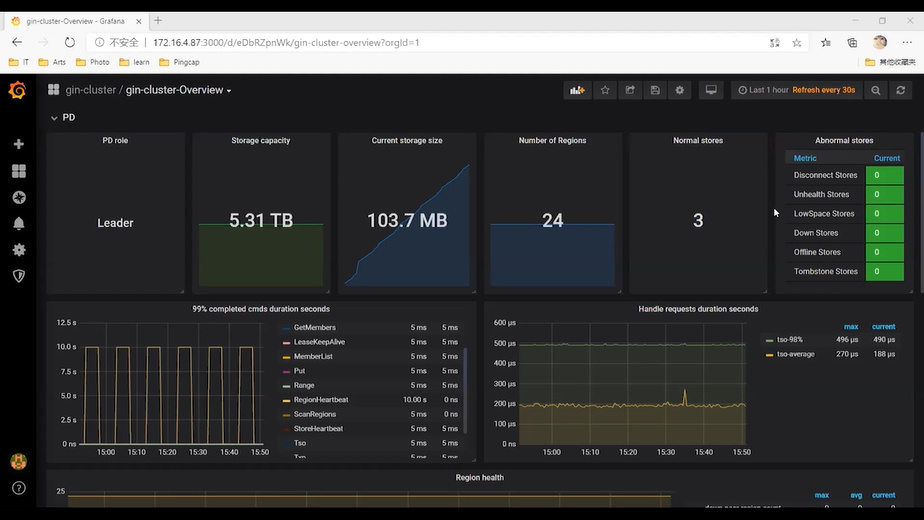
PD:region 调度相关信息,PD 响应信息,TiKV 状态。
- Cureent storage size: TiDB Cluster 硬盘已使用存储空间
- Number of Regions: Region 总数
- 99% completed_cmds_duration_seconds: 99%的请求完成的耗时
- Region health: Region 的健康信息
- Hot write/read Region’s leader distribution: 热点Region信息
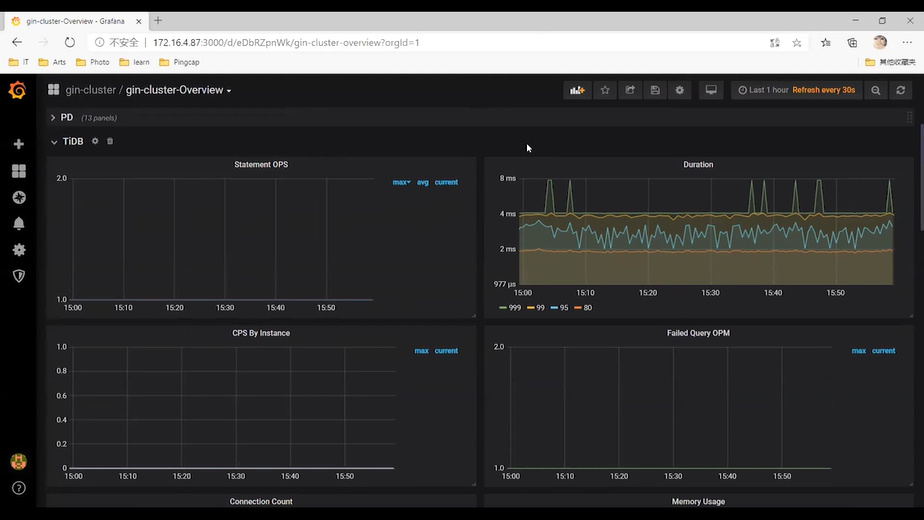
TiDB:总体性能表现如:OPS、QPS、TPS、Connection Count;与 PD 和 TiKV 交互的性能表现;内存;锁信息。
- Statement OPS: statement级别的SQL执行速度
- Duration: Client 发送请求到收到返回的耗时
- Connection Count: TiDB接收到的总连接数量
- PD TSO Wait Duration: PD 返回 TSO 给TiDB 的耗时
- Lock Resolve OPS: TiDB 清理锁的数量
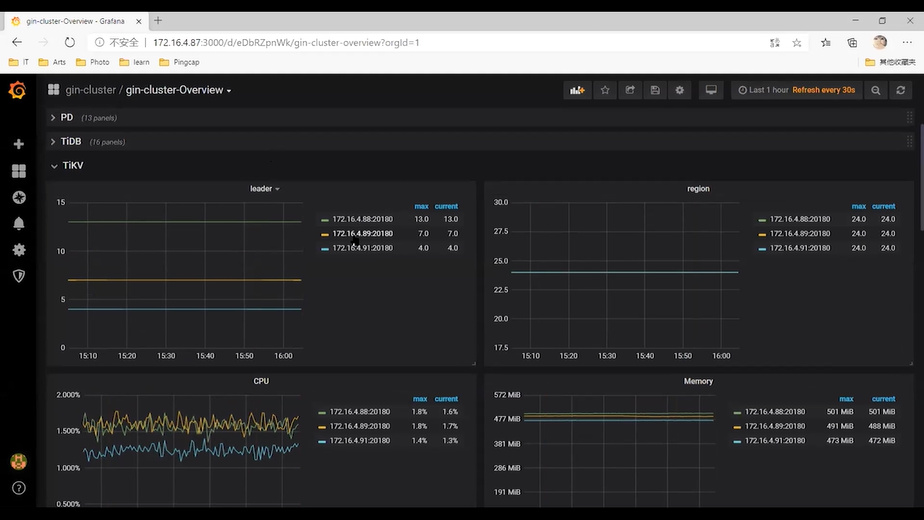
TiKV:存储相关的性能表现;Coprocessor 信息。
- leader & region: leader 和 region 的信息,主要是分布是否均衡
- CPU: 每个 TiKV CPU 使用情况,可以用于发现热点问题
- server report failures: 每个 TiKV 的错误情况
- scheduler pending commands: 每个 TiKV 上 pending 的命令数量
System Info:从操作系统层面展示运行情况,如:CPU、Memory、IO、Network。
Alert_Manager :
报警级别:
- Emergency:紧急,需重视并迅速排查解决。
- Critical:重要,需要调查对系统的影响,制定相应的解决方案。
- Warning:系统中有报错,需要进一步分析。
报警规则配置文件:
位于 /home/tidb/deploy/conf/ 目录下,主要包括以下12个:
- tikv.rules.yml
- tikv.accelerate.rules.yml
- tiflash.rules.yml
- tidb.rules.yml
- ticdc.rules.yml
- pd.rules.yml
- node.rules.yml
- lightning.rules.yml
- kafka.rules.yml
- bypass.rules.yml
- blacker.rules.yml
- binlog.rules.yml
发送报警的配置文件:
/home/tidb/deploy/conf/alertmanager.yml