课程名称:课程版本(101/201/301)+ 课程名称
学习时长:
课程收获:
课程内容:
- TiDB监控系统
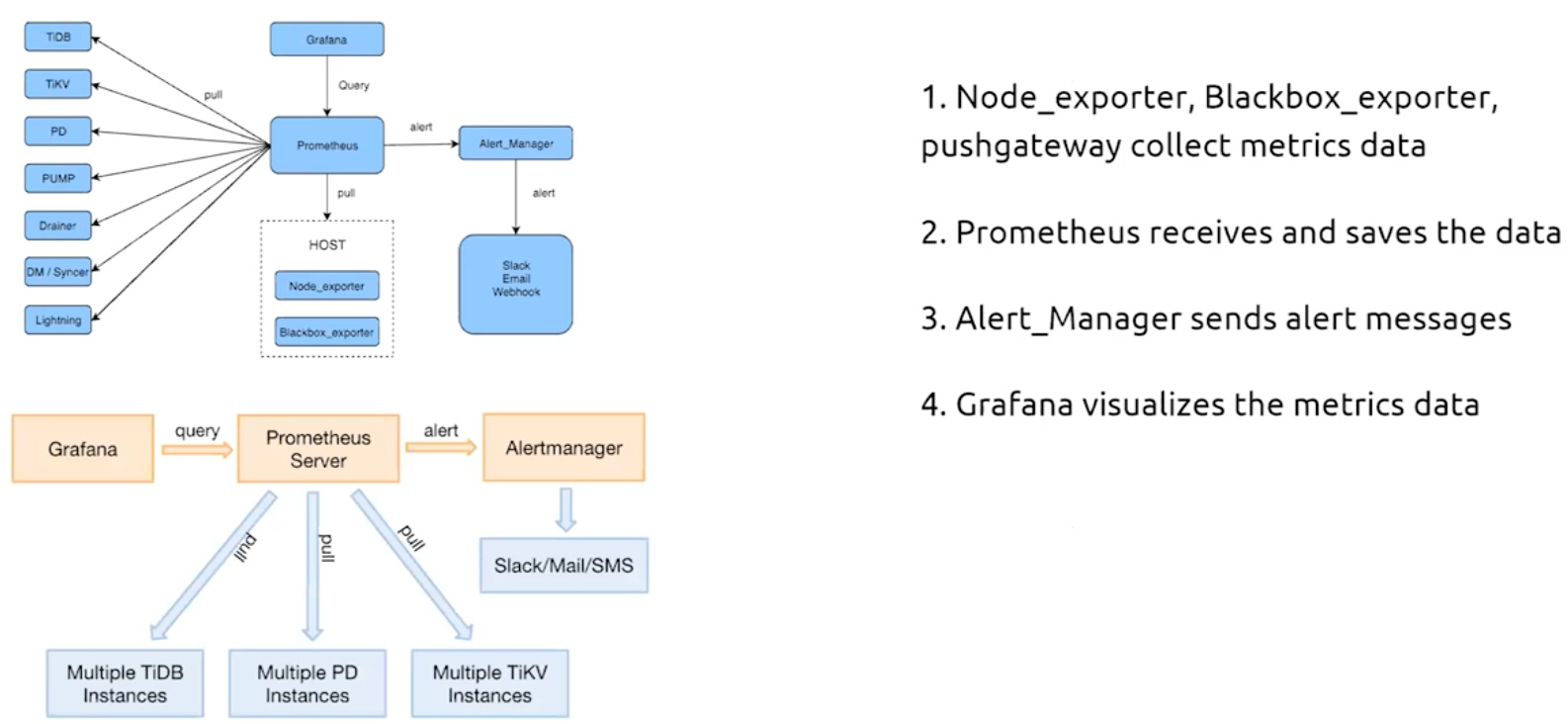
- Prometheus and Grafana
- Prometheus:存储监控及性能指标
- Grafana:展示性能指标
- 组件介绍
- Prometheus:开源监控系统+时序数据库
- Grafana:监控数据可视化工具
- Alert_Manager:告警组件,通过email,slack,sms发送告警
- Pushgateway:收集指标数据,等待prometheus拉去
- Node_exporter:收集硬件指标,推送到prometheus
- Blackbox_exporter:收集网络指标,推送到prometheus
- TiDB监控系统架构
- Grafana
- Grafana看板介绍
- overview看板
- 服务端口状态:所有组件的状态
- PD:检查Region相关状态,PD 请求持续时间
- 用于查看PD请求的频率,region健康
- pd role: 当前节点的角色
- pd compactiy:所占用硬盘大小
- 重要指标
- Current storage size:当前存储大小
- Number of Regions:region 数量
- 99% completed_cmds_duration_seconds:有99%请求的完成时间,都是在应小于5ms
- Region health:健康状态
- Hot write/read Region’s leader distribution:热点leader数量
- TiDB:OPS,QPS,连接,事务,与TiKV和PD的连接状态
- TiDB性能信息,用于查看查询状态、TiDB与PD/TiKV的通信情况
- 重要指标
- Statement OPS:SQL语句的执行性能
- Duration:语句执行时间,重要参数
- memory usage:如果过大的话会OOM,tidb进程崩溃
- Connection Count
- PD TSO Wait Duration
- Lock Resolve OPS:清理锁的数量
- TiKV:region,size,scheduler pending,coprocessor status
- 用于查看region分布及coprocessor运行状态
- 重要指标
- leader & region:主要看分布是否均衡
- CPU:每个TIKV和memory的使用情况
- server report failures:每个TiKV实例的错误消息数量
- scheduler pending commands
- 系统信息:CPU,Memory,IO,Network
- 其他看板
- TiDB告警系统
- Alert Manager
- Alert Rules
- Alert Levels:Emergency、Critical、Warning
- /home/tidb/deploy/conf
- Alert Rules Definition Files
- tikv.rules.yml
- tikv.acclerate.rules.yml
- tiflash.rules.yml
- tidb.rules.yml
- ticdc.rules.yml
- pd.rules.yml
- node.rules.yml
- lightning.rules.yml
- kafka.rules.yml
- bypass.rules.yml
- blacker.rules.yml
- binlog.rules.yml
- Send Out The Alert
- /home/tidb/deploy/conf/alertmanager.yml
学习过程中遇到的问题或延伸思考:
学习过程中遇到的问题或延伸思考:
学习过程中遇到的问题或延伸思考:
- 问题 1:
- 问题 2:
- 延伸思考 1:
- 延伸思考 2:
学习过程中参考的其他资料