1. 背景
伴鱼在发展初期,数据存储选择了MongoDB数据库,Mongodb数据库同时也支撑了伴鱼很长一段时间的业务发展。随着伴鱼业务场景的丰富以及数据量的增长,MongoDB在有些方面开始出现问题,比如业务对事务的要求、单表性能问题、单机的容量瓶颈和从节点请求不均衡等问题。基于以上问题,数据存储,我们选择了业界比较火的分布式TiDB数据库,详细介绍可见<我们为什么放弃MongoDB和MySQL,选择TiDB>一文。
2019年,伴鱼的新业务All In TiDB,但是历史前5年的数据都积攒在MongoDB数据库(集群20+,单个集群数据最大1T+,数据都是经过zlib压缩的),而且数据还在不断增长,这时MongoDB集群主要存在以下2个主要问题:
-
由于我们的服务器数据盘都是1.5T的nvme,某些集群很快会达到容量瓶颈
-
随着数据量的增长,某些集群大表,由于索引不是最优,性能问题越发明显
对于MongoDB集群数据容量问题,TiDB无限水平扩展特性对于我们来说,无疑是比较好的选择;对于大表索引不是最优导致的性能问题,我们觉得推动研发重新梳理业务和索引,比DBA单纯在大表上添加索引效果会更好。基于这些考虑,我们踏上了MongoDB数据在线迁移到TiDB之路。下面从数据迁移架构及方案的选择,配套建设等方面,详细介绍下我们是如何将MongoDB的数据在线迁移到TiDB的。
2. 数据迁移架构及方案
2.1 数据迁移架构
异构数据库的数据迁移,在业界其实都能找到参考案例,我们的迁移架构如下图所示,主要流程步骤如下:
-
中间件获取MongoDB oplog,将获取的oplog进行解析,写入到kafka
-
分段将MongoDB的数据全量迁移到TiDB
-
数据全量迁移完后,消费kafka数据,将增量数据同步到TiDB
-
对异构数据库两侧数据进行抽样校验
-
将MongoDB的读流量迁移到TiDB
-
将MongoDB的写流量迁移到TiDB
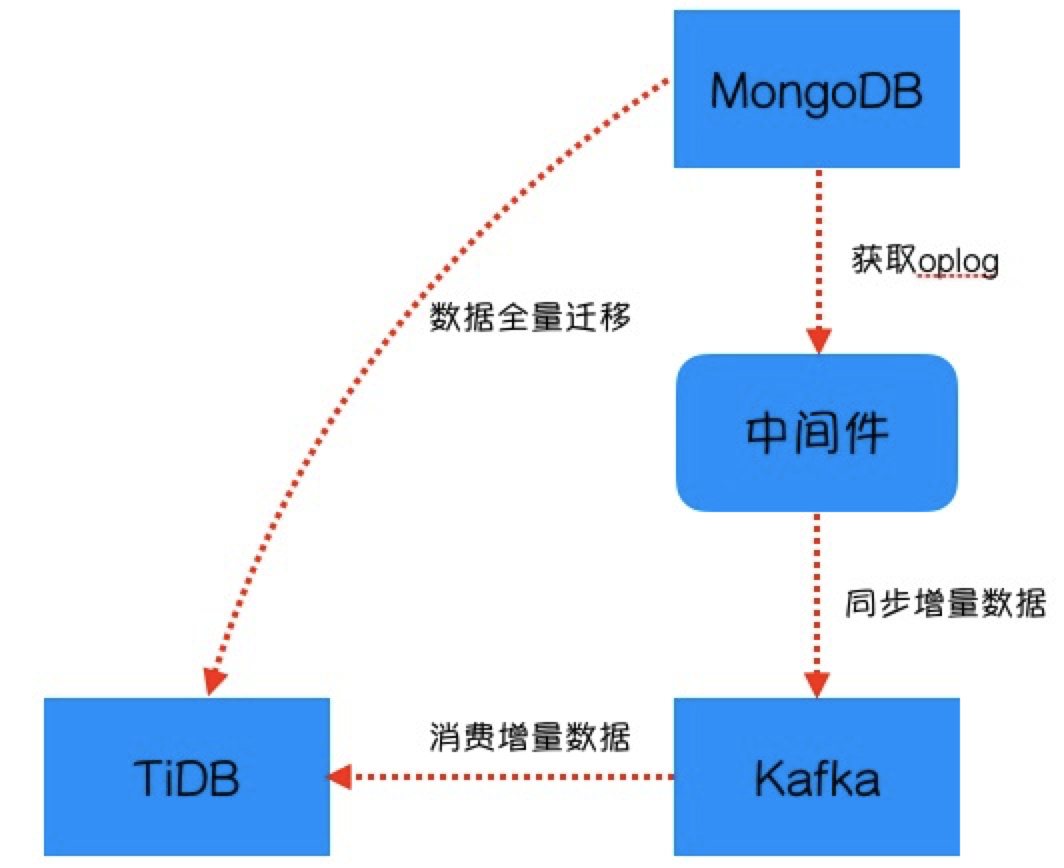
当然这个数据迁移架构也存在一些缺点:
-
写流量不能回滚
-
数据链路较长,存在读延时
2.2 数据迁移方案
不同的业务场景,我们可以采用不同的数据迁移方案。在伴鱼的异构数据库数据迁移过程中,我们主要经历了以下几种场景,下面对以下几种场景进行介绍。
2.2.1 场景一
业务表只有写入和查询,没有更新和删除操作。我们可以不采用中间件迁移的模式,这时迁移的主要流程步骤如下:
-
设计TiDB表结构,梳理原表的使用场景,优化索引
-
业务代码实现数据库双写
-
分段将MongoDB的数据全量迁移到TiDB
-
对异构数据库两侧数据进行抽样校验
-
业务将MongoDB的读流量迁移到TiDB
-
业务将MongoDB的写流量迁移到TiDB
2.2.2 场景二
业务表存在增删改查操作,同时业务表有数据创建时间和更新时间索引。针对这种场景,我们也可以不采用中间件迁移的模式,这时迁移的主要流程步骤如下:
-
设计TiDB表结构,梳理原表的使用场景,优化索引
-
根据objectID或者创建时间索引分段将MongoDB的数据全量迁移到TiDB
-
根据更新时间,将增量数据同步到TiDB
-
对异构数据库两侧数据进行抽样校验
-
业务在低峰期将MongoDB的读写流量迁移到TiDB
2.2.3 场景三
业务表存在增删改查操作,同时业务表没有时间索引。针对这种场景,我们采用中间件模式进行迁移,这时迁移的主要流程步骤如下:
-
设计TiDB表结构,梳理原表的使用场景,优化索引
-
开启中间件获取最新MongoDB oplog,将解析的数据写入到kafka
-
分段将MongoDB的数据全量迁移到TiDB
-
数据全量迁移完后,消费kafka中的数据,将增量数据同步到TiDB
-
对异构数据库两侧数据进行抽样校验
-
将MongoDB的读流量迁移到TiDB
-
将MongoDB的写流量迁移到TiDB
2.3 迁移方案优劣
上述3种场景,数据迁移过程都有其共同点,也有不同的地方,有其优势的地方,也有需要改进的地方。
2.3.1 方案共同点
对于以上3种场景,迁移过程中相同点主要表现在以下几个方面:
-
TiDB表结构设计。这一步做的事情包括:业务需要梳理表上的所有功能(主要是查询),哪些可以优化,哪些可以废弃,哪些索引必须加上等等;同时业务可以优化代码,收拢写入口。最终的目标保证迁移到TiDB的表,在很长一段时间内不会出现性能问题。
-
数据迁移。这一步做的事情包括:业务代码需要兼容数据迁移过程中可能发生冲突的地方(我们参考了在线改表工具的做法);迁移脚本需要做到可以随时启停,灵活控制速度,避免迁移对线上造成压力。
-
对异构数据库两侧数据进行抽样校验。我们把objectID带入到TiDB,同时给该字段加上索引,这样抽样校验会比较方便,等抽样校验完毕后,会把索引清理掉;我们从MongoDB的objectID中解析出机器码时间戳等信息组合出来的一个整形id,作为TiDB表的主键,这样也便于我们做抽样校验;如果MongoDB表中有唯一键,我们不需要做任何变换,直接通过唯一键对两侧数据进行校验。
-
业务读流量迁移到TiDB。业务需要加开关实现快速切换,有问题可以快速回滚。
-
业务写流量迁移到TiDB。读取通常需要观察一周左右,没有问题,切写流量。
2.3.2 方案优缺点
在场景一中,数据迁移全程,DBA参与的工作比较少,只需要配合研发审核sql质量以及数据迁移过程中可能导致的数据库压力问题。缺点是,数据迁移只局限于只有写入的场景。
在场景二中,增量数据通过脚本将满足更新时间的数据查出来进行同步,数据过大或者查询时间过长,都会导致TiDB数据延迟较大。如果业务读请求对数据延时有要求,那么读请求不能切换到TiDB。
在场景三中,由于数据链路较长,对延时要求特别高的场景,也同样存在延时导致两侧数据不一致的问题。
2.3.3 方案改进点
由于方案三可以适用上述的所有场景,所在伴鱼的后续数据迁移中,我们都采用中间件迁移的模式。为了加快数据迁移的速度,同时满足业务对延时敏感的要求,我们对方案三进行了以下改进:
-
原先从MongoDB批量查询一批数据,逐条插入到TiDB,改为每次组装一批数据插入到TiDB。
-
在表数据量增长比较快的场景下,由于中间件这条链路的存在,数据同步延时不可避免。之前的做法是消费kafka并拼装数据后同步到TiDB,后面改为从kafka拿到objectID后,去MongoDB主库查询数据,然后再更新到TiDB。我们这样做的目的是,假如源端mongoDB一条数据频繁更新,同时中间件同步到kafka或者消费kafka数据存在延时,我们也能通过objectID拿到的最新的数据,进一步降低数据迁移延时的问题。
-
原先先迁移全量数据,再消费增量数据,后面改为全量和增量数据同时迁移,迁移速度进一步提高。我们做过一个统计,在raft_store cpu维持在30%左右时,全量和增量同时进行,一天大概可以迁移4~5亿数据。
3. 配套建设
数据通过中间件同步,我们通常需要部署同步MonogDB集群对应的中间件实例,然后确认增量数据是否同步到kafka,最后把kafka地址和对应的topic交付给研发。由于这套部署过程还是比较繁琐的,我们也将其沉淀为平台,如下图所示。
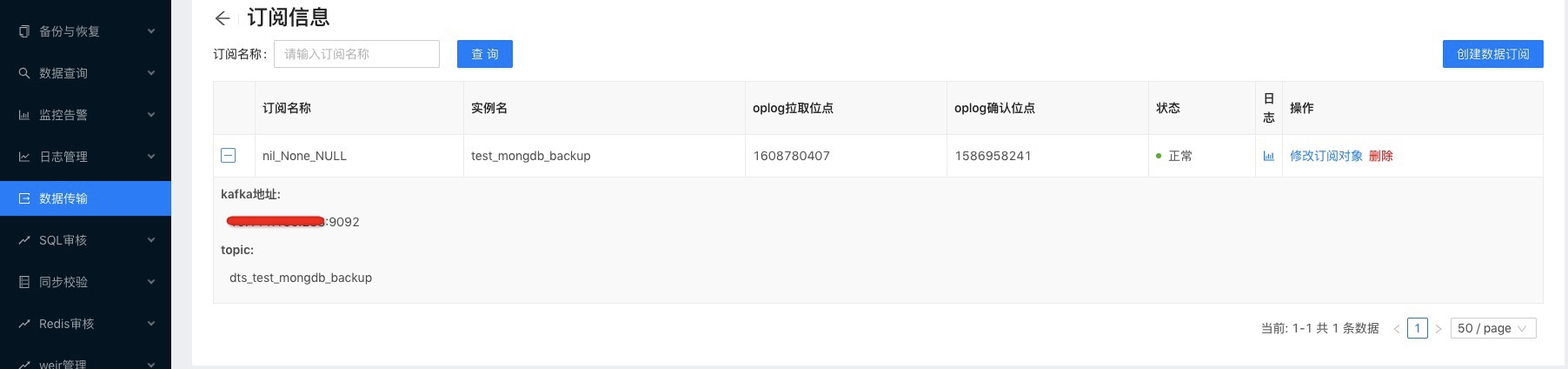
数据迁移涉及数据的全量迁移和增量同步,我们刚开始在绘本业务线迁移了5张亿级大表,同时发现其他业务线也会有类似的迁移需求。由于整个迁移流程已经趋于稳定,同时也我们积累了一些经验,我们把这套代码抽取出来,可以供其他业务线复用。这样当我们推动其他业务线进行数据迁移时,研发只需要一份简单的说明文档,就能轻松搞定了。
4. 总结
目前,我们已经将近3T的MongoDB数据迁移到TiDB,解决了线上部分mongoDB集群存在的性能风险。现有MongoDB集群,还承担着历史众多业务,我们会时刻监测表的性能,如果发现性能风险,我们就会迁移到TiDB。