TiDB 的 SQL 性能优化指南
Part I:SQL Execution Overview
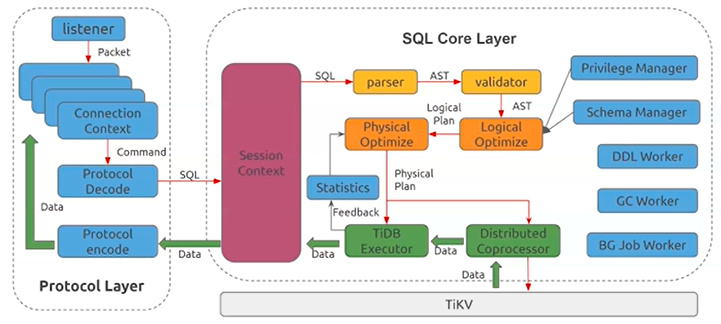
SQL - AST - Logical Optimize - Physical Optimize - TiDB Executor

Part II:Optimization Tuning Guide
Example
- estRows 估算的输出行
- access object 访问了哪个表/索引
- operator info 详细信息
- execution info 执行详细信息
Query Optimizer
- Logical optimization
- MAX/MIN Elimination
- Convert a single Max to Top N
- Convert a single Max to descendingly ordered scan
- Subquery Transformation
- 关联子查询
- Correlated ones: aggregate → normal join
- 需要看外表大小及关联列是否有索引(↓)
- 可以通过 optimization_rule_blacklist 关闭
- 非关联子查询
- converted to inner join
- aggregation can be removed automatically if there’s unique key
- 当子查询中表很大时,其聚合会挡住驱动表index join的执行(↓)
- 通过将 tidb_opt_insubq_to_join_and_agg 参数改为 0 来关闭
- 如果子查询涉及的列是可为NULL的,TiDB会将 semi join 转换为笛卡尔积的形式(↓)
- 关联子查询
- Aggregate Push Down
- jion 这个聚合可以显著的减少join输入的时候
- union 可以显著的减少union输入的时候
- 默认是关闭状态,可以将参数 tidb_opt_agg_push_down 设置为 1 去开启
- Join Reorder
- extract join nodes
- apply a DP algorithm if the join group size is small
- apply a greedy algorithm otherwise
- MAX/MIN Elimination
Physical Optimization
-
选择物理的执行算法的搜索过程
-
物理优化实际上是带着计划搜索的搜索框架
-
可以使用hints/SPM来控制
-
TiDB也是会选择索引,选择错误的索引可能的原因是统计信息有误
-
如果依旧选择错误(例如本应该选择TiFlash却选择了TiKV)
-
可以通过降低 tidb_opt_seek_factor 参数的值来进行调节
-
如果依旧选择错误那么就需要考虑使用hints/SPM
Part III:Execution Tuning Guide
Execution Engine 每组读的数据量通过 tidb_max_chunk_size 来控制
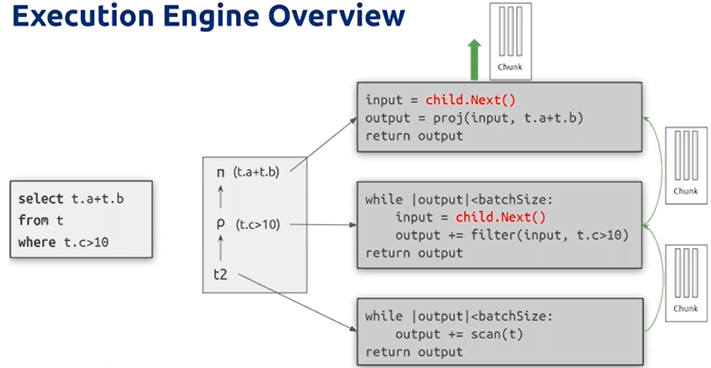
已经实现并行化的算子
- Hash Join、Index Join、Hash Aggregate…
Hash Join
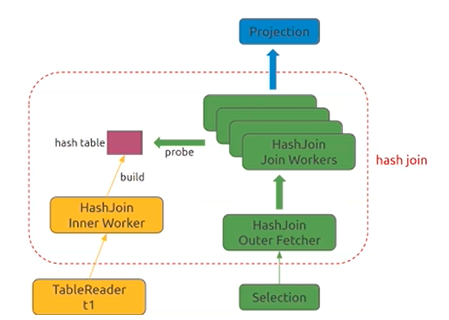
build - 暂时无法并行
probe - 并行
tidb_hash_join_concurrency (default 5) 控制hash join worker的数量
Index Join
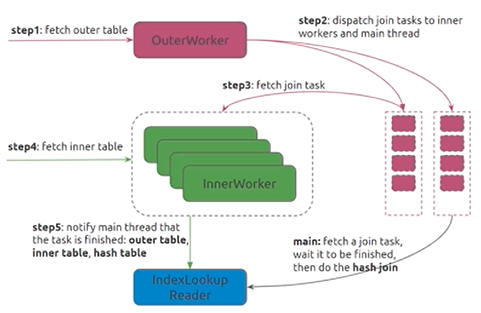
先拿到驱动表数据,分解为多个task,然后将task分发给inner worker, inner worker依据task去构造索引请求,去查找inner table的数据,inner worker再进行hash匹配得到更精确的结果,最后反馈给上层
tidb_index_lookup_join_concurrency (default 4)控制inner worker数量
tidb_index_join_bath_size(default 25000)控制每个inner worker有多少行
Merge Join
- 单线程
- 数据按照join key 有序的
- 优点 - 内存消耗的少
NestedLoopAPPLY
- 单线程
- Row by row 每获取驱动表一条数据都会去子查询中匹配
- 并不是很有效的
Hah Aggregate
类似MapReduce
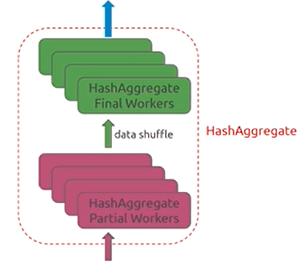
tidb_hashagg_final_concurrency(default 4)控制final worker的数量
tidb_hashagg_partial_concurrency (default 4)控制 partial worker的数量
Stream Aggregate
- 单线程
- 需要按照group by key 有序
- 使用内存比hash join少
Index Lookup Reader
- 首先会去拿到索引侧的数据
- 分发为多个task
- task分配给多个table worker
- table worker依据rowid去构造rowid的范围查询
- 在表上读到数据库,在worker中进行hash运算
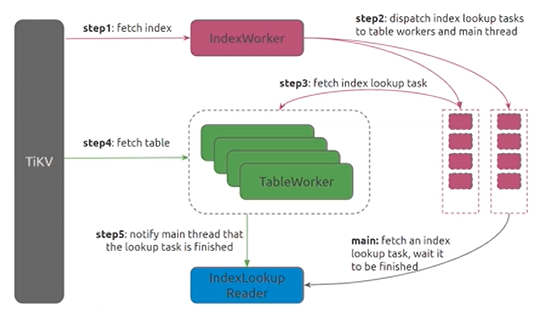
tidb_index_lookup_concurrency (default 4)控制table workers的数量
tidb_index_lookup_size(default 20000)控制lookup size大小
Part IV:Control the execution plan
USE HINT
- Index hint(use/force/ignore index)
- 用法与MySQL一致
- comment style hint(/* +HINT_NAME(T1,T2) */)
- 写在select field前
SQL Plan Management
- CREATE BINDING syntax
- 可以控制一组SQL
- 可以通过 SHOW BINDING 查看现在创建的BINDING