【 TiDB 使用环境`】
测试环境
【 TiDB 版本】
v5.4.0
【遇到的问题】
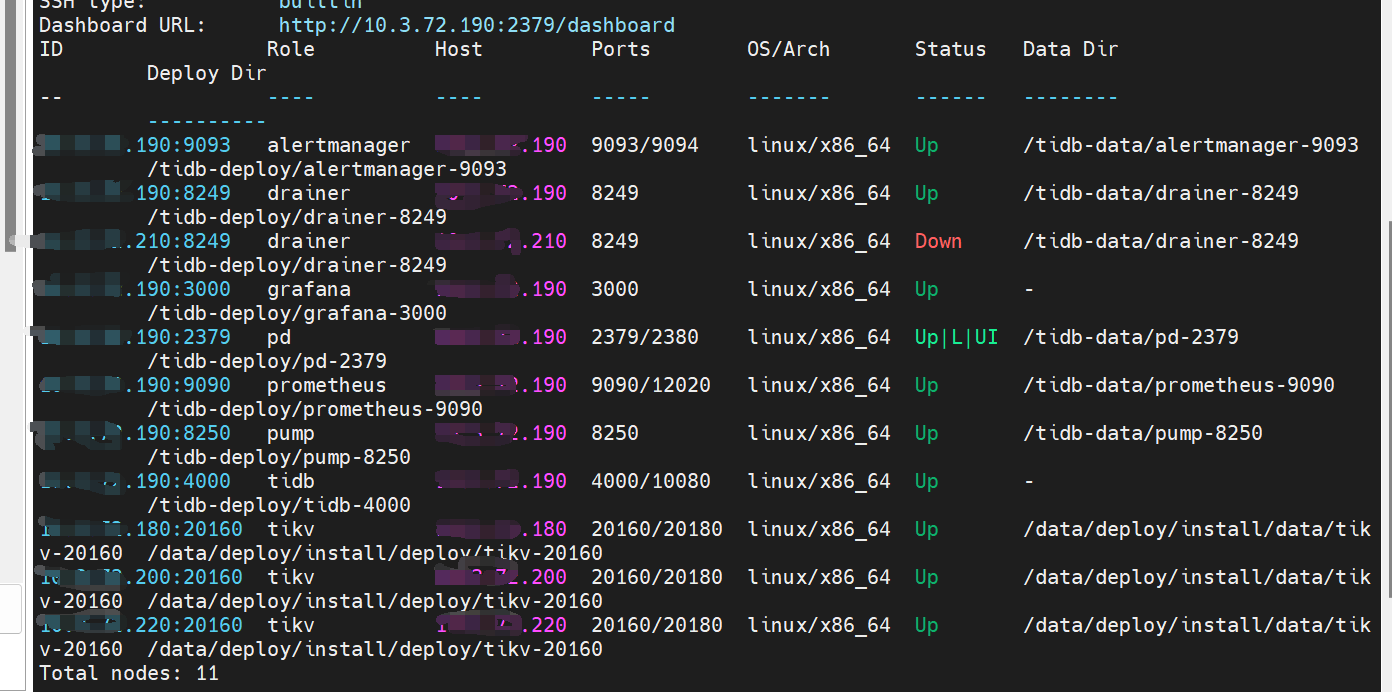
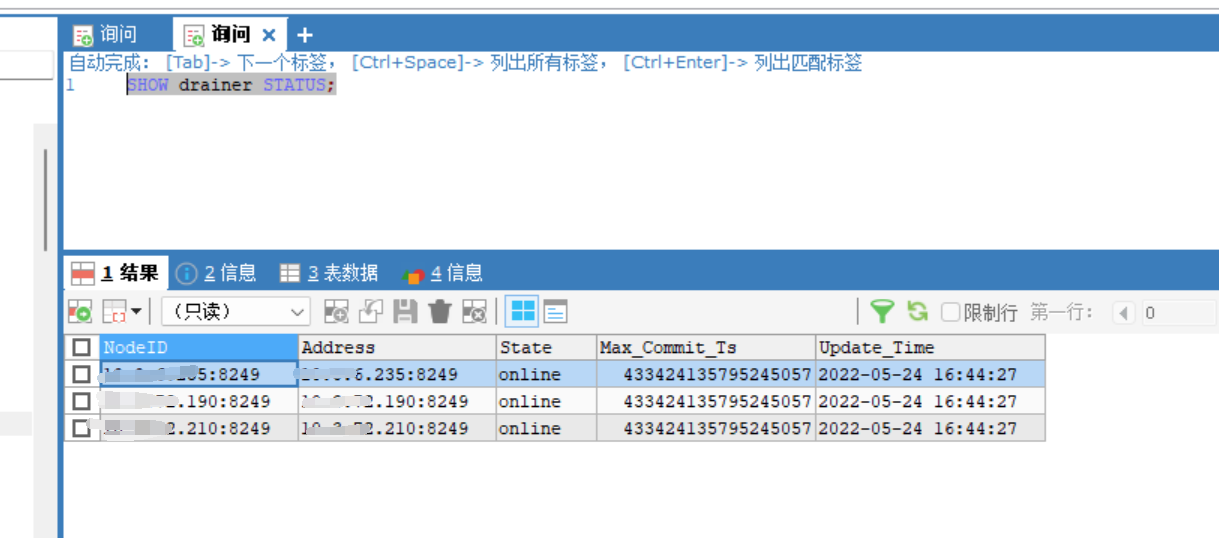
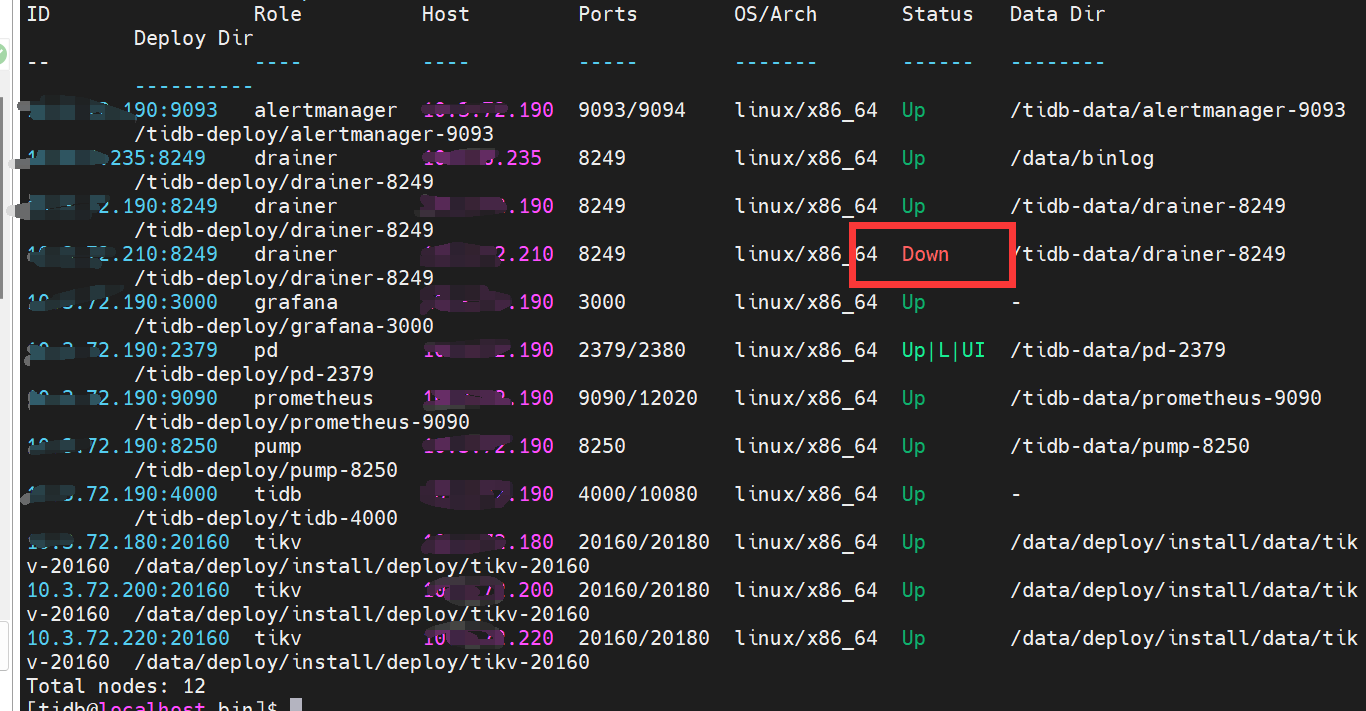
已经部署的集群,扩容了一个pump节点,两个drainer节点,备份下游选择的是file模式,扩容完成后,tiup cluster display tidb_name发现两个drainer节点一个状态为up,一个状态为down
【复现路径】
1/检查了两个dranier生成的文件,发现文件内容一致且正常,无数据丢失
2/检查了两个机器上drainer进程,都存在,ps -ef | grep drainer
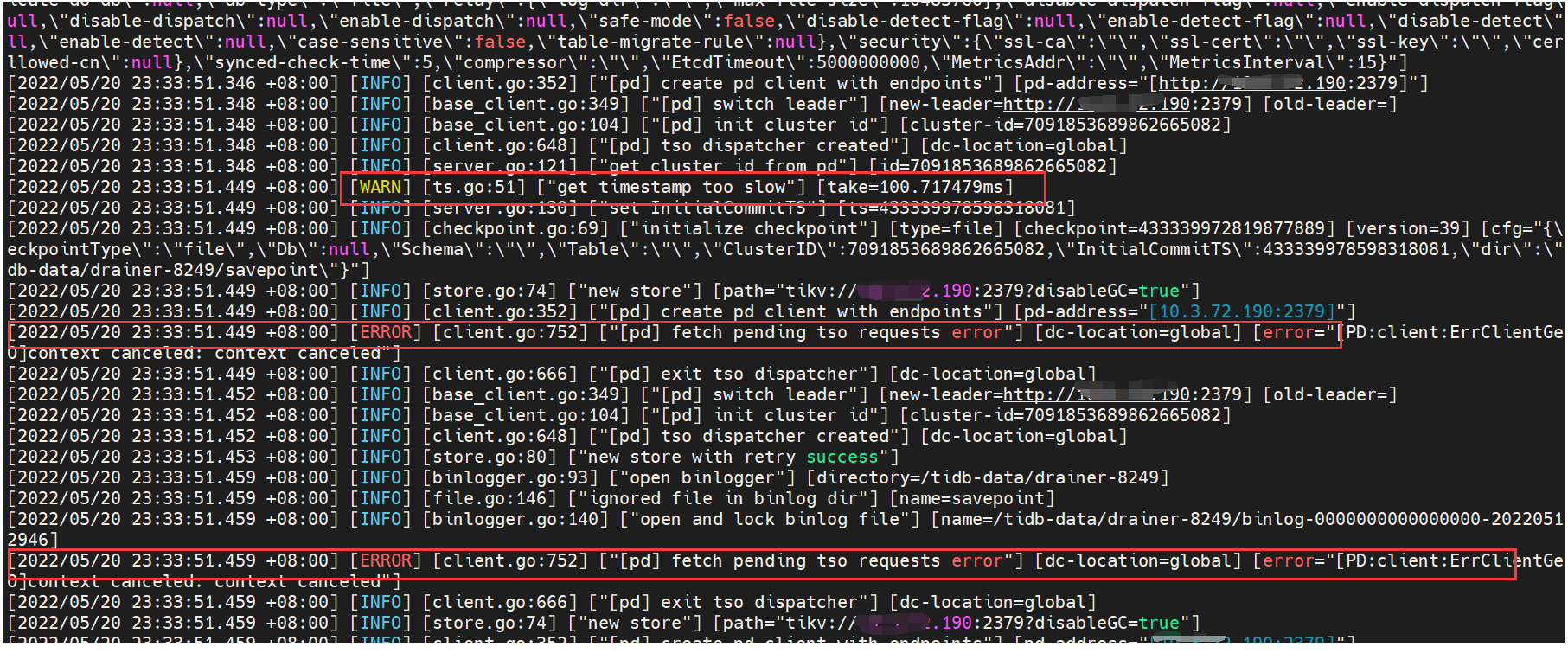
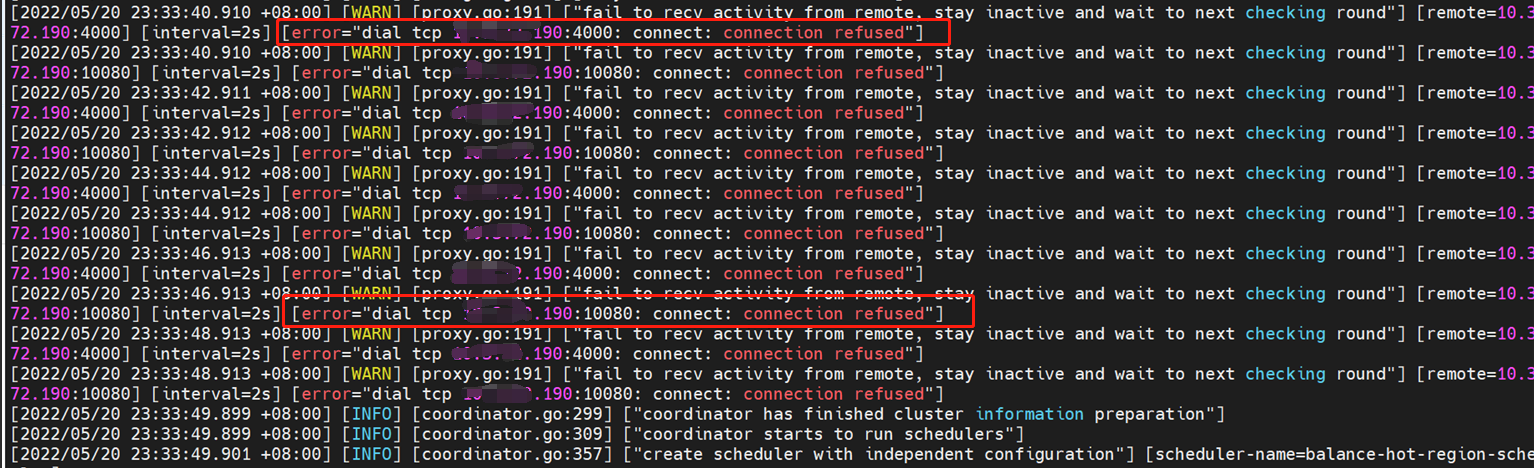
3/检查之前drainer的日志,并发现只要集群时两个drainer在启动时,都会会短暂的报一个pd-client的错误,但是马上会恢复并启动成功,后面正常提供服务并且不报错
4/检查了pd的日志,发现启动时间点,日志有一些报错。
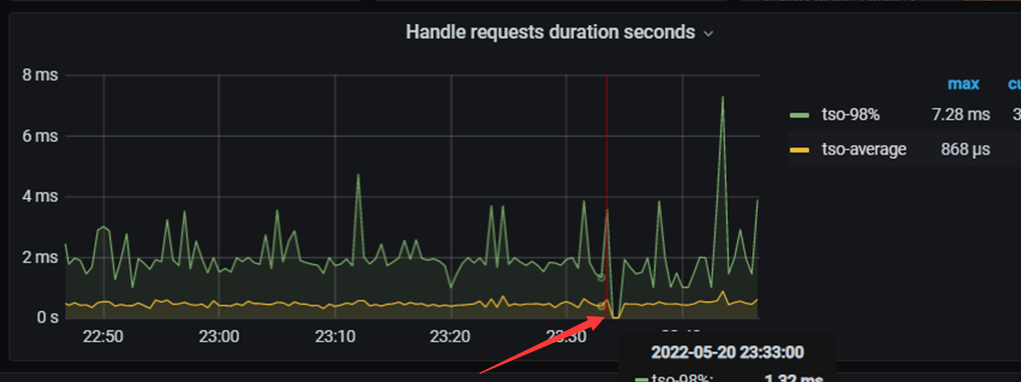
5/监控显示pd在启动一瞬间突然掉底(这里怀疑pd压力过大)
【问题现象及影响】
问题:目前已确定drainer组件正常工作,但是这个display显示有一个drainer状态为down是为什么?
xfworld
(魔幻之翼)
2
5.x drainer 有个tiup 的缺陷,因为 tiup 链接超时的参数和 4.x 有差异,会导致 drainer 请求超时,需要调整 drainer 的超时的参数即可
Root Cause
由于 Drainer 启动服务的时间较长导致,Tiup 等待时间过长报错,截止到 v5.0.1 的版本 tiup cluster 的 wait_timeout 默认 120s 。该问题同样适用于 tiup start 、restart 、reload 等操作。
tiup cluster upgrade --wait-timeout 600
tiup cluster start --wait-timeout 600
tiup cluster restart --wait-timeout 600
tiup cluster reload --wait-timeout 600
1 个赞
问下这个具体去怎么调整drainer的超时参数呢,我这里集群名字是tidb-test,具体用哪个命令呢?
我理解是这么用,tiup cluster restart tidb-test --wait-timeout 600,结果是正常重启了,display还是那样
xfworld
(魔幻之翼)
7
72.190 是个什么节点?PD 么? 又是4000,又是10080 端口
这是什么类型混布? 能不能拆开一下?
这个又和混合部署有关吗,最上面第一张图能看到各组件在哪个机器上啊
xfworld
(魔幻之翼)
9
有的,机器性能如果不能满足配置要求,就会出现各种问题,
另外 dranier 和 pump 都是直接由 PD 来调度的,你也可以通过 binlogctl 来查看一下状态
https://docs.pingcap.com/zh/tidb/stable/maintain-tidb-binlog-cluster#使用-binlogctl-工具管理-pumpdrainer
最后可以通过 dranier 的日志来确认一下问题…
状态都是好的,也是在正常工作,问题只是为什么显示的节点状态是down,
我想的要是性能有问题,他应该不会正常工作,后面也应该会报错
xfworld
(魔幻之翼)
12
嗯,还是tiup 的锅了,这个没辙,新旧版本交替就会有兼容上的问题
5.x 官方推荐用 ticdc,可以考虑下
1 个赞
Min_Chen
(Make the world more reliable)
14
system
(system)
关闭
15
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。