【 TiDB 使用环境】测试环境
【 TiDB 版本】v5.4.0
【遇到的问题】按照文档操作无法修复
【复现路径】按照文档操作
【问题现象及影响】
文档:Online Unsafe Recovery
操作步骤及效果
1.新建表
create table test.t_unsafe_recovery (c int primary key);
insert into test.t_unsafe_recovery values (1), (2), (3);
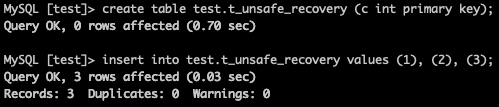
2.查寻表所在的节点
select host.store_id,store_id.region_id,host.address,store_id.is_leader,region.db_name,region.table_name from information_schema.TIKV_REGION_PEERS store_id, information_schema.TIKV_REGION_STATUS region, information_schema.TIKV_STORE_STATUS host where store_id.region_id = region.region_id AND store_id.store_id = host.store_id and region.db_name = ‘test’ and region.table_name = ‘t_unsafe_recovery’;
3.stop掉多数节点
登陆follower节点执行(20162为tikv端口号)
进入tikv-server所在目录
mv tikv-server tikv-server_
ps aux|grep 20162
kill -9 xxxxx
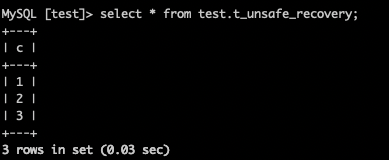
4.查看表数据
select * from test.t_unsafe_recovery;
![]()
5.关闭调度
tiup ctl:v5.4.0 pd -u http://xxxxxx:xxxx -i
»config set region-schedule-limit 0
Success!
»config set replica-schedule-limit 0
Success!
»config set merge-schedule-limit 0
Success!
»unsafe remove-failed-stores show
[
“No on-going operation.”
]
»unsafe remove-failed-stores 1
Success!
»unsafe remove-failed-stores 5
Success!
»unsafe remove-failed-stores show
[
“No on-going operation.”
]
6.关闭的两个tikv节点状态变为
Tombstone
7.查询表数据
![]()
8.停止leader的tikv节点
9.停止pd
10.启动pd
11.启动leader的tikv节点
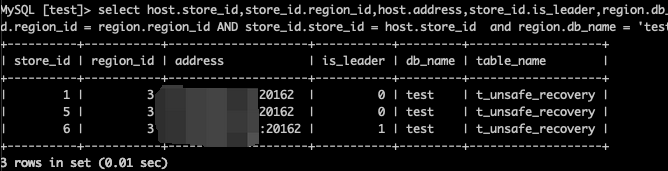
12.查看表所在节点信息(leader标准变为0)
13.查询表数据
![]()
以上就是官方文档所有步骤,但是没有达到预期的效果,表依然无法访问。
通过查询tug,发现还有另外步骤,做如下尝试。
13.停止leader的tikv节点
14.leader的tikv节点上操作
cd /home/tidb
./tikv-ctl --data-dir /data/tidb_cluster/tidb-data/tikv-20162 unsafe-recover remove-fail-stores --all-regions -s 1,5

15.启动leader的tikv节点
16.查询表数据
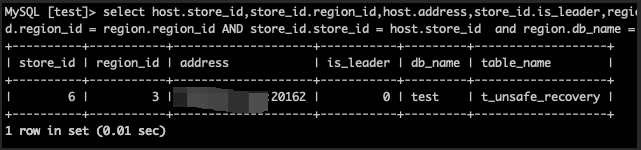
17.查询表所在节点信息(leader标志重新回来)

后续操作
18.清理Tombstone节点
tiup cluster prune xxxx
命令不起作用,通过display之后节点依然存在。
19.pd查看
tiup ctl:v5.4.0 pd -u http://xxxxxxx:xxxx -i
» store
节点信息不存在了
20.tiup中清理
cd .tiup/storage/cluster/clusters/xxxxx/
vim meta.yaml
删除Tombstone的tikv节点信息,再次display之后Tombstone的节点信息消失。
疑问点:
1.按照官方文档并未达到测试目的,是否我的测试环境缺失或者有什么没有达到条件的
2.是否官方文档恢复步骤缺失
3.unsafe remove-failed-stores 1之后Tombstone节点信息是否只能通过修改tiup下面的meta.yaml文件达到清理Tombstone节点信息的目的。