课程名称:PD Control 的典型使用场景
学习时长:60
课程收获:熟练使用 pd-ctl 工具
课程内容:
调度概述
PD 是 TiDB 集群的管理模块,同时也负责集群数据的实时调度。
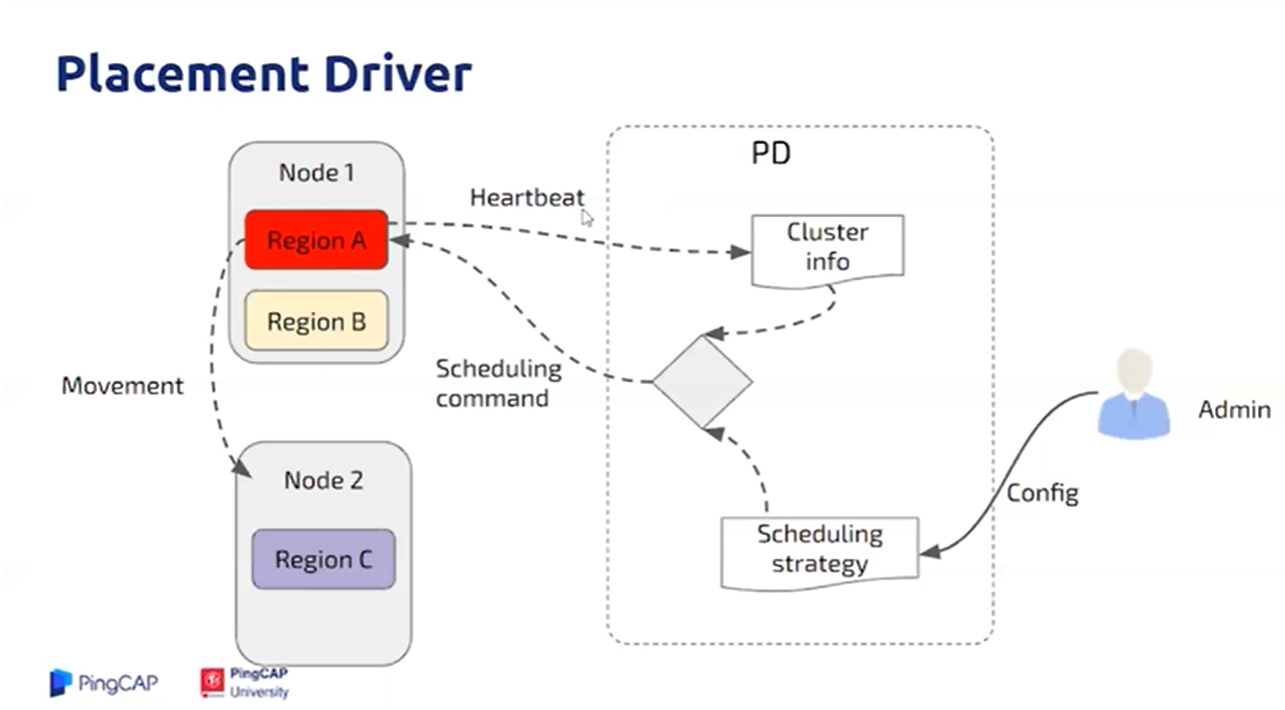
PD Control 适用场景
PD Control 使用说明
PD Control 是 PD 的命令行工具,用于获取集群状态信息和调整集群。
安装方式
使用 TiUP
可直接通过 tiup ctl pd -u http://<pd_ip>:<pd_port> [-i] 使用。
下载安装包
如需下载最新版本的 pd-ctl ,直接下载 TiDB 安装包即可,因为 pd-ctl 包含在 TiDB 安装包中。
| 安装包 | 操作系统 | 架构 | SHA256 校验和 |
|---|---|---|---|
https://download.pingcap.org/tidb-{version}-linux-amd64.tar.gz (pd-ctl) |
Linux | amd64 | https://download.pingcap.org/tidb-{version}-linux-amd64.sha256 |
注意:
下载链接中的
{version}为 TiDB 的版本号。例如v4.0.0-rc.2版本的下载链接为https://download.pingcap.org/tidb-v4.0.0-rc.2-linux-amd64.tar.gz。也可以使用latest替代{version}来下载最新的未发布版本。
源码编译
- Go Version 1.13 以上
- 在 PD 项目根目录使用
make或者make pd-ctl命令进行编译,生成 bin/pd-ctl
简单例子
单命令模式:
Copy
./pd-ctl store -u http://127.0.0.1:2379
交互模式:
Copy
./pd-ctl -i -u http://127.0.0.1:2379
使用环境变量:
Copy
export PD_ADDR=http://127.0.0.1:2379 &&
./pd-ctl
使用 TLS 加密:
Copy
./pd-ctl -u https://127.0.0.1:2379 --cacert="path/to/ca" --cert="path/to/cert" --key="path/to/key"
命令行参数 (flags)
--cacert
- 指定 PEM 格式的受信任 CA 证书的文件路径
- 默认值:“”
--cert
- 指定 PEM 格式的 SSL 证书的文件路径
- 默认值:“”
--detach / -d
- 使用单命令行模式(不进入 readline)
- 默认值: true
--help / -h
- 输出帮助信息
- 默认值:false
--interact / -i
- 使用交互模式(进入 readline)
- 默认值:false
--key
- 指定 PEM 格式的 SSL 证书密钥文件路径,即
--cert所指定的证书的私钥 - 默认值: “”
--pd / -u
- 指定 PD 的地址
- 默认地址:
http://127.0.0.1:2379 - 环境变量:
PD_ADDR
--version / -V
- 打印版本信息并退出
- 默认值: false
命令 (command)
cluster
用于显示集群基本信息。
示例:
Copy
>> cluster
{
"id": 6493707687106161130,
"max_peer_count": 3
}
config [show | set <option> <value> | placement-rules]
用于显示或调整配置信息。示例如下。
显示 scheduling 的相关 config 信息:
Copy
>> config show
{
"replication": {
"enable-placement-rules": "false",
"location-labels": "",
"max-replicas": 3,
"strictly-match-label": "false"
},
"schedule": {
"enable-cross-table-merge": "false",
"enable-debug-metrics": "false",
"enable-location-replacement": "true",
"enable-make-up-replica": "true",
"enable-one-way-merge": "false",
"enable-remove-down-replica": "true",
"enable-remove-extra-replica": "true",
"enable-replace-offline-replica": "true",
"high-space-ratio": 0.7,
"hot-region-cache-hits-threshold": 3,
"hot-region-schedule-limit": 4,
"leader-schedule-limit": 4,
"leader-schedule-policy": "count",
"low-space-ratio": 0.8,
"max-merge-region-keys": 200000,
"max-merge-region-size": 20,
"max-pending-peer-count": 16,
"max-snapshot-count": 3,
"max-store-down-time": "30m0s",
"merge-schedule-limit": 8,
"patrol-region-interval": "100ms",
"region-schedule-limit": 2048,
"replica-schedule-limit": 64,
"scheduler-max-waiting-operator": 5,
"split-merge-interval": "1h0m0s",
"store-limit-mode": "manual",
"tolerant-size-ratio": 0
}
}

显示所有的 config 信息:
Copy
>> config show all
显示 replication 的相关 config 信息:
Copy
>> config show replication
{
"max-replicas": 3,
"location-labels": "",
"strictly-match-label": "false",
"enable-placement-rules": "false"
}
显示目前集群版本,是目前集群 TiKV 节点的最低版本,并不对应 binary 的版本:
Copy
>> config show cluster-version
"4.0.0"
max-snapshot-count控制单个 store 最多同时接收或发送的 snapshot 数量,调度受制于这个配置来防止抢占正常业务的资源。 当需要加快补副本或 balance 速度时可以调大这个值。
设置最大 snapshot 为 16:
>> config set max-snapshot-count 16
max-pending-peer-count控制单个 store 的 pending peer 上限,调度受制于这个配置来防止在部分节点产生大量日志落后的 Region。需要加快补副本或 balance 速度可以适当调大这个值,设置为 0 则表示不限制。设置最大 pending peer 数量为 64:Copy
>> config set max-pending-peer-count 64
max-merge-region-size控制 Region Merge 的 size 上限(单位是 M)。当 Region Size 大于指定值时 PD 不会将其与相邻的 Region 合并。设置为 0 表示不开启 Region Merge 功能。设置 Region Merge 的 size 上限为 16 M:Copy
>> config set max-merge-region-size 16
max-merge-region-keys控制 Region Merge 的 keyCount 上限。当 Region KeyCount 大于指定值时 PD 不会将其与相邻的 Region 合并。设置 Region Merge 的 keyCount 上限为 50000:Copy
>> config set max-merge-region-keys 50000
split-merge-interval控制对同一个 Region 做split和merge操作的间隔,即对于新split的 Region 一段时间内不会被merge。设置split和merge的间隔为 1 天:Copy
>> config set split-merge-interval 24h
enable-one-way-merge用于控制是否只允许和相邻的后一个 Region 进行合并。当设置为false时,PD 允许与相邻的前后 Region 进行合并。设置只允许和相邻的后一个 Region 合并:Copy
>> config set enable-one-way-merge true
enable-cross-table-merge用于开启跨表 Region 的合并。当设置为false时,PD 不会合并不同表的 Region。该选项只在键类型为 “table” 时生效。设置允许跨表合并:Copy
>> config set enable-cross-table-merge true
key-type用于指定集群的键编码类型。支持的类型有["table", "raw", "txn"],默认值为 “table”。- 如果集群中不存在 TiDB 实例,
key-type的值为 “raw” 或 “txn”。此时,无论enable-cross-table-merge设置为何,PD 均可以跨表合并 Region。 - 如果集群中存在 TiDB 实例,
key-type的值应当为 “table”。此时,enable-cross-table-merge的设置决定了 PD 是否能跨表合并 Region。如果key-type的值为 “raw”,placement rules 不生效。启用跨表合并:Copy
- 如果集群中不存在 TiDB 实例,
>> config set key-type raw
patrol-region-interval控制 replicaChecker 检查 Region 健康状态的运行频率,越短则运行越快,通常状况不需要调整。设置 replicaChecker 的运行频率为 10 毫秒:Copy
>> config set patrol-region-interval 10ms
max-store-down-time为 PD 认为失联 store 无法恢复的时间,当超过指定的时间没有收到 store 的心跳后,PD 会在其他节点补充副本。设置 store 心跳丢失 30 分钟开始补副本:Copy
>> config set max-store-down-time 30m
- 通过调整
leader-schedule-limit可以控制同时进行 leader 调度的任务个数。 这个值主要影响 leader balance 的速度,值越大调度得越快,设置为 0 则关闭调度。 Leader 调度的开销较小,需要的时候可以适当调大。
最多同时进行 4 个 leader 调度:
>> config set leader-schedule-limit 4
- 通过调整
region-schedule-limit可以控制同时进行 Region 调度的任务个数。这个值可以避免创建过多的 Region balance operator。默认值为2048,对所有大小的集群都足够。设置为0则关闭调度。Region 调度的速度通常受到store-limit的限制,但除非你熟悉该设置,否则不推荐自定义该参数。最多同时进行 2 个 Region 调度:Copy
>> config set region-schedule-limit 2
- 通过调整
replica-schedule-limit可以控制同时进行 replica 调度的任务个数。这个值主要影响节点挂掉或者下线的时候进行调度的速度,值越大调度得越快,设置为 0 则关闭调度。Replica 调度的开销较大,所以这个值不宜调得太大。最多同时进行 4 个 replica 调度:Copy
>> config set replica-schedule-limit 4
merge-schedule-limit控制同时进行的 Region Merge 调度的任务,设置为 0 则关闭 Region Merge。Merge 调度的开销较大,所以这个值不宜调得过大。最多同时进行 16 个 merge 调度:Copy
>> config set merge-schedule-limit 16
hot-region-schedule-limit控制同时进行的 Hot Region 调度的任务,设置为 0 则关闭调度。这个值不宜调得过大,否则可能对系统性能造成影响。最多同时进行 4 个 Hot Region 调度:Copy
>> config set hot-region-schedule-limit 4
hot-region-cache-hits-threshold用于设置热点 Region 的阈值,只有命中 cache 的次数超过这个阈值才会被当作热点。tolerant-size-ratio控制 balance 缓冲区大小。当两个 store 的 leader 或 Region 的得分差距小于指定倍数的 Region size 时,PD 会认为此时 balance 达到均衡状态。设置缓冲区为约 20 倍平均 RegionSize:Copy
>> config set tolerant-size-ratio 20
low-space-ratio用于设置 store 空间不足的阈值。当节点的空间占用比例超过指定值时,PD 会尽可能避免往对应节点迁移数据,同时主要针对剩余空间大小进行调度,避免对应节点磁盘空间被耗尽。设置空间不足阈值为 0.9:Copy
config set low-space-ratio 0.9
high-space-ratio用于设置 store 空间充裕的阈值。当节点的空间占用比例小于指定值时,PD 调度时会忽略剩余空间这个指标,主要针对实际数据量进行均衡。设置空间充裕阈值为 0.5:Copy
config set high-space-ratio 0.5
cluster-version集群的版本,用于控制某些 Feature 是否开启,处理兼容性问题。通常是集群正常运行的所有 TiKV 节点中的最低版本,需要回滚到更低的版本时才进行手动设置。设置 cluster version 为 1.0.8:Copy
config set cluster-version 1.0.8
leader-schedule-policy用于选择 Leader 的调度策略,可以选择按照size或者count来进行调度。scheduler-max-waiting-operator用于控制每个调度器同时存在的 operator 的个数。enable-remove-down-replica用于开启自动删除 DownReplica 的特性。当设置为 false 时,PD 不会自动清理宕机状态的副本。enable-replace-offline-replica用于开启迁移 OfflineReplica 的特性。当设置为 false 时,PD 不会迁移下线状态的副本。enable-make-up-replica用于开启补充副本的特性。当设置为 false 时,PD 不会为副本数不足的 Region 补充副本。enable-remove-extra-replica用于开启删除多余副本的特性。当设置为 false 时,PD 不会为副本数过多的 Region 删除多余副本。enable-location-replacement用于开启隔离级别检查。当设置为 false 时,PD 不会通过调度来提升 Region 副本的隔离级别。enable-debug-metrics用于开启 debug 的 metrics。当设置为 true 时,PD 会开启一些 metrics,比如balance-tolerant-size等。enable-placement-rules用于开启 placement rules。store-limit-mode用于控制 store 限速机制的模式。主要有两种模式:auto和manual。auto模式下会根据 load 自动进行平衡调整(实验性功能)。
config placement-rules [disable | enable | load | save | show]
关于 config placement-rules 的具体用法,参考 Placement Rules 使用文档。
health
用于显示集群健康信息。示例如下。
显示健康信息:
Copy
>> health
[
{
"name": "pd",
"member_id": 13195394291058371180,
"client_urls": [
"http://127.0.0.1:2379"
......
],
"health": true
}
......
]
hot [read | write | store]
用于显示集群热点信息。示例如下。
显示读热点信息:
Copy
>> hot read
显示写热点信息:
Copy
>> hot write
显示所有 store 的读写信息:
Copy
>> hot store
label [store <name> <value>]
用于显示集群标签信息。示例如下。
显示所有 label:
Copy
>> label
显示所有包含 label 为 “zone”:“cn” 的 store:
Copy
>> label store zone cn
member [delete | leader_priority | leader [show | resign | transfer <member_name>]]
用于显示 PD 成员信息,删除指定成员,设置成员的 leader 优先级。示例如下。
显示所有成员的信息:
Copy
>> member
{
"header": {......},
"members": [......],
"leader": {......},
"etcd_leader": {......},
}
下线 “pd2”:
Copy
>> member delete name pd2
Success!
使用 id 下线节点:
Copy
>> member delete id 1319539429105371180
Success!
显示 leader 的信息:
Copy
>> member leader show
{
"name": "pd",
"member_id": 13155432540099656863,
"peer_urls": [......],
"client_urls": [......]
}
将 leader 从当前成员移走:
Copy
>> member leader resign
......
将 leader 迁移至指定成员:
Copy
>> member leader transfer pd3
......
operator [check | show | add | remove]
用于显示和控制调度操作。
示例:
Copy
>> operator show // 显示所有的 operators
>> operator show admin // 显示所有的 admin operators
>> operator show leader // 显示所有的 leader operators
>> operator show region // 显示所有的 Region operators
>> operator add add-peer 1 2 // 在 store 2 上新增 Region 1 的一个副本
>> operator add add-learner 1 2 // 在 store 2 上新增 Region 1 的一个 learner 副本
>> operator add remove-peer 1 2 // 移除 store 2 上的 Region 1 的一个副本
>> operator add transfer-leader 1 2 // 把 Region 1 的 leader 调度到 store 2
>> operator add transfer-region 1 2 3 4 // 把 Region 1 调度到 store 2,3,4
>> operator add transfer-peer 1 2 3 // 把 Region 1 在 store 2 上的副本调度到 store 3
>> operator add merge-region 1 2 // 将 Region 1 与 Region 2 合并
>> operator add split-region 1 --policy=approximate // 将 Region 1 对半拆分成两个 Region,基于粗略估计值
>> operator add split-region 1 --policy=scan // 将 Region 1 对半拆分成两个 Region,基于精确扫描值
>> operator remove 1 // 把 Region 1 的调度操作删掉
>> operator check 1 // 查看 Region 1 相关 operator 的状态
其中,Region 的分裂都是尽可能地从靠近中间的位置开始。对这个位置的选择支持两种策略,即 scan 和 approximate。它们之间的区别是,前者通过扫描这个 Region 的方式来确定中间的 key,而后者是通过查看 SST 文件中记录的统计信息,来得到近似的位置。一般来说,前者更加精确,而后者消耗更少的 I/O,可以更快地完成。
ping
用于显示 ping PD 所需要花费的时间
示例:
Copy
>> ping
time: 43.12698ms
region <region_id> [--jq="<query string>"]
用于显示 Region 信息。使用 jq 格式化输出请参考 jq-格式化-json-输出示例。示例如下。
显示所有 Region 信息:
Copy
>> region
{
"count": 1,
"regions": [......]
}
显示 Region id 为 2 的信息:
Copy
>> region 2
{
"id": 2,
"start_key": "7480000000000000FF1D00000000000000F8",
"end_key": "7480000000000000FF1F00000000000000F8",
"epoch": {
"conf_ver": 1,
"version": 15
},
"peers": [
{
"id": 40,
"store_id": 3
}
],
"leader": {
"id": 40,
"store_id": 3
},
"written_bytes": 0,
"read_bytes": 0,
"written_keys": 0,
"read_keys": 0,
"approximate_size": 1,
"approximate_keys": 0
}
region key [--format=raw|encode|hex] <key>
用于查询某个 key 位于哪一个 Region 上,支持 raw、encoding 和 hex 格式。使用 encoding 格式时,key 需要使用单引号。
Hex 格式(默认)示例:
Copy
>> region key 7480000000000000FF1300000000000000F8
{
"region": {
"id": 2,
......
}
}
Raw 格式示例:
Copy
>> region key --format=raw abc
{
"region": {
"id": 2,
......
}
}
Encoding 格式示例:
Copy
>> region key --format=encode 't\200\000\000\000\000\000\000\377\035_r\200\000\000\000\000\377\017U\320\000\000\000\000\000\372'
{
"region": {
"id": 2,
......
}
}
region scan
用于获取所有 Region。
示例:
Copy
>> region scan
{
"count": 20,
"regions": [......],
}
region sibling <region_id>
用于查询某个 Region 相邻的 Region。
示例:
Copy
>> region sibling 2
{
"count": 2,
"regions": [......],
}
region startkey [--format=raw|encode|hex] <key> <limit>
用于查询从某个 key 开始的所有 Region。
示例:
Copy
>> region startkey --format=raw abc
{
"count": 16,
"regions": [......],
}
region store <store_id>
用于查询某个 store 上面所有的 Region。
示例:
Copy
>> region store 2
{
"count": 10,
"regions": [......],
}
region topread [limit]
用于查询读流量最大的 Region。limit 的默认值是 16。
示例:
Copy
>> region topread
{
"count": 16,
"regions": [......],
}
region topwrite [limit]
用于查询写流量最大的 Region。limit 的默认值是 16。
示例:
Copy
>> region topwrite
{
"count": 16,
"regions": [......],
}
region topconfver [limit]
用于查询 conf version 最大的 Region。limit 的默认值是 16。
示例:
Copy
>> region topconfver
{
"count": 16,
"regions": [......],
}
region topversion [limit]
用于查询 version 最大的 Region。limit 的默认值是 16。
示例:
Copy
>> region topversion
{
"count": 16,
"regions": [......],
}
region topsize [limit]
用于查询 approximate size 最大的 Region。limit 的默认值是 16。
示例:
Copy
>> region topsize
{
"count": 16,
"regions": [......],
}
region check [miss-peer | extra-peer | down-peer | pending-peer | offline-peer | empty-region | hist-size | hist-keys]
用于查询处于异常状态的 Region,各类型的意义如下
- miss-peer:缺副本的 Region
- extra-peer:多副本的 Region
- down-peer:有副本状态为 Down 的 Region
- pending-peer:有副本状态为 Pending 的 Region
示例:
Copy
>> region check miss-peer
{
"count": 2,
"regions": [......],
}
scheduler [show | add | remove | pause | resume | config]
用于显示和控制调度策略。
示例:
Copy
>> scheduler show // 显示所有的 schedulers
>> scheduler add grant-leader-scheduler 1 // 把 store 1 上的所有 Region 的 leader 调度到 store 1
>> scheduler add evict-leader-scheduler 1 // 把 store 1 上的所有 Region 的 leader 从 store 1 调度出去
>> scheduler config evict-leader-scheduler // v4.0.0 起,展示该调度器具体在哪些 store 上
>> scheduler add shuffle-leader-scheduler // 随机交换不同 store 上的 leader
>> scheduler add shuffle-region-scheduler // 随机调度不同 store 上的 Region
>> scheduler remove grant-leader-scheduler-1 // 把对应的调度器删掉,`-1` 对应 store ID
>> scheduler pause balance-region-scheduler 10 // 暂停运行 balance-region 调度器 10 秒
>> scheduler pause all 10 // 暂停运行所有的调度器 10 秒
>> scheduler resume balance-region-scheduler // 继续运行 balance-region 调度器
>> scheduler resume all // 继续运行所有的调度器
>> scheduler config balance-hot-region-scheduler // 显示 balance-hot-region 调度器的配置
scheduler config balance-hot-region-scheduler
用于查看和控制 balance-hot-region-scheduler 策略。
示例:
>> scheduler config balance-hot-region-scheduler // 显示 balance-hot-region 调度器的所有配置
{
"min-hot-byte-rate": 100,
"min-hot-key-rate": 10,
"max-zombie-rounds": 3,
"max-peer-number": 1000,
"byte-rate-rank-step-ratio": 0.05,
"key-rate-rank-step-ratio": 0.05,
"count-rank-step-ratio": 0.01,
"great-dec-ratio": 0.95,
"minor-dec-ratio": 0.99,
"src-tolerance-ratio": 1.02,
"dst-tolerance-ratio": 1.02
}
min-hot-byte-rate指计数的最小字节,通常为 100。
>> scheduler config balance-hot-region-scheduler set min-hot-byte-rate 100
min-hot-key-rate指计数的最小 key,通常为 10。
>> scheduler config balance-hot-region-scheduler set min-hot-key-rate 10
max-zombie-rounds指一个 operator 可被纳入 pending influence 所允许的最大心跳次数。如果将它设置为更大的值,更多的 operator 可能会被纳入 pending influence。通常用户不需要修改这个值。pending influence 指的是在调度中产生的、但仍生效的影响。
>> scheduler config balance-hot-region-scheduler set max-zombie-rounds 3
max-peer-number指最多要被解决的 peer 数量。这个配置可避免调度器处理速度过慢。
>> scheduler config balance-hot-region-scheduler set max-peer-number 1000
byte-rate-rank-step-ratio、key-rate-rank-step-ratio和count-rank-step-ratio分别控制 byte、key、count 的 step ranks。rank step ratio 决定了计算 rank 时的 step 值。great-dec-ratio和minor-dec-ratio控制dec的 rank。通常用户不需要修改这些配置项。
>> scheduler config balance-hot-region-scheduler set byte-rate-rank-step-ratio 0.05
src-tolerance-ratio和dst-tolerance-ratio是期望调度器的配置项。tolerance-ratio的值越小,调度就越容易。当出现冗余调度时,你可以适当调大这个值。
>> scheduler config balance-hot-region-scheduler set src-tolerance-ratio 1.05
store [delete | label | weight | remove-tombstone | limit | limit-scene] <store_id> [--jq="<query string>"]
用于显示 store 信息或者删除指定 store。使用 jq 格式化输出请参考 jq-格式化-json-输出示例。示例如下。
显示所有 store 信息:
Copy
>> store
{
"count": 3,
"stores": [...]
}
获取 store id 为 1 的 store:
Copy
>> store 1
......
下线 store id 为 1 的 store:
Copy
>> store delete 1
......
设置 store id 为 1 的 store 的键为 “zone” 的 label 的值为 “cn”:
Copy
>> store label 1 zone cn
设置 store id 为 1 的 store 的 leader weight 为 5,Region weight 为 10:
Copy
>> store weight 1 5 10
Copy
>> store remove-tombstone // 删除所有 tombstone 状态的 store
>> store limit-scene // 显示所有的限速场景(实验性功能)
{
"Idle": 100,
"Low": 50,
"Normal": 32,
"High": 12
}
>> store limit-scene idle 100 // 设置 load 为 idle 场景下,添加/删除 peer 的速度上限为每分钟 100 个
store limit 的用法见 Store Limit。
log [fatal | error | warn | info | debug]
用于设置 PD leader 的日志级别。
Copy
>> log warn
tso
用于解析 TSO 到物理时间和逻辑时间。示例如下。
解析 TSO:
Copy
>> tso 395181938313123110
system: 2017-10-09 05:50:59 +0800 CST
logic: 120102
jq 格式化 json 输出示例
简化 store 的输出
Copy
» store --jq=".stores[].store | { id, address, state_name}"
{"id":1,"address":"127.0.0.1:20161","state_name":"Up"}
{"id":30,"address":"127.0.0.1:20162","state_name":"Up"}
...
查询节点剩余空间
Copy
» store --jq=".stores[] | {id: .store.id, available: .status.available}"
{"id":1,"available":"10 GiB"}
{"id":30,"available":"10 GiB"}
...
查询 Region 副本的分布情况
Copy
» region --jq=".regions[] | {id: .id, peer_stores: [.peers[].store_id]}"
{"id":2,"peer_stores":[1,30,31]}
{"id":4,"peer_stores":[1,31,34]}
...
根据副本数过滤 Region
例如副本数不为 3 的所有 Region:
Copy
» region --jq=".regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(length != 3)}"
{"id":12,"peer_stores":[30,32]}
{"id":2,"peer_stores":[1,30,31,32]}
根据副本 store ID 过滤 Region
例如在 store30 上有副本的所有 Region:
Copy
» region --jq=".regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(any(.==30))}"
{"id":6,"peer_stores":[1,30,31]}
{"id":22,"peer_stores":[1,30,32]}
...
还可以像这样找出在 store30 或 store31 上有副本的所有 Region:
Copy
» region --jq=".regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(any(.==(30,31)))}"
{"id":16,"peer_stores":[1,30,34]}
{"id":28,"peer_stores":[1,30,32]}
{"id":12,"peer_stores":[30,32]}
...
恢复数据时寻找相关 Region
例如当 [store1, store30, store31] 宕机时不可用时,我们可以通过查找所有 Down 副本数量大于正常副本数量的所有 Region:
Copy
» region --jq=".regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(length as $total | map(if .==(1,30,31) then . else empty end) | length>=$total-length) }"
{"id":2,"peer_stores":[1,30,31,32]}
{"id":12,"peer_stores":[30,32]}
{"id":14,"peer_stores":[1,30,32]}
...
或者在 [store1, store30, store31] 无法启动时,找出 store1 上可以安全手动移除数据的 Region。我们可以这样过滤出所有在 store1 上有副本并且没有其他 DownPeer 的 Region:
Copy
» region --jq=".regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(length>1 and any(.==1) and all(.!=(30,31)))}"
{"id":24,"peer_stores":[1,32,33]}
在 [store30, store31] 宕机时,找出能安全地通过创建 remove-peer Operator 进行处理的所有 Region,即有且仅有一个 DownPeer 的 Region:
Copy
» region --jq=".regions[] | {id: .id, remove_peer: [.peers[].store_id] | select(length>1) | map(if .==(30,31) then . else empty end) | select(length==1)}"
{"id":12,"remove_peer":[30]}
{"id":4,"remove_peer":[31]}
{"id":22,"remove_peer":[30]}
...