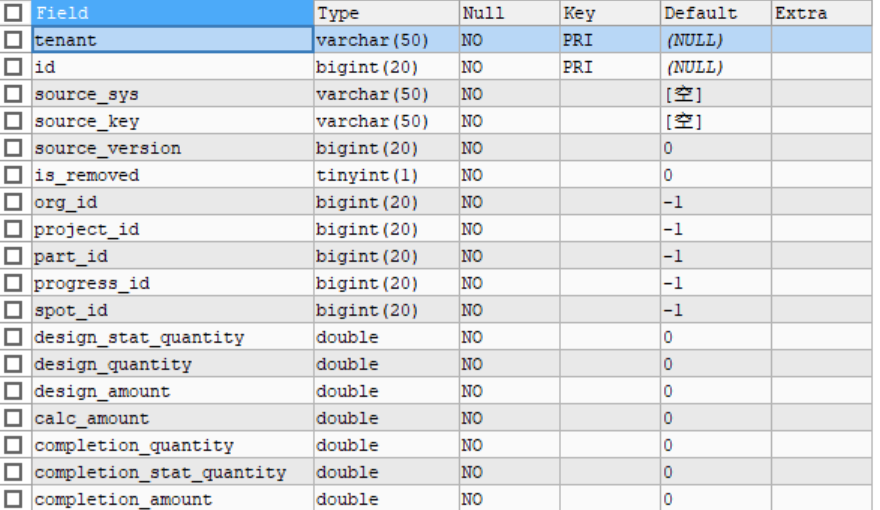
版本: 5.4
SQL(简化后):
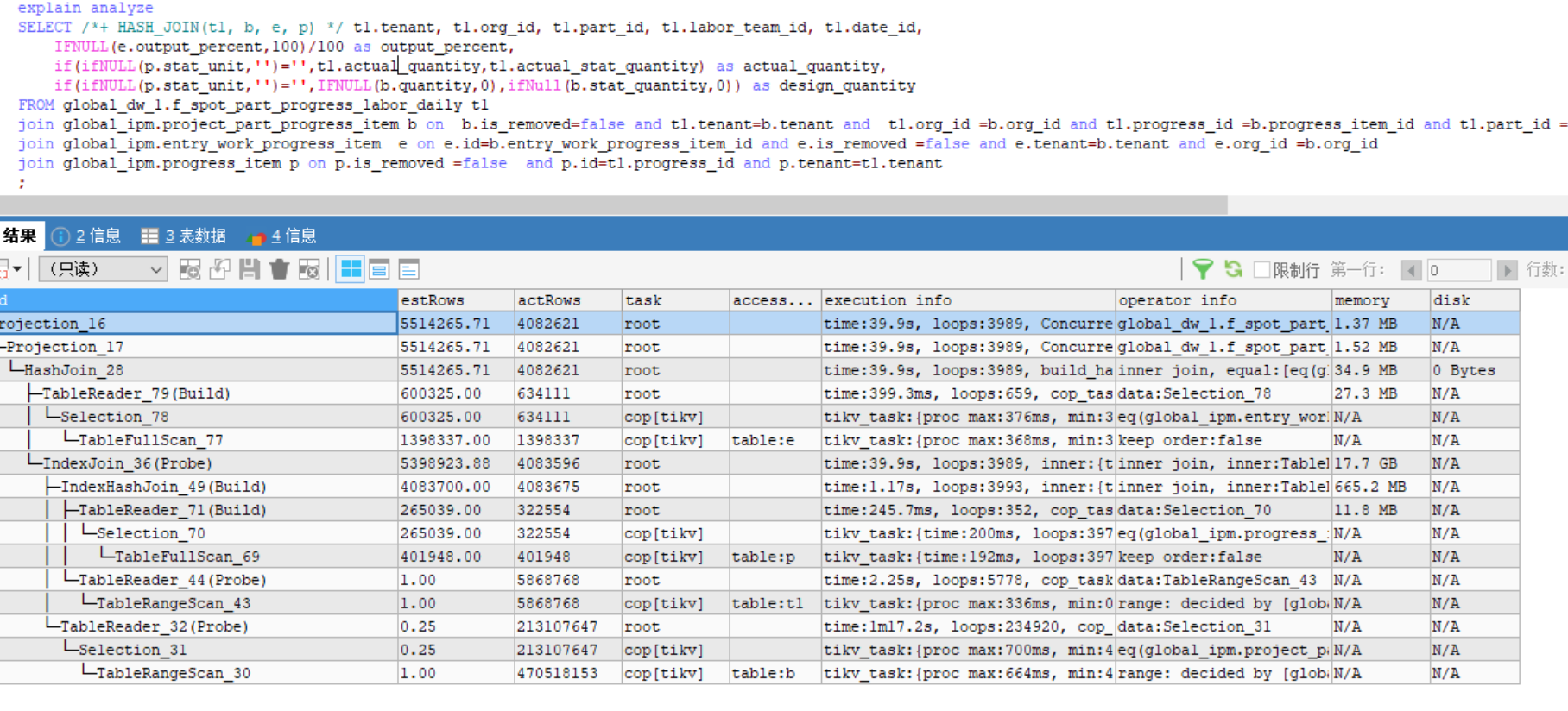
explain analyze
select t1.id, t2.id from global_dwb.f_record_progress t1
join global_dwb.f_spot_part_progress t2 on t2.tenant = t1.tenant and t2.org_id = t1.org_id and t2.part_id = t1.part_id and t2.spot_id = t1.spot_id and t2.progress_id = t1.progress_id
数据量:
t1 (f_record_progress) 521万
t2 (f_spot_part_progress) 1156万
使用tiflash引擎跑:
使用tikv引擎跑:
问题:
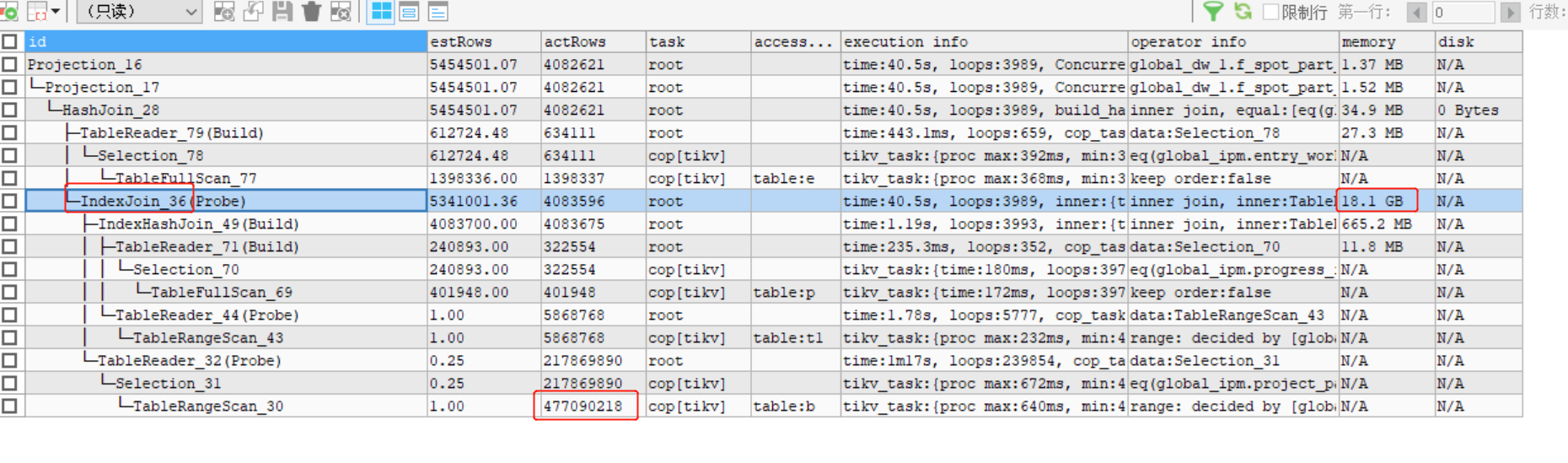
实际的SQL是出现在update中的,所以只能用到tikv引擎,一跑就OOM了
感觉明显的执行计划不对劲,时间很长而且占用内存非常多
这是什么原因呢?有没有办法解决?
xfworld
(魔幻之翼)
2
tikv 明显是把数据 都聚合到 tidb 在进行筛选的,
- 没有索引么?
- 表的健康度不对
建议先对解决表健康度的问题,然后可以考虑通过索引的方式进行配对,减少回表操作
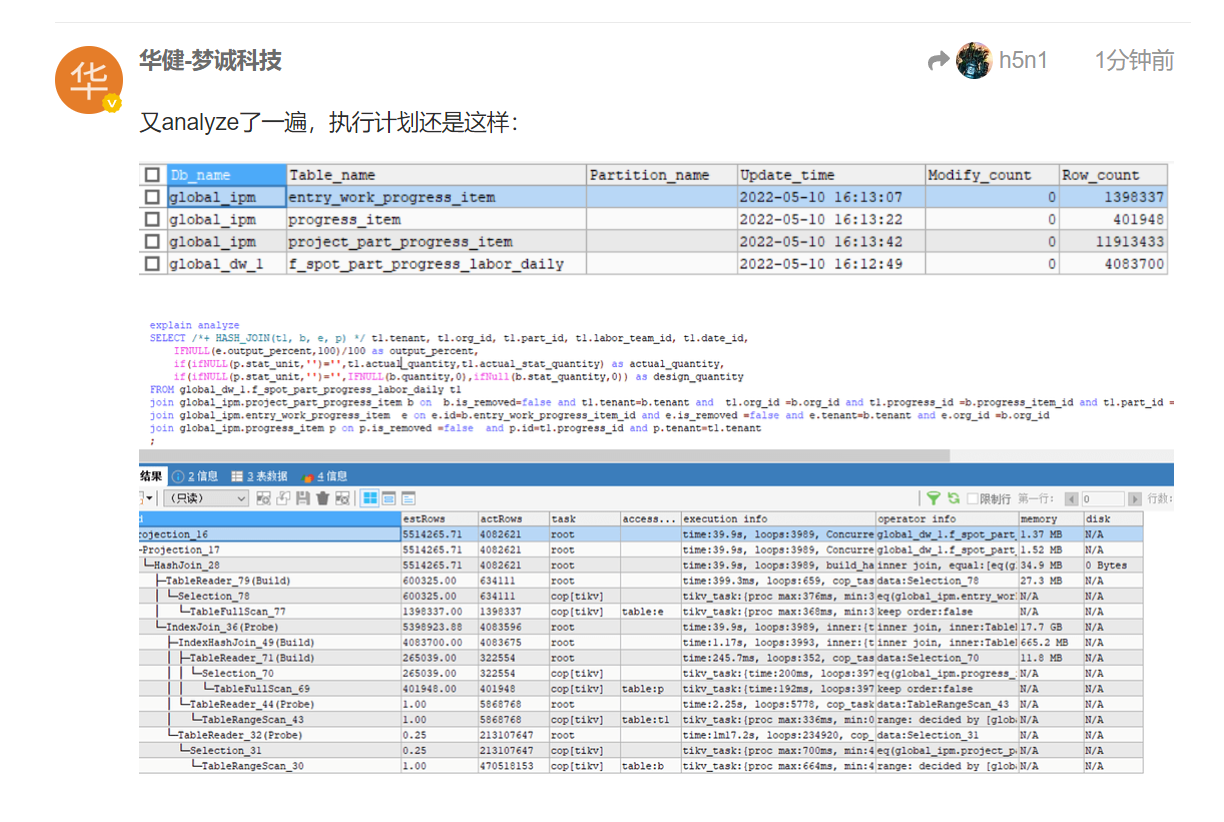
表的健康度怎么看?是看统计信息这里吗?
索引确实没有,因为类似的表和sql特别多,不想所有用于关联的字段都加上索引,太大
就算是都取到tidb里,这个表一共1156万行,实际取的行数是1.8亿,不太对劲呢
xfworld
(魔幻之翼)
4
张雨齐0720
(Zhangjig)
5
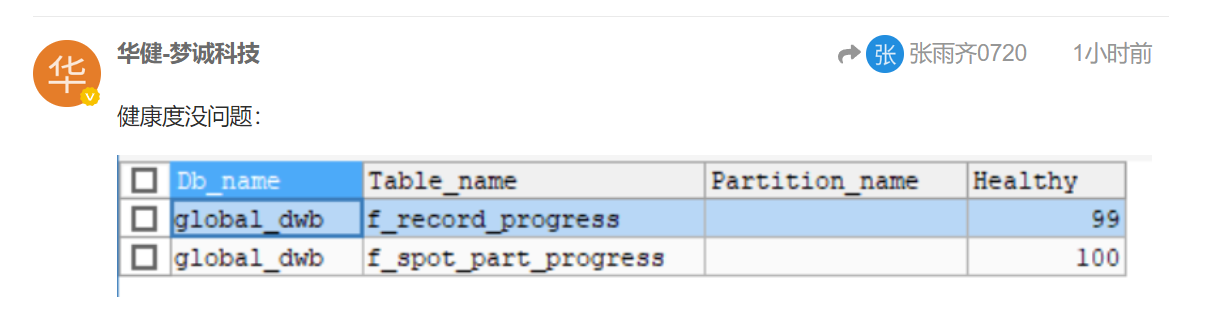
表的健康度信息
通过 SHOW STATS_HEALTHY 可以查看表的统计信息健康度,并粗略估计表上统计信息的准确度。当 modify_count >= row_count 时,健康度为 0;当 modify_count < row_count 时,健康度为 (1 - modify_count / row_count ) * 100。
语法如下:
Copy
SHOW STATS_HEALTHY [ShowLikeOrWhere];
官方文档见以下地址:
https://docs.pingcap.com/zh/tidb/stable/statistics#表的健康度信息
张雨齐0720
(Zhangjig)
6
在上个简单表结构,看看索引,主键情况。
表结构涉密的话,show index from tablename;也可以
我改写了一下SQL,用CTE的方式先把t2取到内存中,再去join,看着就比较正常了
所以我认为,原始SQL的执行计划规划的是有bug的
可能是想进行一定程度的优化,但是没做好,反而取了更多次重复的数据,导致oom
explain analyze
with t2 as
(
select tenant, id, org_id, part_id, spot_id, progress_id, design_stat_quantity, design_quantity, design_amount
from global_dwb.f_spot_part_progress
)
select t1.id, t2.id from global_dwb.f_record_progress t1
join t2 on t2.tenant = t1.tenant and t2.org_id = t1.org_id and t2.part_id = t1.part_id
and t2.spot_id = t1.spot_id and t2.progress_id = t1.progress_id
h5n1
(H5n1)
9
建表时是聚簇表clustered吗? 怎么全表扫描走了个Index_join。 加上 ```
/*+ HASH_JOIN(t1, t2) */

加上解决了:
是聚簇索引:
是什么原因造成用了index_join的呢?
我是从其他库迁移到tidb的,有大量这样的sql,每个都这么改一下工作量太大了
有没有全局更改的方案?
h5n1
(H5n1)
11
执行过analyze table 收集2个表的统计信息吗? 看你的执行计划最初的estRows和actRows差别很大,后面的一致了,如果收集过试试不加hint是否有问题?
再请教下,如果有多个表join,这个hint应该咋写?
我这么写好像没用:
h5n1
(H5n1)
14
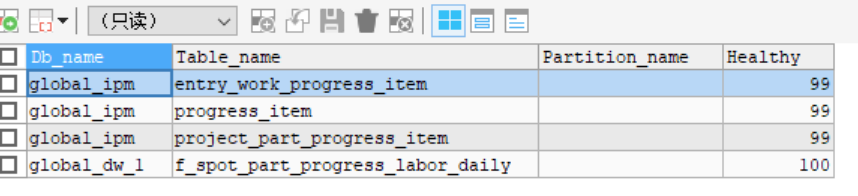
用是这么用,可能有些条件下会导致hint也不起作用,建议你还是先收集下统计信息看,健康度高不代表统计信息没问题,健康度只能准确代表数据变化的量
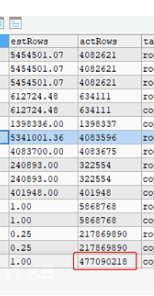
我确认所有涉及到的表都是很健康的,因为我这是一个测试库,没负载,刚刚analyze过:
h5n1
(H5n1)
16
健康度不代表统计信息的准确性,只是说明这个表里从上次收集统计信息有多少行变更了
是用analyze table xxx 吗?有没有其他要注意的?