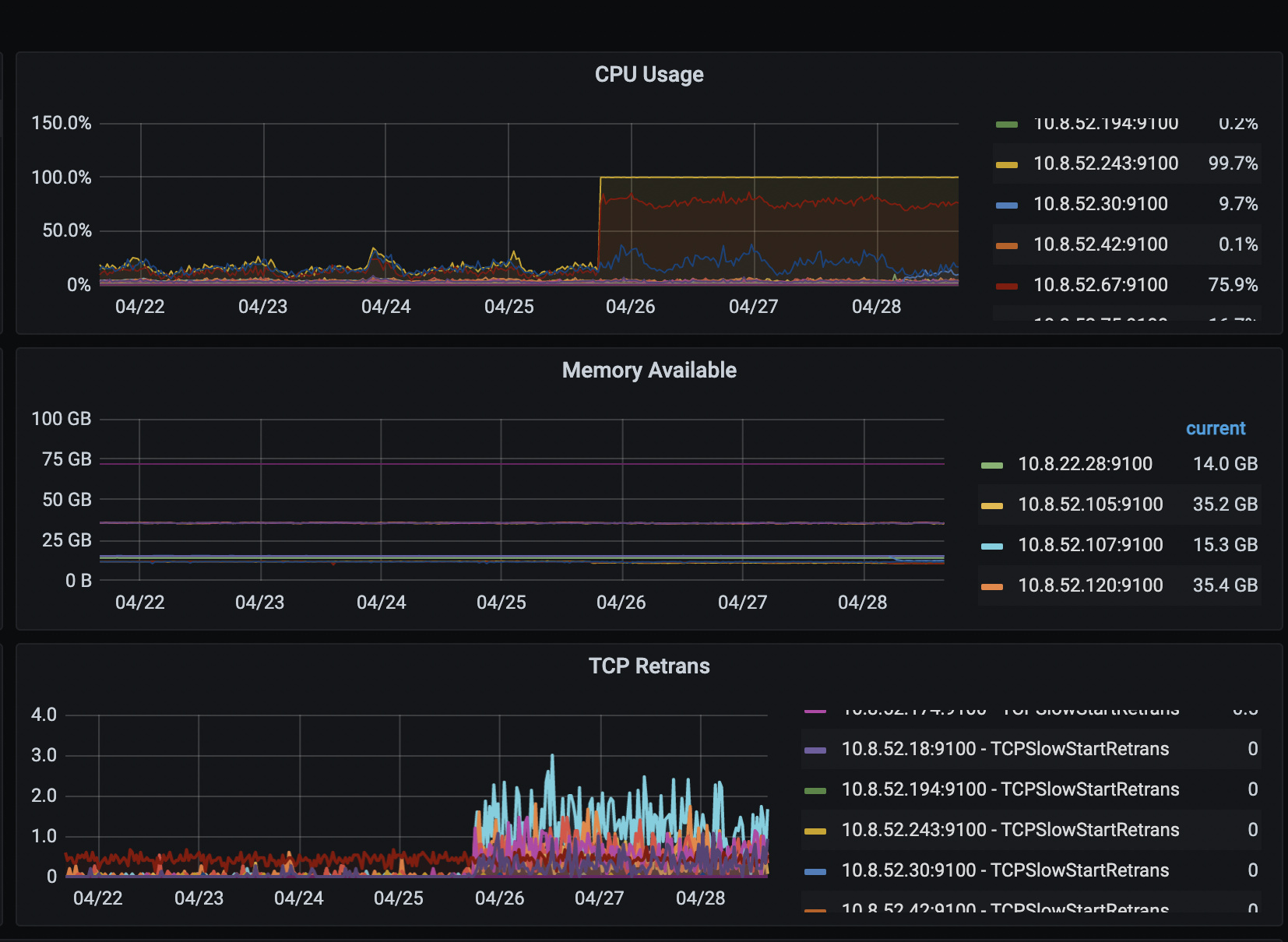
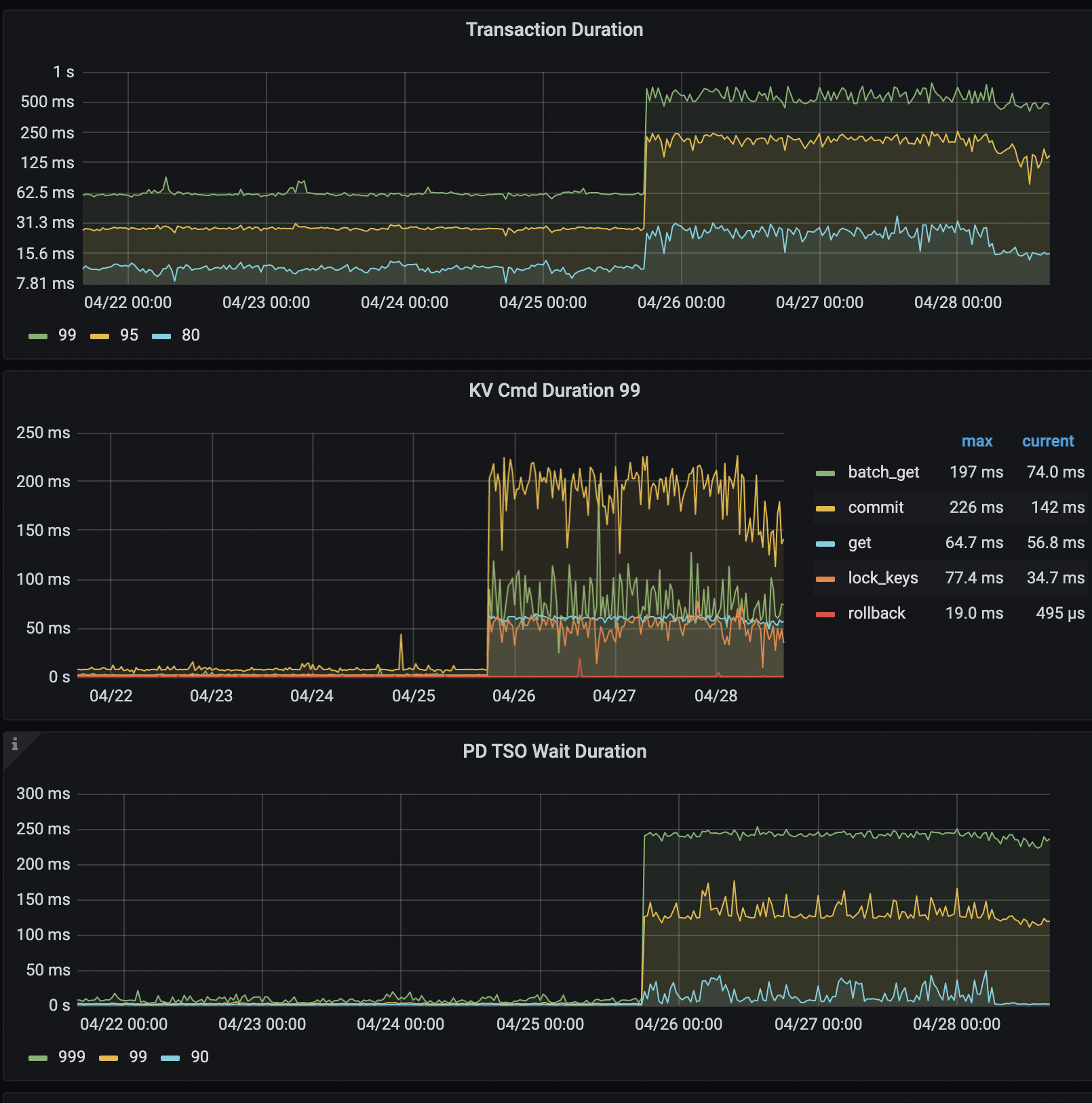
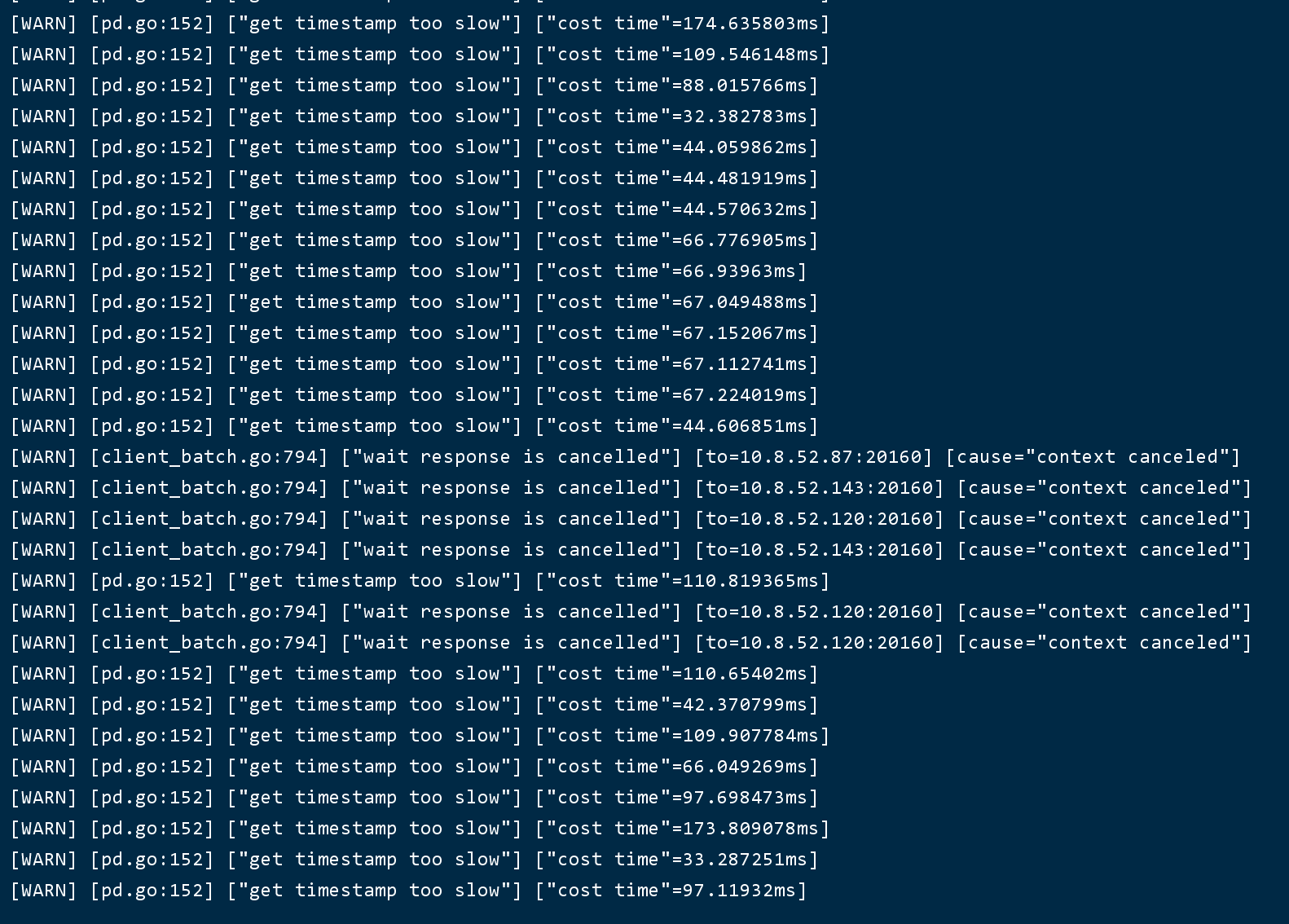
集群(版本5.4)有三台tidb-server,其中有一台cpu长期保持在100左右,还有一台75左右,最后一台只有十几的占用率。占用最高的那台db日志中有大量的get timestamp too slow,麻烦协助排查下问题。
检查过那个时间段的慢SQL吗(dashboard、slow log、tidb.log中的expensive SQL)? show processlist看看100%的在执行什么? show analyze status 看看是否有表分析任务在跑? get timestamp too slow 可能是由于db server CPU利用率高导致
满查询没有很多,并且cpu占用一直没有下来,从25号开始,而且只有db的cpu飙高,kv和pd 的cpu占用一直很低,应该不是慢查询的问题
show processlist 显示都是autocommit
1、看看突增那时间段的tidb.log里 的信息,
2、可使用如下方式获取哪些消耗CPU高。
curl -G http://{TIDB_IP}:10080/debug/pprof/profile > cpu.profile
然后使用go tool pprof cpu.prof --> top命令查看
这种应该是有啥计算量高的SQL,或者定时任务发起,在监控和日志中看看
为什么有的db高有的低呢
大佬这个go tool在哪里,具体使用有文档吗
需要 安装 go
按此导出下这几个快照,还tidb的log
导出监控步骤:
打开监控面板,选择监控时间,一定要展开所有面板,等数据加载完
打开 Grafana 监控面板(先按 d 再按 E 可将所有 Rows 的 Panels 打开,需等待一段时间待页面加载完成)
https://metricstool.pingcap.com/ 1 使用工具导出 Grafana 数据为快照
tidb-cluster-Overview_2022-04-28T09_40_37.518Z.json (4.0 MB)
这样吗,大佬
pd/tidb/tikv detail/ black expoter也这样导出下
tidb-cluster-PD_2022-04-28T10_35_35.130Z.json (243.9 KB) tidb-cluster-TiDB_2022-04-28T10_37_20.592Z.json (6.9 MB)
大佬这样可以吗
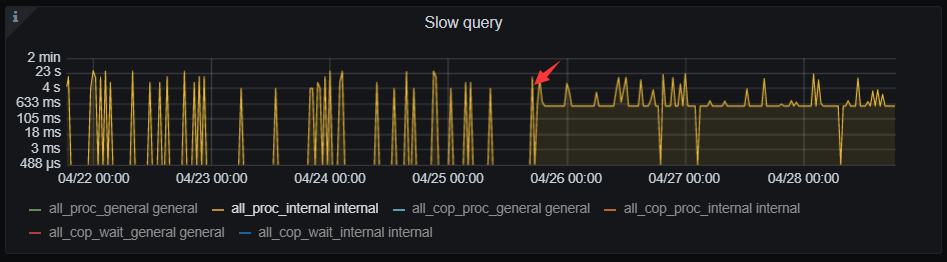
好的 先优化掉慢查询 再看有没有降下来吗
我看了慢查询最慢是analyze table,我如何取消自动analyze,后面自己手动执行analyze
analyze执行多久了,目前版本还不支持手动取消自动analyze table任务。
我看的是已经执行完的,大概一分钟左右执行完成
高版本支持取消吗