【 TiDB 使用环境】
【概述】 场景 + 问题概述
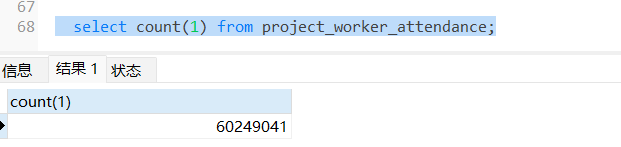
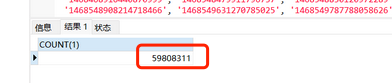
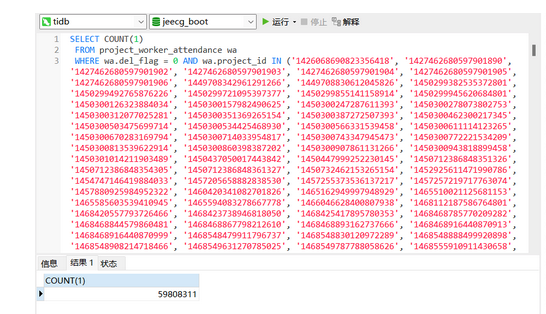
查看索引,使用全表扫描
【问题】 当前遇到的问题
【业务影响】
【TiDB 版本】
【附件】 相关日志及配置信息
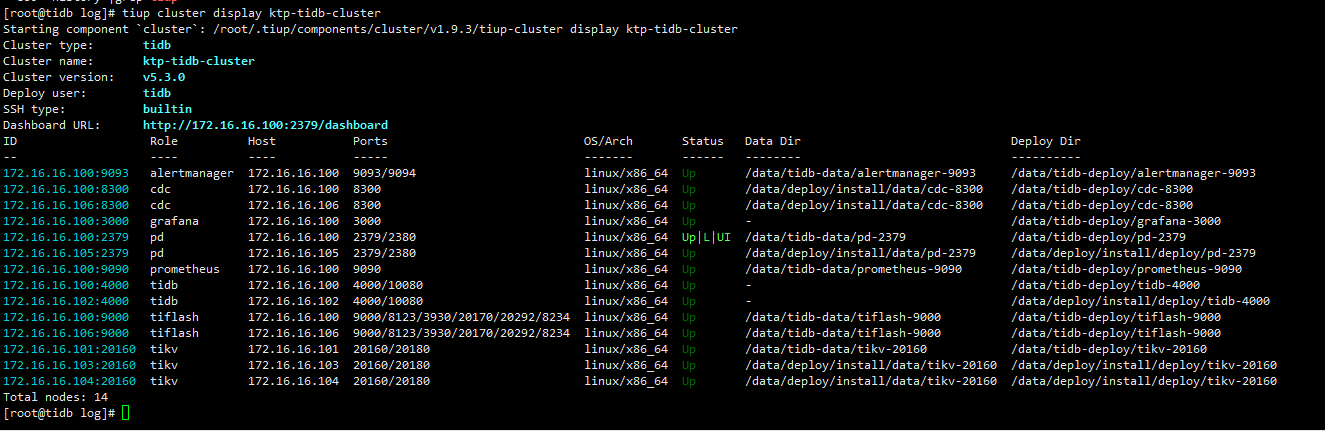
TiUP Cluster Display 信息
TiUP CLuster Edit config 信息
监控(https://metricstool.pingcap.com/ )
TiDB-Overview Grafana监控
TiDB Grafana 监控
TiKV Grafana 监控
PD Grafana 监控
对应模块日志(包含问题前后 1 小时日志)
若提问为性能优化、故障排查 类问题,请下载脚本 运行。终端输出的打印结果,请务必全选 并复制粘贴上传。
2 个赞
MyronWang
2022 年4 月 28 日 02:08
2
你好。请提供下:
表结构;
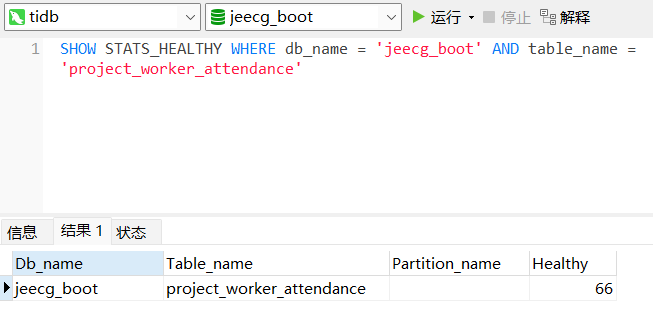
表健康度;(SHOW STATS_HEALTHY WHERE db_name = ? AND table_name = ? )
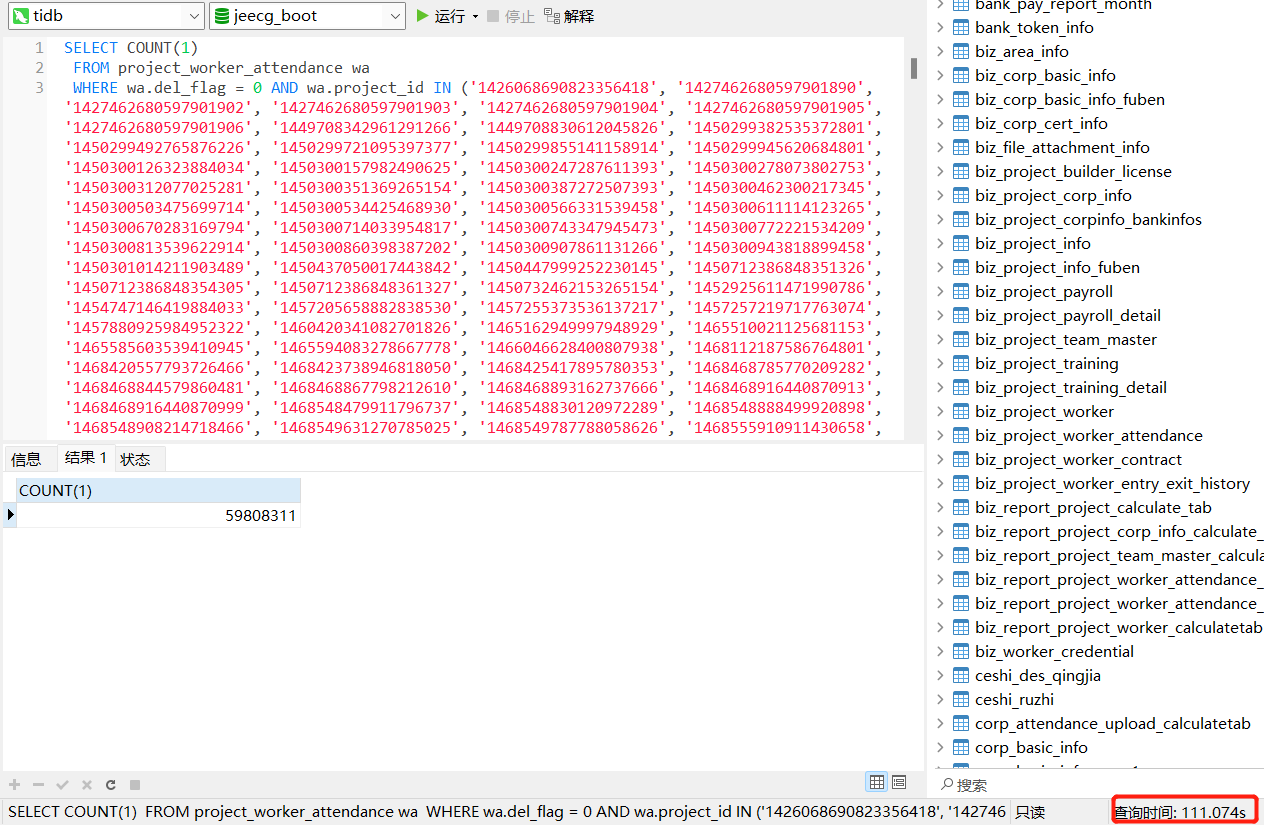
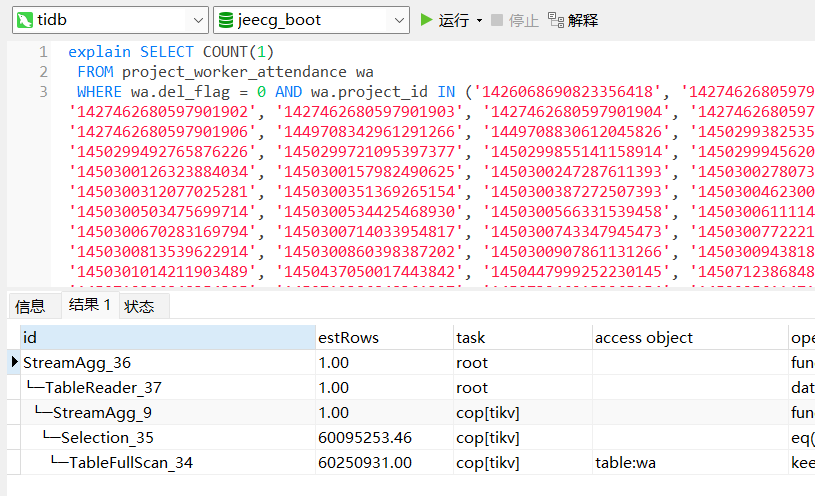
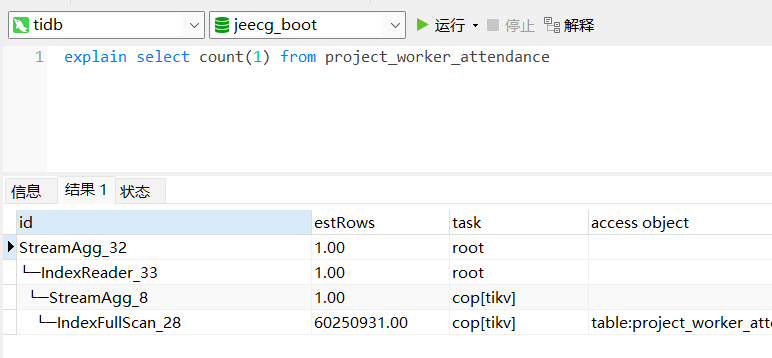
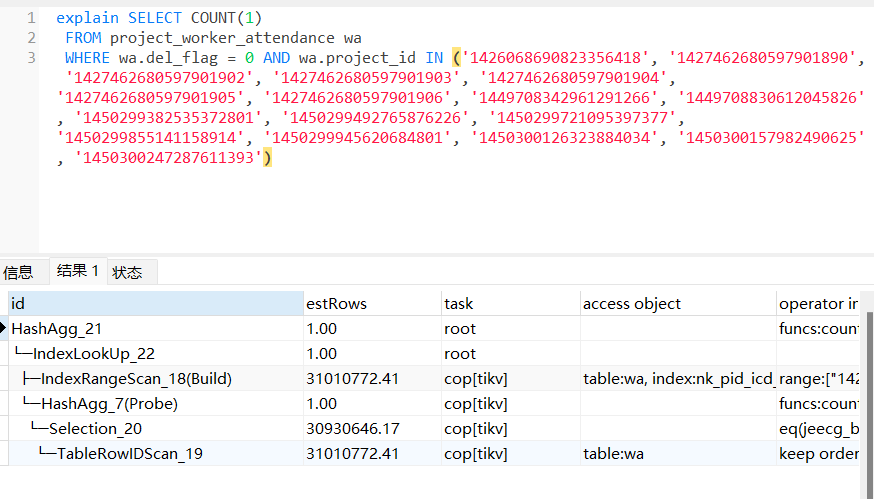
select count(1) from xx 与 select count(1) from xx where xx in () 的执行计划。(你只给出了一个执行计划)
通过分析你的问题描述,我感觉是优化器觉得全表扫和走索引(如果有有效索引)代价基本相差不大,所以直接走全表扫了。
加不加 where 条件,结果差距很小。你可以尝试 where in 放两个值试试,对比下效果。
2 个赞
h5n1
2022 年4 月 28 日 02:34
7
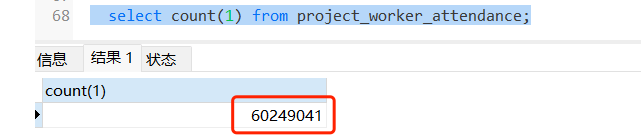
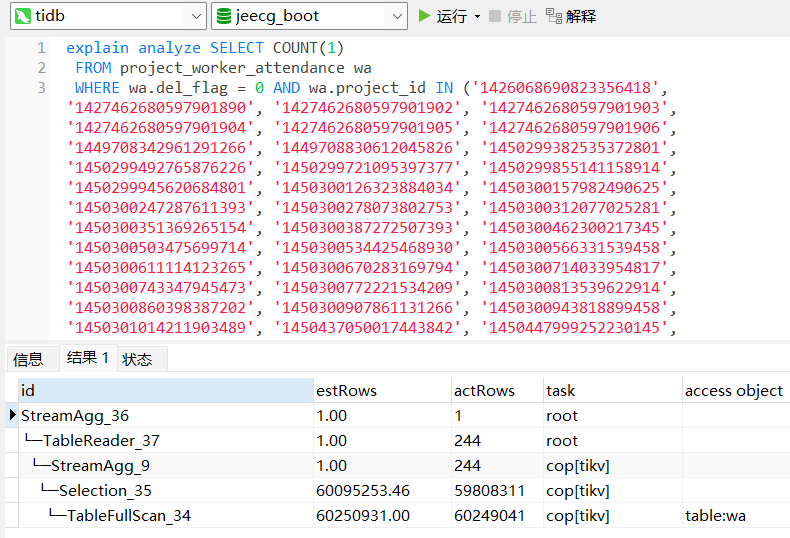
加in的过滤条件59808311/60249041=0.9927, 任何一个正常工作的数据库都会选择全表扫描,贴下explain analyze的执行结果
2 个赞
MyronWang
2022 年4 月 28 日 02:43
9
从目前提供的信息看,这个结果是预期的。count 的结果走索引跟全表扫基本没区别,而且 del_flag 还没有索引可以走。
3 个赞
是有条件关联查询的情况,为了避免使用join关联,就采用了先查第一张表,再在这种表种使用in,至少是单表查询,如果是关联就更慢
1 个赞
h5n1
2022 年4 月 28 日 02:46
11
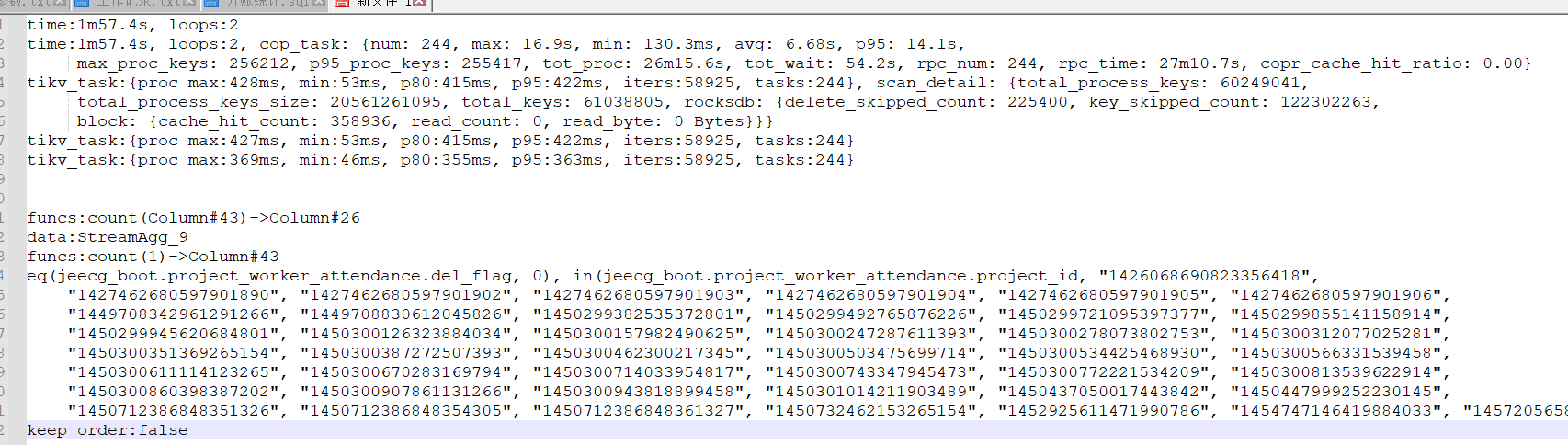
explain analyze看下后部分execution info。 加了in过滤条件99%的数据量返回和全表扫没太大区别,走个索引在回表查询更慢
2 个赞
del_flag是删除标志,只有0和1两个值,有没有索引影响应该不大
1 个赞
MyronWang
2022 年4 月 28 日 02:50
13
但是因为这个,导致了回表操作。
主要还是你 where in 的过滤效果太低了(5900W 那个例子),近似没有 where 条件。
1 个赞
是有条件关联查询的情况,为了避免使用join关联,就采用了先查第一张表,再在这种表种使用in,至少是单表查询,如果使用join,一张60万左右表和一张6千万表进行关联,那没法查
1 个赞
MyronWang
2022 年4 月 28 日 03:04
16
我明白你的真实场景,应该是 select count(1) from a where xxx and xxx in (select subquery) 这种吧。
1 个赞
h5n1
2022 年4 月 28 日 03:23
20
tidb cpu (tidb监控),tidb和tikv的网络延迟(blackexporter监控)看下
wisdom
2022 年4 月 29 日 12:44
21
手动更新统计信息收集,查看执行计划 ,优化一下sql语句 分析一下 看看能不能走索引 尝试一下
1 个赞