- 下发了 15 个并发 cop task ,在 tikv 执行数据扫描时是并行的,那么返回数据给 tidb 是并行还是按某种顺序串行的?
-
返回给 tidb 的数据是并行的,如果结果集无序,则所有并发的 request 结果会返回给一个全局 response channel。如果结果集有序,则所有并发的 request 结果返回到各 worker 各自 channel,随后处理保证结果有序性。当前
select * from XXX limit 1无序结果结合为例,则全局 channel 并行接收 tikv 并发返回的结果到一个 response channel。 - 参考描述 “在 copIterator 创建的时候,我们启动一个后台 worker goroutine 来依次执行所有的 coprocessor task,并把执行结果发送到一个 response channel,这样前台 Next 方法只需要从这个 channel 里 receive 一个 coprocessor response 就可以了。如果这个 task 已经执行完成,Next 方法可以直接获取到结果,立即返回。” - - from - → TiDB 源码阅读系列文章(十九)tikv-client(下)。
- 就返回数据而言,从 tidb 看各 tikv 而言是并行的,因为一旦 worker 构造完成就会启动 handleTask ,将获取的对应 task 的结果推到 response channel 中。因为 worker 基于 tidb_dist_scan_concurrency 并行,所以 worker 推结果集到 response channel 也是并行。至于 response channel 中的数据则由 Next() 函数消费,具体如何消费取决于算子对 chunk(返回结果) 中数据量的需求。
-
是否是某个 region 内数据全部扫描完成才返回还是说按照某种大小的批次返回?
这取决于该请求是使用 Grpc 的 unary、server stream 还是 bidirectional stream。在 tidb 代码逻辑中,上述模式基本都有涉及。假设 走了 batch get 的大部分都会用 bidirectional stream。也就是说分批返回,单纯扫 region 而言不用 1 个 region 全扫完再返回结果集合。但这块没有深追具体代码位置 -
tidb 是如何保障获取 1 个 region 就能满足所需数据的条件下及时关闭其他 region 的数据返回保证没有多余数据返回?
上文之所以说:“在 TiDB 测看来,组件 tidb 接收一个 Region 的结果集就可以完成上层处理。” 是从 cop task 与 region 的对应关系方面做的阐述。更准确的描述应是,涉及第一个 Regioin 的第一次返回的结果集。 因为单纯扫表而言,如果走了 grpc 的 bidirectional stream,那么 tikv 会边扫边返回结果集,而 tidb 侧一旦观察到 response channel 中有 Region 返回的数据便用 chunk 从 response channel 中接数处理。 我理解这块应该没有机制保证没有多余数据返回,只要 tidb 侧够满足调用,及时 cancel 掉请求就可以了,即使在 cancel 之前多返回了数据直接废弃就好了。 -
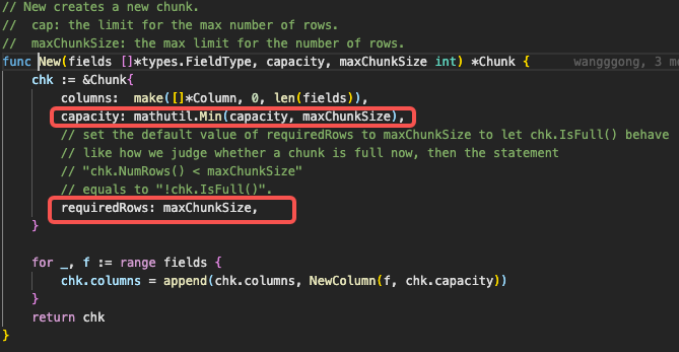
tidb_max_chunk_size 这参数值默认是 1024 那这个算子不应该是 1024 行吗?毕竟 tikv 侧返回了 41 万行数据。32 应该是一次 next 处理的 batch 大小吧
tidb_max_chunk_size 代表该 chunk 满了的大小,可以理解为 32 是一次 next 处理的 batch 大小。 chunk 在初始化时, capacity 属性会被置为 32,也就造成了 1 个 chunk 接收 32 行数据。