version: tidb 5.3.1
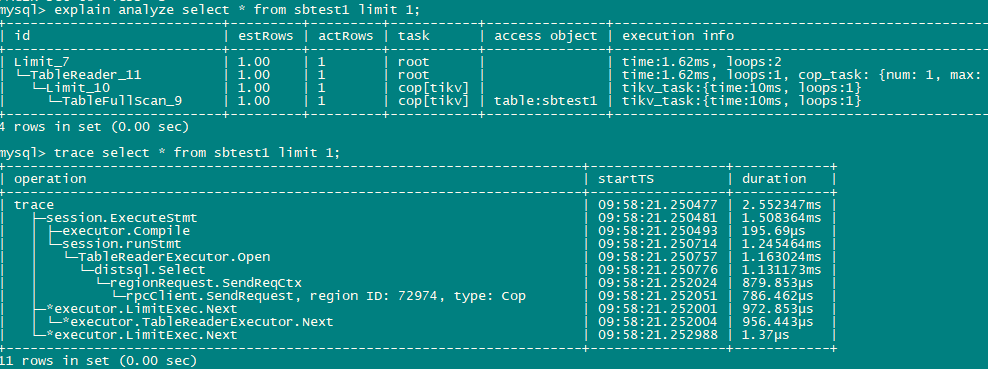
表sbtest7有2亿条记录,480+ region, 通过mysql.opt_rule_blacklist 禁用了topn_push_down之后Limit未下推到tikv
未禁用topn_push_down的执行计划和trace:
禁用后执行计划:

问题:
1、 禁用top下推后,Table_Reader显示actRows=32,这里tablereader 算子返回32行是依据什么算来的?
2、禁用topn下推后执行计划显示cop_task为1,而实际trace为15个,通过调整tidb_distsql_scan_concurrency=1 ,执行计划中实际的actRows与tidb_distsql_scan_concurrency默认值15时相同,也就是说禁用下topn 下推后 ,SQL执行仅扫描了一个region的所有数据就足够了,为什么执行计划显示1个cop task而trace里却有15个?另外是14个cop task是否真正的执行了?

这个我也不清楚,等我确认一下,再反馈给你吧
因为你是使用explain analyze,所以actRows显示的实际读的行数,我猜这是读到第一个block,里面的32行,当然这是TiDB Server层面才是32行,而TiKV层面是读了41万行的。
2 个赞
个人拆分上述为 4 个问题:
1.在禁用 topn_push_down 后, 为什么执行计划显示 1 个 cop task 而 trace 里却有15个?
2.在禁用 topn_push_down 后, 其余 14 个 cop task 是否真正的执行了?
3. tablereader 算子返回 32 行是依据什么算来的?
4. 在禁用 topn_push_down 后,调整 tidb_distsql_scan_concurrency=1, trace 等同于 1 的原因?
-
First ASK: 为什么执行计划显示 1 个 cop task 而 trace 里却有15个?
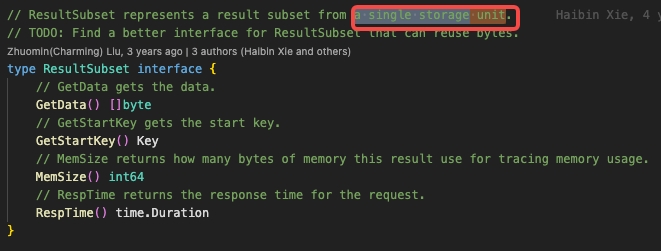
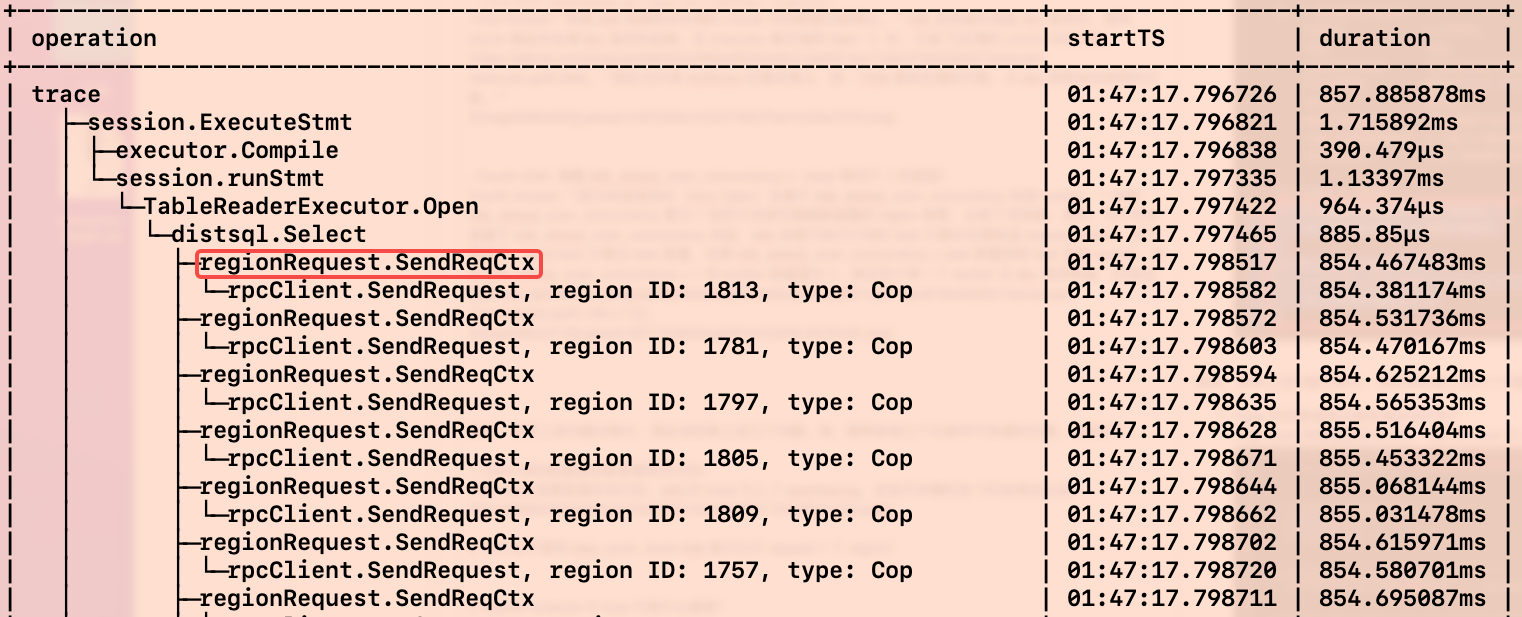
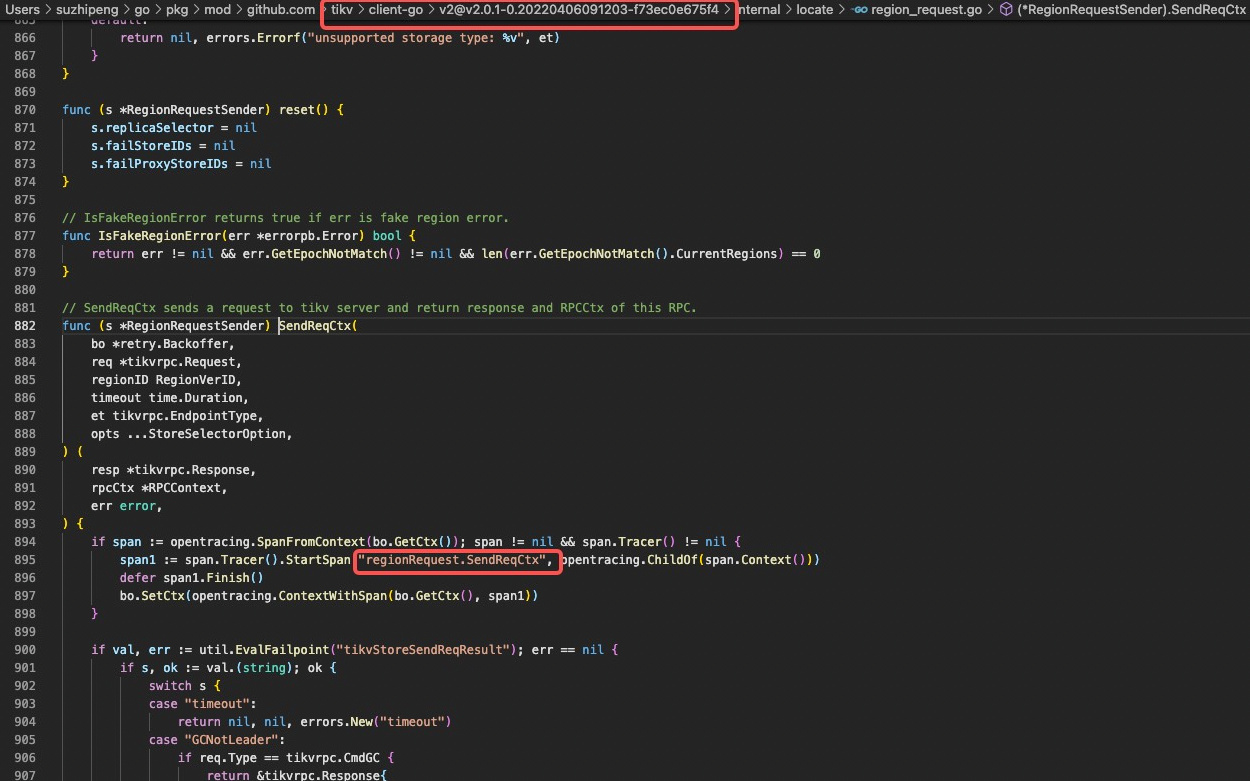
First Answer: 因为真的构造了 15 个发向 tikv 的请求。 cop task 的数量的计算的是 ResultSubset 的数量,在代码中 ResultSubset 注释为 一个存储单元的结果集,也就是说 cop task 与 Region 一一对应。在 TiDB 测看来,组件 tidb 接收一个 Region 的结果集就可以完成上层处理。因此,cop task num 是 1。至于 trace 到 15 个 Region Request,是因为在构造请求阶段会开启 tidb_dist_scan_concurrency 数量的协程向 tikv 并发发起处理请求,concurrency 代码位置。
-
Second ASK: 14 个 cop task 是否真正的执行了?
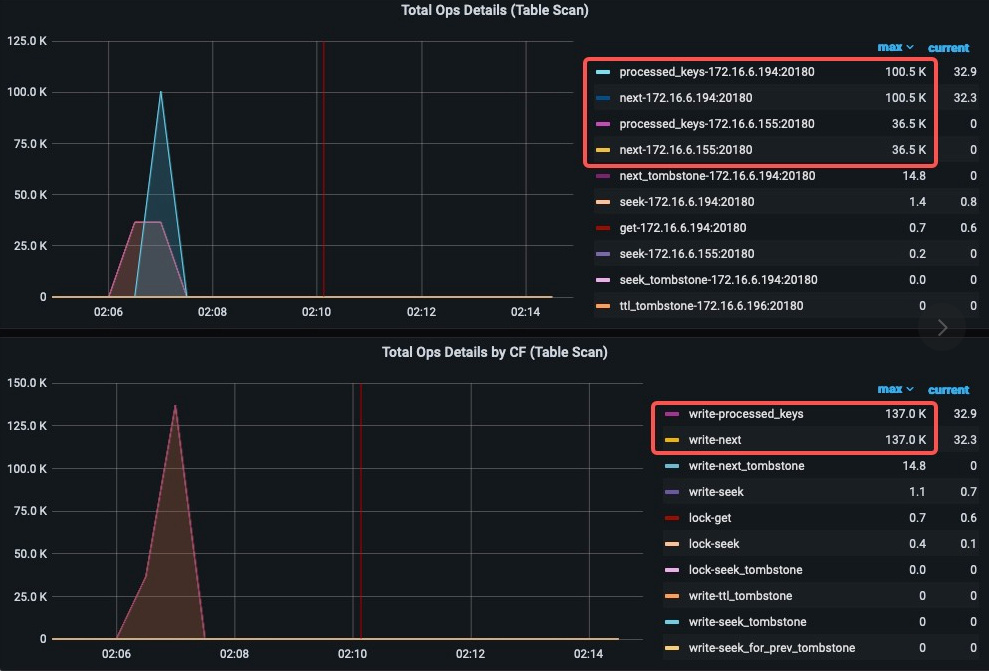
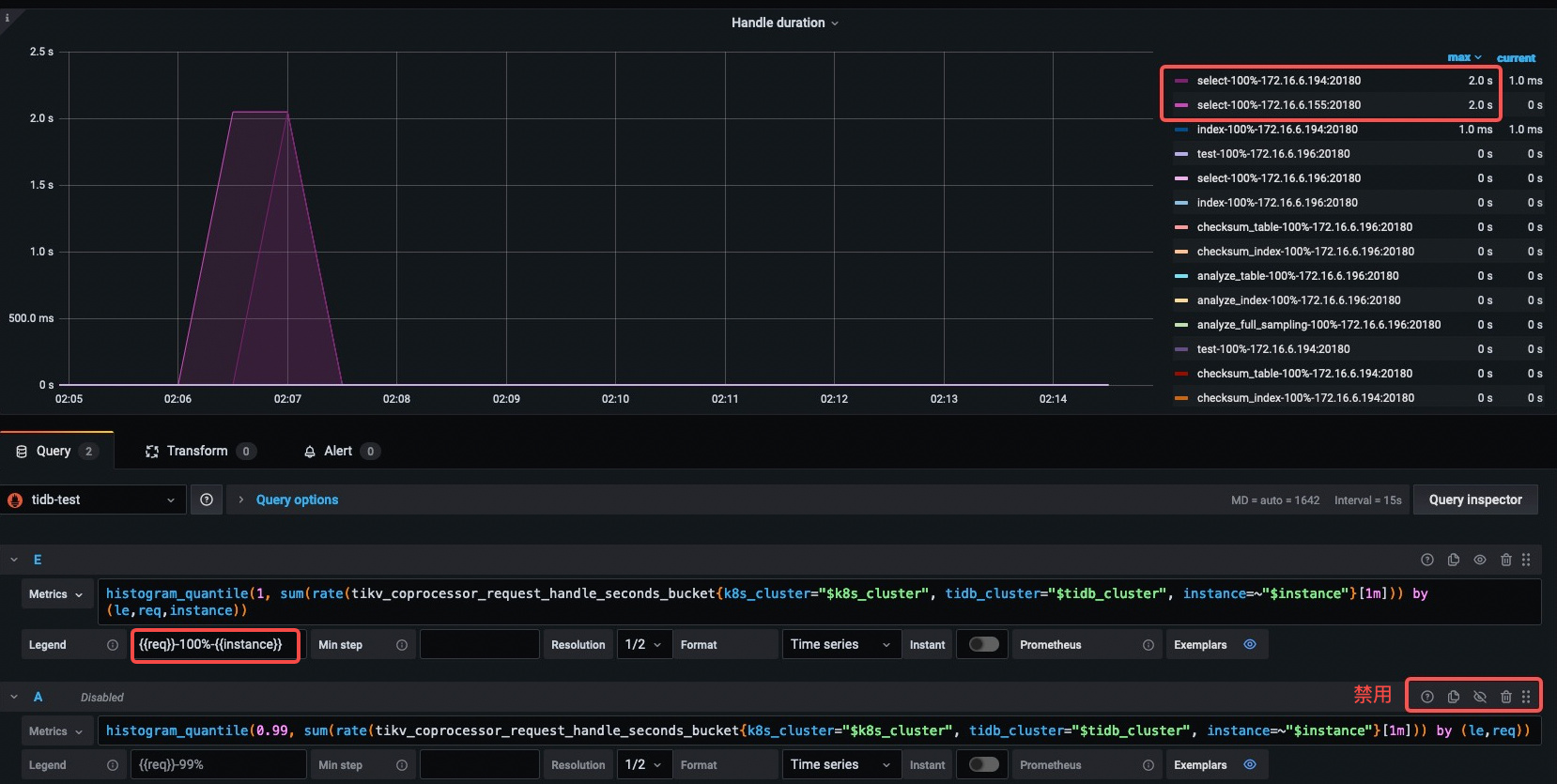
Second Answer: 真的执行了。 从如下 2 张 TiKV Ops Details 手动加了基于 {{instance}} 区分的图像可以看出,IP194 和 IP155 分别扫了 RocksDB write 列簇 100.5K 和 36.5K 个 key。也就是说这些请求,真实的发送到了 TiKV 处理,而且从 Handle Duration 100% 看,运行了相同的时间。随后被 cancel 掉,至于为什么被 cancel,后文解释。
-
Third ASK: tablereader 算子返回 32 行是依据什么算来的?
Third Answer:依据 tidb 侧接收并处理的, chunk 中的数据行数总和计算得出。 tidb 在构造并发起 tikv 请求后,使用 chunk(一块内存空间) 接收并处理 tikv 返回的结果。在 Executor 每次调用 Next()时,记录下处理的 chunk 中的行数。因此也代表 ActRows 的真实意义,即:TiDB 真实处理的行数,从 tikv 获取返回结果的行数。
-
Fourth ASK: 调整 tidb_distsql_scan_concurrency=1, trace 等同于 1 的原因?
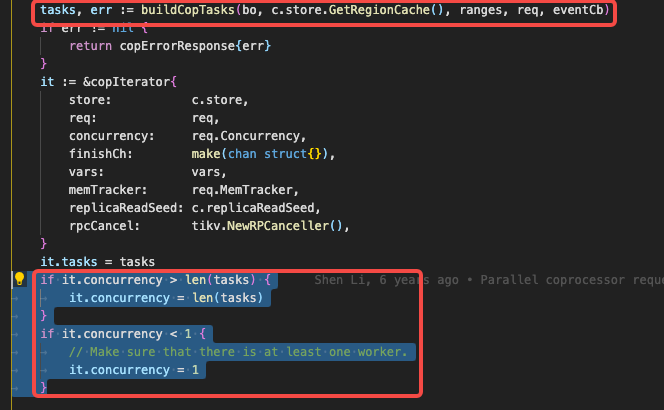
Fourth Answer: 因为构造请求时(func Open)会基于 tidb_distsql_scan_concurrency 构造 worker。如果 tidb_distsql_scan_concurrency 置为 1 恰好与该语句需要数据量的 region 相等,出现了该现象。 其实,也不完全是基于 tidb_distsql_scan_concurrency 构造,tidb 会基于执行计划的 task 计算并合理构造 request worker。如下图所示,build task 计算出 task 数量,如果 tidb_distsql_scan_concurrency > task 数量则取 task 数量 worker。如果 tidb_distsql_scan_concurrency < 1 则 worker 数量置为 1,保证至少有一个 worker 去 tikv 请求数据,代码位置。

其实,思考上述问题过程中,我必须回答下述几个问题。或,顺带发现几个以前所不知道的问题,总结如下。
-
trace 到的数据是否都是真实执行的?
只要 trace 到便是真实执行的,tidb 的 trace 引入了 opentracing,在执行步骤的各个阶段埋点记录。即只要 trace 到,那么一定执行了该代码模块,包含 “执行失败” 或 “手动取消”。
-
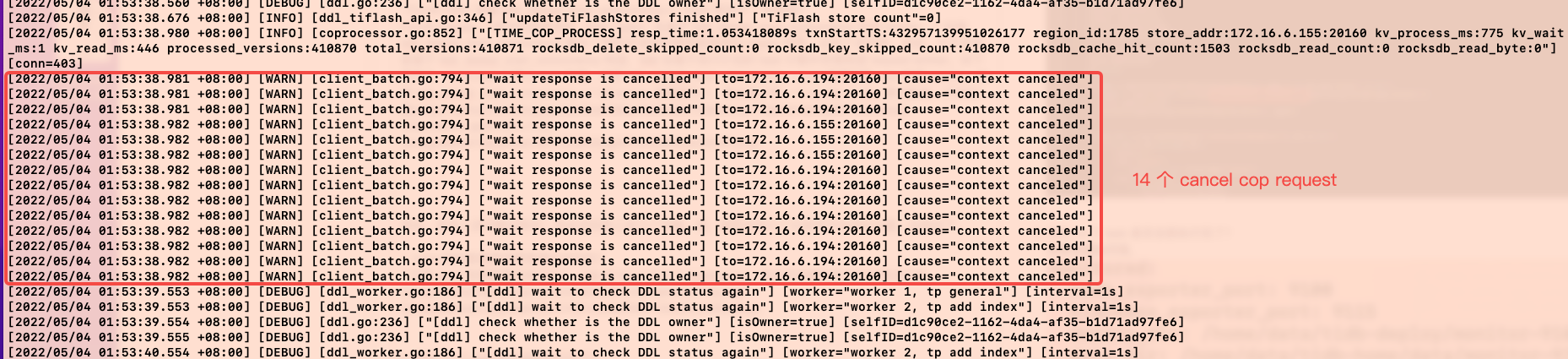
其余 14 个 task 是否全部执行完了?
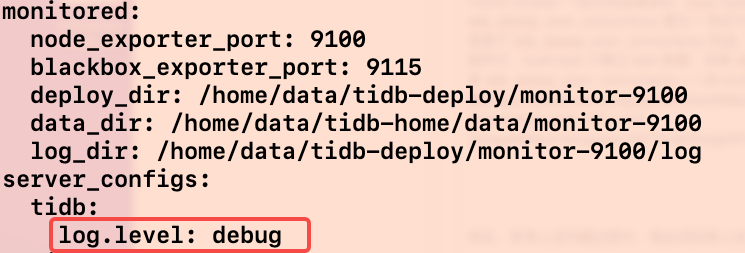
没有全部执行完,禁用 topn_push_down 后,将 tidb 的日志级别改为 DEBUG 后,执行trace select * from sbtest1 limit 1;会发现有 14 条 cancel cop request 日志打出。也就说明,tidb 取消了其余 14 个 Region 的处理请求。
-
explain analyze 中 loop 代表什么意思?
正如代码注释的那样,TiDB 计算框架采用向量模型(变异的火山模型),也就是说 loop 代表 “向量模型中执行器的 Next 方法的调用次数”,代码位置。
-
为什么不禁用 topn_push_down tidb 就可以只 request 1 个 region?
如问题 4 中最后阐述部分,request worker 除参考 tidb_distsql_scan_concurrency 外,还要参考优化器评估的 cop task 的数量。也就是说,在 topn_push_down 非禁用状态下,优化器可以直接评估出 cop task 数量为 1 即可,也就是 region 为 1 即可。至于优化器优化细节,需要大量前置知识,不再继续深追研究🧐!!

3 个赞
大佬写的真详细,开启topn下推后full scan+limit 1只下发一个cop task看描述应该是这个优化:https://github.com/pingcap/tidb/issues/18791
另外再请教下
1、 下发了15个并发cop task ,在tikv执行数据扫描时是并行的,那么返回数据给tidb是是并行还是按某种顺序串行的?是否是某个region内数据全部扫描完成才返回还是说按照某种大小的批次返回? tidb是如何保障获取1个region就能满足所需数据的条件下及时关闭其他region的数据返回保证没有多余数据返回?
2、 tidb_max_chunk_size 这参数值默认是1024那这个算子不应该是1024行吗?毕竟tikv侧返回了41万行数据。32应该是一次next处理的batch大小吧
1 个赞
- 下发了 15 个并发 cop task ,在 tikv 执行数据扫描时是并行的,那么返回数据给 tidb 是并行还是按某种顺序串行的?
-
返回给 tidb 的数据是并行的,如果结果集无序,则所有并发的 request 结果会返回给一个全局 response channel。如果结果集有序,则所有并发的 request 结果返回到各 worker 各自 channel,随后处理保证结果有序性。当前
select * from XXX limit 1无序结果结合为例,则全局 channel 并行接收 tikv 并发返回的结果到一个 response channel。 - 参考描述 “在 copIterator 创建的时候,我们启动一个后台 worker goroutine 来依次执行所有的 coprocessor task,并把执行结果发送到一个 response channel,这样前台 Next 方法只需要从这个 channel 里 receive 一个 coprocessor response 就可以了。如果这个 task 已经执行完成,Next 方法可以直接获取到结果,立即返回。” - - from - → TiDB 源码阅读系列文章(十九)tikv-client(下)。
- 就返回数据而言,从 tidb 看各 tikv 而言是并行的,因为一旦 worker 构造完成就会启动 handleTask ,将获取的对应 task 的结果推到 response channel 中。因为 worker 基于 tidb_dist_scan_concurrency 并行,所以 worker 推结果集到 response channel 也是并行。至于 response channel 中的数据则由 Next() 函数消费,具体如何消费取决于算子对 chunk(返回结果) 中数据量的需求。
-
是否是某个 region 内数据全部扫描完成才返回还是说按照某种大小的批次返回?
这取决于该请求是使用 Grpc 的 unary、server stream 还是 bidirectional stream。在 tidb 代码逻辑中,上述模式基本都有涉及。假设 走了 batch get 的大部分都会用 bidirectional stream。也就是说分批返回,单纯扫 region 而言不用 1 个 region 全扫完再返回结果集合。但这块没有深追具体代码位置 -
tidb 是如何保障获取 1 个 region 就能满足所需数据的条件下及时关闭其他 region 的数据返回保证没有多余数据返回?
上文之所以说:“在 TiDB 测看来,组件 tidb 接收一个 Region 的结果集就可以完成上层处理。” 是从 cop task 与 region 的对应关系方面做的阐述。更准确的描述应是,涉及第一个 Regioin 的第一次返回的结果集。 因为单纯扫表而言,如果走了 grpc 的 bidirectional stream,那么 tikv 会边扫边返回结果集,而 tidb 侧一旦观察到 response channel 中有 Region 返回的数据便用 chunk 从 response channel 中接数处理。 我理解这块应该没有机制保证没有多余数据返回,只要 tidb 侧够满足调用,及时 cancel 掉请求就可以了,即使在 cancel 之前多返回了数据直接废弃就好了。 -
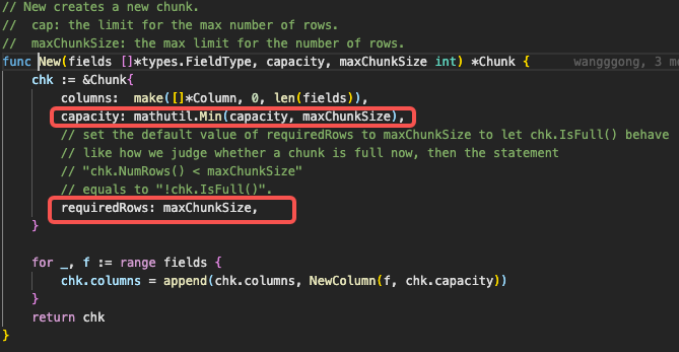
tidb_max_chunk_size 这参数值默认是 1024 那这个算子不应该是 1024 行吗?毕竟 tikv 侧返回了 41 万行数据。32 应该是一次 next 处理的 batch 大小吧
tidb_max_chunk_size 代表该 chunk 满了的大小,可以理解为 32 是一次 next 处理的 batch 大小。 chunk 在初始化时, capacity 属性会被置为 32,也就造成了 1 个 chunk 接收 32 行数据。
2 个赞
![]() 大佬牛逼,这些回复够写2篇文章的了。
大佬牛逼,这些回复够写2篇文章的了。
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。