tidb版本:5.0.3
环境: 生产
这个表前两天有大量的delete 数据,表的健康度只剩下4,ANALYZE后恢复到100,
今天发现查询一张大表,超过20分钟都没查询出来,请问该怎么排查这个问题,
查询语句如下:
select * from sharpengine_bi.dws_if_date_shence_promotion_data_hive limit 1
kv有错误日志:
[raft_client.rs:404] [“connection aborted”] [addr=XXXXX:20160] [receiver_err=“Some(RpcFailure(RpcStatus { status: 14-UNAVAILABLE, details: Some(“Socket closed”) }))”] [sink_error=“Some(RpcFinished(Some(RpcStatus { status: 14-UNAVAILABLE, details: Some(“Socket closed”) })))”] [store_id=5297317]
4 个赞
张雨齐0720
(Zhangjig)
3
最好看看执行计划,然后Dashboard看看执行的慢SQL记录,有没有记录,具体的执行情况
5 个赞
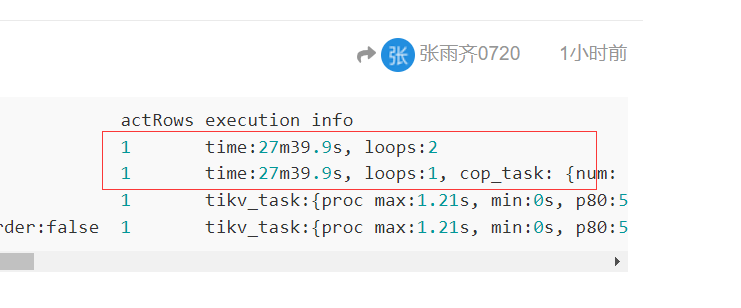
id task estRows operator info actRows execution info memory disk
Limit_7 root 1 offset:0, count:1 1 time:27m39.9s, loops:2 N/A N/A
└─TableReader_12 root 1 data:Limit_11 1 time:27m39.9s, loops:1, cop_task: {num: 3116, max: 8.43s, min: 754.1µs, avg: 514.6ms, p95: 761.6ms, max_proc_keys: 1, p95_proc_keys: 0, tot_proc: 24m49.2s, tot_wait: 23.5s, rpc_num: 3116, rpc_time: 26m43.4s, copr_cache_hit_ratio: 0.00}, backoff{regionMiss: 3.87s} 612 Bytes N/A
└─Limit_11 cop[tikv] 1 offset:0, count:1 1 tikv_task:{proc max:1.21s, min:0s, p80:572ms, p95:697ms, iters:3116, tasks:3116}, scan_detail: {total_process_keys: 1, total_keys: 2914758876, rocksdb: {delete_skipped_count: 13850655, key_skipped_count: 2933666734, block: {cache_hit_count: 42311, read_count: 4558525, read_byte: 22.8 GB}}} N/A N/A
└─TableFullScan_10 cop[tikv] 1 table:dws_if_date_shence_promotion_data_hive, keep order:false 1 tikv_task:{proc max:1.21s, min:0s, p80:572ms, p95:697ms, iters:3116, tasks:3116}, scan_detail: {total_process_keys: 0, total_keys: 0, rocksdb: {delete_skipped_count: 0, key_skipped_count: 0, block: {cache_hit_count: 0, read_count: 0, read_byte: 0 Bytes}}} N/A N/A
看了下,这里没有全表啊
4 个赞
张雨齐0720
(Zhangjig)
5
5 个赞
请教下,我的理解是limit 1 是查询到1条立即返回, 如果是全表扫,就是把表数据都查出来 再取第一条,是这样吗?
5 个赞
这个表是不是没主键,这种语句一般是扫主键,然后输出一条信息,而不是直接全表扫
5 个赞
是的 这表是没主键, 如果我加 where 有索引的列, 就没这问题
4 个赞
h5n1
(H5n1)
10
貌似有问题,时间消耗在tidb侧,tikv返回了1条数据,居然执行了27分钟
看下这SQL执行时相应的tidb server 内存有增长吗
4 个赞
caiyfc
11
加索引条件,就是直接扫索引了,所以肯定更快的。全表扫是最慢的。
3 个赞
h5n1
(H5n1)
12
Limit_11 已经下推到tikv了,就算是全表扫描 也不应该全表都执行一遍, 3116 个cop task,按理不应该每个task都读取所有数据
6.3亿的 0.21秒完成
3 个赞
caiyfc
16
嗯,现在就是没有只读取一条数据的问题,而且根据执行计划,rpc time耗时很久,是不是回表的数据太大,就导致整个sql耗时过长。
3 个赞
雪落香杉树
18
麻烦看下这个参数
show config where type = 'tikv' and name like '%enable-compaction-filter%';
3 个赞
雪落香杉树
19
再看下gc的
select * from mysql.tidb where variable_name like "tikv_gc_%";
3 个赞
h5n1
(H5n1)
20
select /*+ LIMIT_TO_COP() */ 全表扫描的SQL加这个hint跑一遍试试
3 个赞
id task estRows operator info actRows execution info memory disk
Limit_7 root 1 offset:0, count:1 1 time:22m22.3s, loops:2 N/A N/A
└─TableReader_11 root 1 data:Limit_10 1 time:22m22.3s, loops:1, cop_task: {num: 3122, max: 4.31s, min: 577µs, avg: 429.7ms, p95: 677.7ms, max_proc_keys: 1, p95_proc_keys: 0, tot_proc: 20m37.8s, tot_wait: 4.18s, rpc_num: 3122, rpc_time: 22m21.6s, copr_cache_hit_ratio: 0.12} 609 Bytes N/A
└─Limit_10 cop[tikv] 1 offset:0, count:1 1 tikv_task:{proc max:1.05s, min:0s, p80:543ms, p95:617ms, iters:3122, tasks:3122}, scan_detail: {total_process_keys: 1, total_keys: 2562906823, rocksdb: {delete_skipped_count: 10718623, key_skipped_count: 2577837683, block: {cache_hit_count: 35660, read_count: 3994627, read_byte: 19.9 GB}}} N/A N/A
└─TableFullScan_9 cop[tikv] 1 table:dws_if_date_shence_promotion_data_hive, keep order:false 1 tikv_task:{proc max:1.05s, min:0s, p80:543ms, p95:617ms, iters:3122, tasks:3122}, scan_detail: {total_process_keys: 0, total_keys: 0, rocksdb: {delete_skipped_count: 0, key_skipped_count: 0, block: {cache_hit_count: 0, read_count: 0, read_byte: 0 Bytes}}} N/A N/A
select /*+ LIMIT_TO_COP() */ * from sharpengine_bi.dws_if_date_shence_promotion_data_hive limit 1
效果一样,
论坛里面有这个帖子
我的使用场景和他差不多,只是这个语句我没法像他一样增加where调整,
3 个赞