明白了

11点15 有一台tikv的CPU高
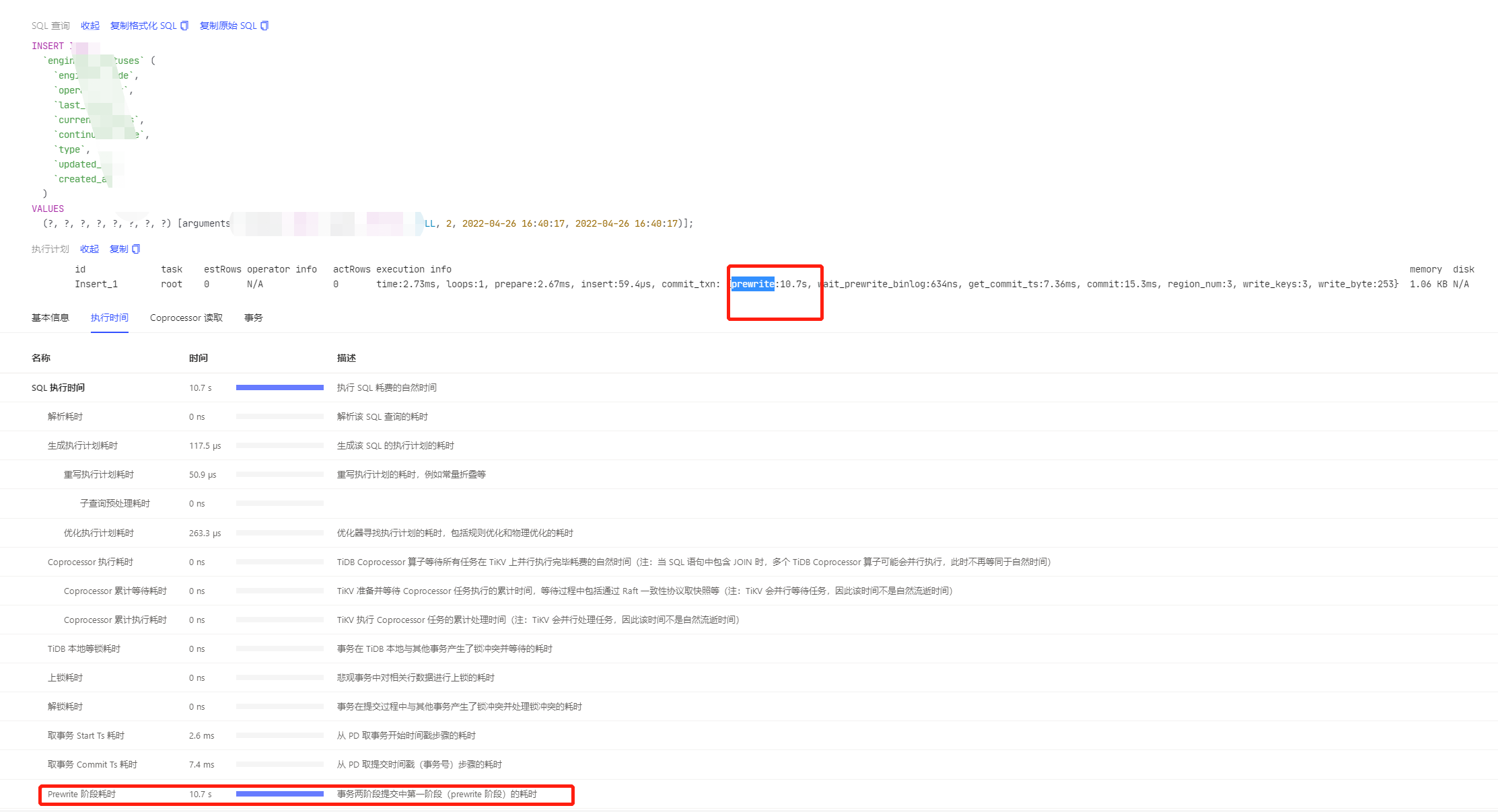
所以一般我可以通过执行计划就能看出来 时间耗费到哪里了对吧
rpc 就是tidb 调用tikv 包含网络时间
cop的 tikv的时间
root是 tidb 时间
明白了
11点15 有一台tikv的CPU高
所以一般我可以通过执行计划就能看出来 时间耗费到哪里了对吧
rpc 就是tidb 调用tikv 包含网络时间
cop的 tikv的时间
root是 tidb 时间
执行计划task列 root 就是tidb server执行,cop[tikv|tiflash] 就是tikv/tiflash执。这个算子task本身执行很快,算子时间长,仅有一个cop task.可能是在某种资源上等待
ASK : 一般我可以通过执行计划就能看出来 时间耗费到哪里了对吧
Answer: 大部分是,但有些时候执行计划也看不出来。如:可能各个 Task 都很快出现了没有统计到的位置,得结合 Grafana 图像和结构知识推出来。还有执行计划看的只是 SQL ,很难反映出数据库组件的运行情况。
ASK : cop的 tikv的时间,root是 tidb 时间
Answer: 同 @h5n1 老师的答案
ASK :rpc 就是 tidb 调用 tikv 包含网络时间
Question: rpc 如果指执行计划中那么是的,但这个时间是并发的(多 tikv),不是串行的需要注意下。
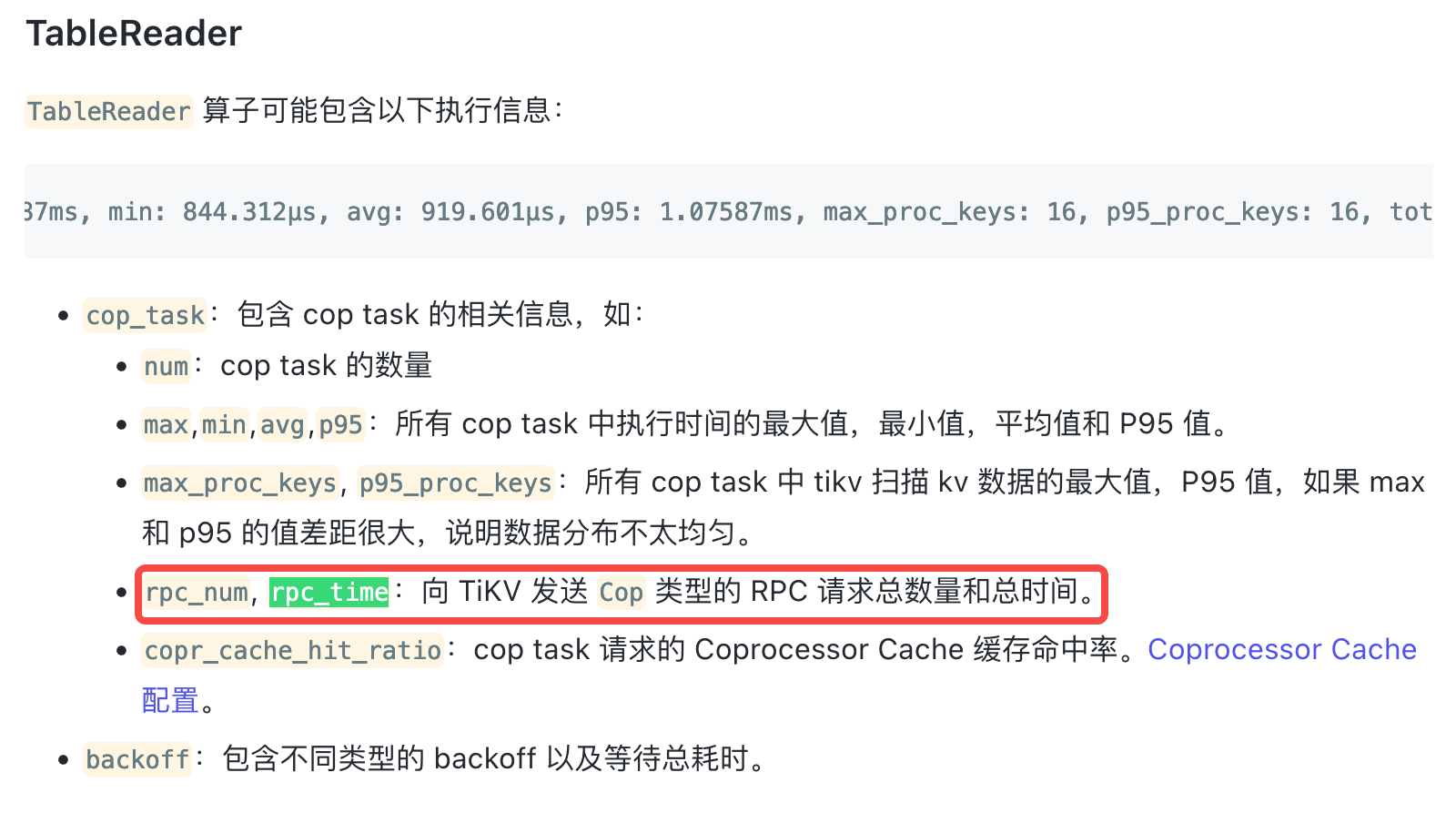
from → https://docs.pingcap.com/zh/tidb/stable/sql-statement-explain-analyze#tablereader
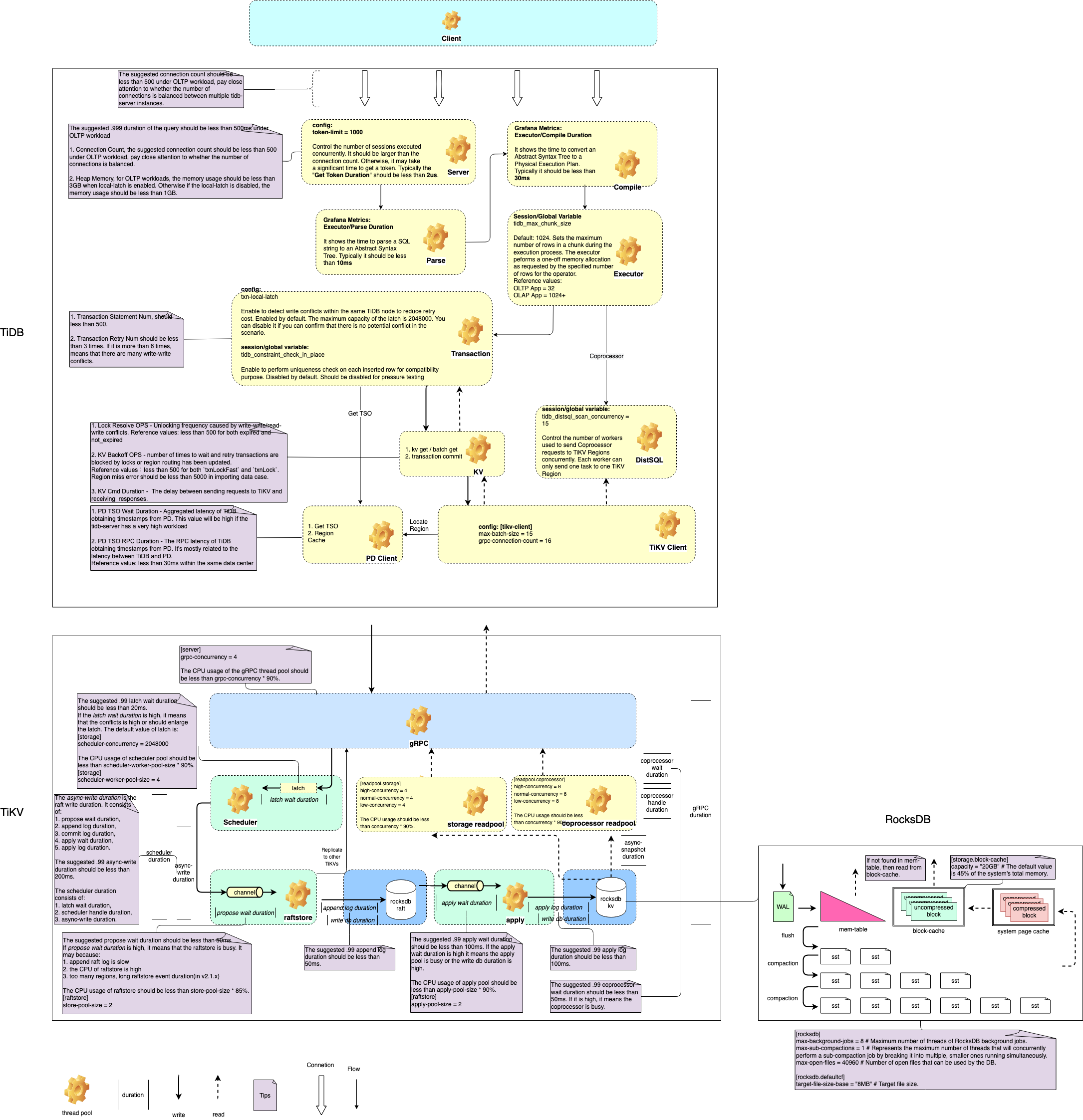
我指的 coprocessor cpu 指的是 tikv 中的线程池占用情况。
我分析第一条 SQL 的时候,因为听描述只是偶尔出现 SQL 执行慢,所以直接忽略了 COP 线程池被打满的情况。归到网络上了。 可能跟这块也有关,需要对应时刻的 对应模块面板证实。
from → https://download.pingcap.com/images/docs-cn/performance-map.png
lock keys相关信息如下,tidb的悲观锁、乐观锁目前都是持久化方式,悲观模式在DML阶段将锁信息写到tikv, 如果网络慢就会影响写入时间,从前面的监控看磁盘没有性能瓶颈,DML的修改操作先写入到tidbserver,在提交时先prewrite写数据(和锁,然后commit阶段写入解锁数据和版本信息, 加锁、解锁都是往tikv写数据实现,建议先看下官方网站上事务相关内容
https://docs.pingcap.com/zh/tidb/stable/sql-statement-explain-analyze#lock_keys-执行信息
感谢大家的回复。
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。



{kind=link}