为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
生产环境,北京 两地 沈阳异地
将leader节点切换在 北京
出现很多慢查询,很简单的sql 有一定的比例出现问题,北京内部两地的机房ping 2-3ms
之后将leader节点固定在一地的机房 后 速度恢复
机器性能都正常
网络正常
不知道从哪入口 查询
这个切换后 时间对比
禁止向异地机房调度 Raft Leader
config set label-property reject-leader dc shunyi
16点 45 切换后
【概述】 场景 + 问题概述
【背景】 做过哪些操作
【现象】 业务和数据库现象
【问题】 当前遇到的问题
【业务影响】
【TiDB 版本】
5.2
【应用软件及版本】
【附件】 相关日志及配置信息
- TiUP Cluster Display 信息
- TiUP CLuster Edit config 信息
监控(https://metricstool.pingcap.com/)
- TiDB-Overview Grafana监控
- TiDB Grafana 监控
- TiKV Grafana 监控
- PD Grafana 监控
- 对应模块日志(包含问题前后 1 小时日志)
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
h5n1
(H5n1)
2
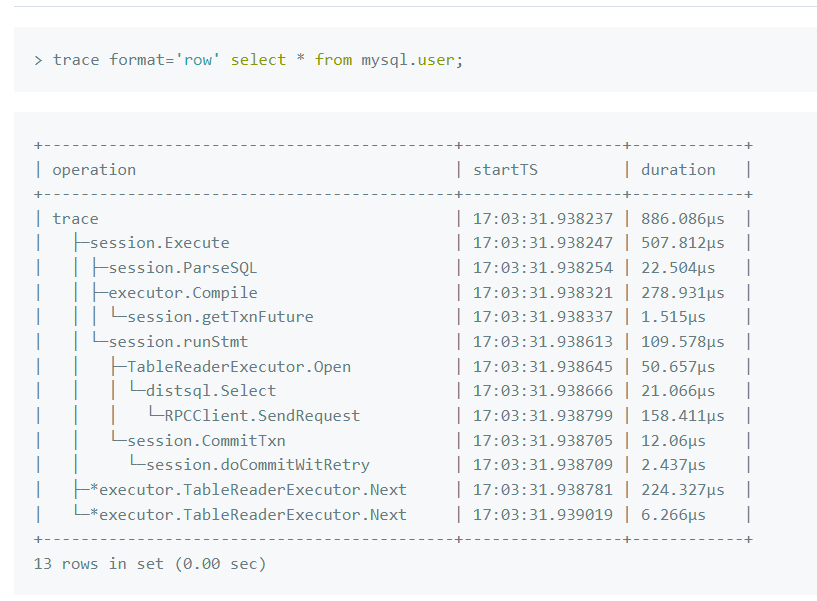
leader在北京2个机房时可以trace 下SQL 看看时间消耗,基本应该是网络造成的延迟,
server.grpc-compression-type: gzip 这参数也设置了吧
有文档 说具体点吗 我不太会,同时我们发现 同一个sql 有一定的比率 导致时间长很多,但是 正常情况不应该那么慢,导致我们两地三中心的方案 没法接受呢
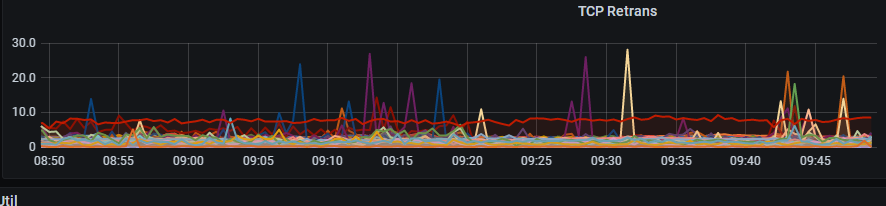
裸光 100G TCP Retrans 这个 有什么方式 排查吗
黑盒监控 有个ping 5S的毛刺
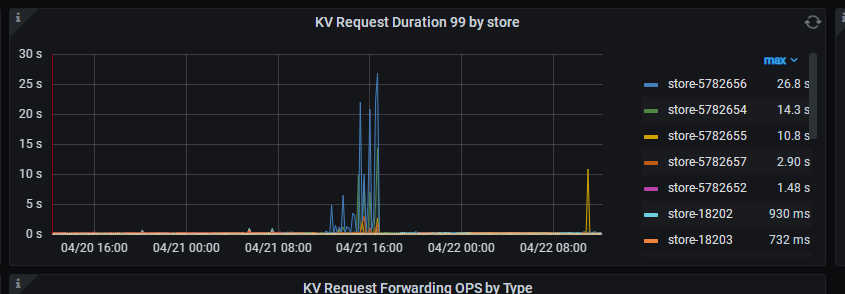
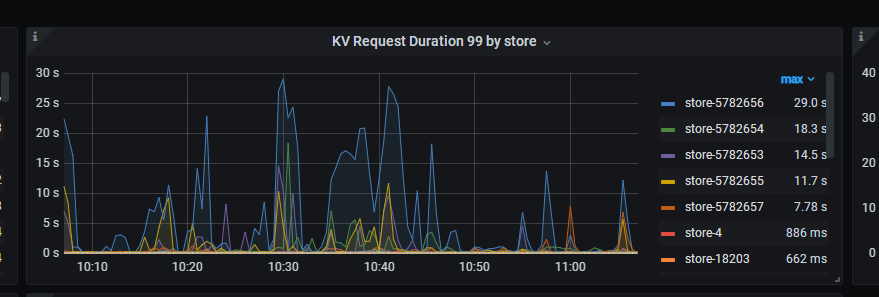
异地的store的相应时间慢了 ,所以是网络问题吗 这个时间 包含网络吗,还是就是tikv的问题
h5n1
(H5n1)
11
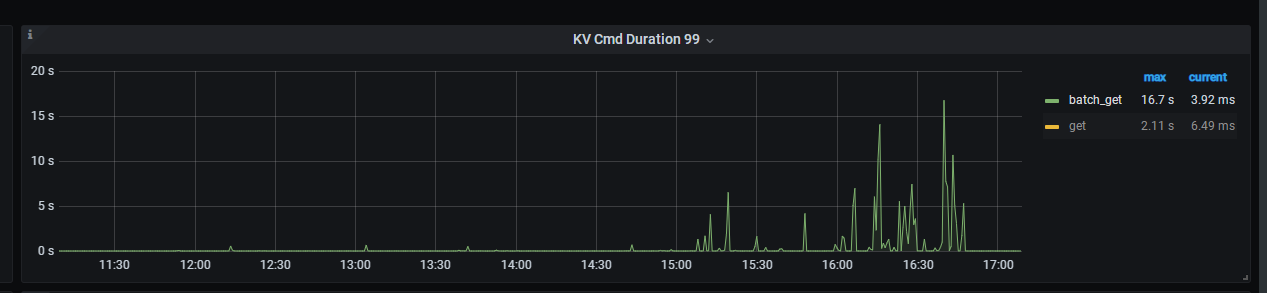
看下tikv监控页面的 TiKV Details --> gRPC --> 99% gRPC message duraion ,如果这个高就是网络问题
2 个赞
同城北京之前ping在2-3ms 异地的ping在16MS左右
h5n1
(H5n1)
15
按下面导出下问题时段overview/pd/tidb/tikv detail监控吧,导出监控步骤:
打开监控面板,选择监控时间
打开 Grafana 监控面板(先按 d 再按 E 可将所有 Rows 的 Panels 打开,需等待一段时间待页面加载完成)
https://metricstool.pingcap.com/ 1 使用工具导出 Grafana 数据为快照
h5n1
(H5n1)
20
上传的没数据,正常导出来文件应该有几M,导出这几个页面,一定要等到所有面板展开,数据加载完