为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【概述】 场景 + 问题概述
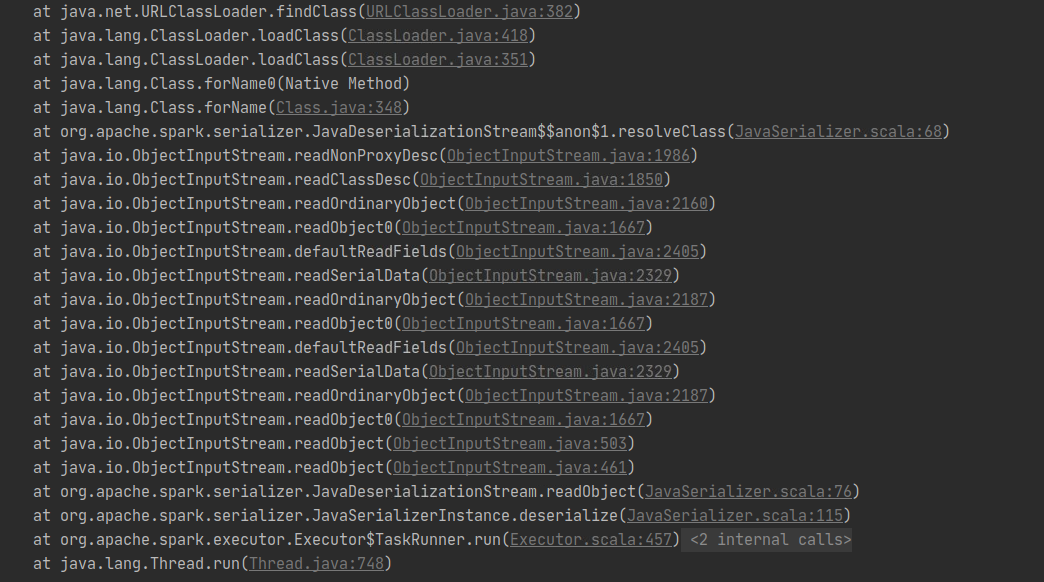
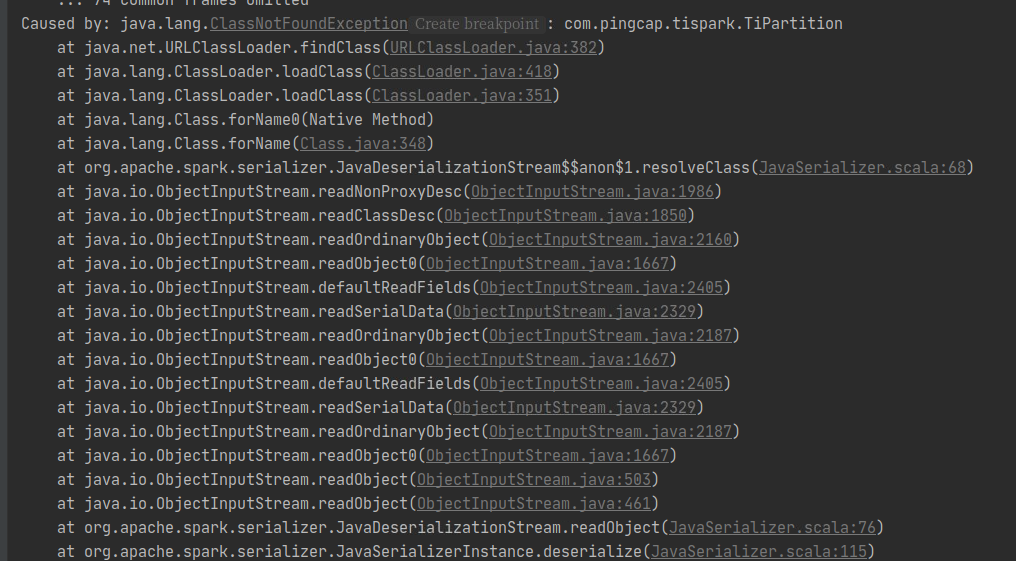
tispark 集成 spring boot,对tidb数据库的数据进行查、改、计算,spark.master 为local[*]时可以正常运行,远程连接集群时报错
【应用框架及开发适配业务逻辑】
【现象】 业务和数据库现象 使用tispark 对tidb进行查、改、计算
【问题】 当前遇到的问题
【TiDB 版本】 5.4
【附件】 相关日志及监控(https://metricstool.pingcap.com/)
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
数据小黑
(数据小黑)
2
spark-submit脚本会做一些jar分发、环境变量设置等操作,tipsark集成spring boot我没这么做过,能说明这么做实现的架构目的,启动方式等细节么?另外,提供一下tipspark的版本,版本不一致参数设置有区别,你截图中是2.4.X的设置,2.5.X有所不同。
1 个赞
使用JDBC读取数据,修改数据,对数据做一些计算,数据量大后达到瓶颈,所以希望使用spark来代替这部分业务。 tispark 2.5.0 spark 3.1.1,目前是在idea上远程连接spark
数据小黑
(数据小黑)
4
配置中增加
.set("spark.sql.catalog.tidb_catalog","org.apache.spark.sql.catalyst.catalog.TiCatalog")
.set("spark.sql.catalog.tidb_catalog.pd.addresses", pd_addr)
尝试一下。
另外,Spark是个运行在分布式环境中独立的计算框架,利用Spark的常规思路是把计算逻辑都迁移到Spark中,而不是把spark嵌入原有的应用,Spark目前适应离线计算,不是即席计算。
你把这个文章整个看一遍吧,改的不止上面一点:
已经修改了,一样的问题,local[*]模式正常,spark://模式还是有问题,,,请问spark 可以submit一个spring boot 程序吗,如果可以请问以什么方式打包,或者用什么打包插件才合理
目前是用spark 作为 查询接口 、软删除(update)接口,计算(规定业务传参时间内的平均值,最大值,最小值,方差等等这些)(计算是目前是从kafka读取指定timestamp数据计算结果写入tidb),表数据量一直增加
数据小黑
(数据小黑)
8
在我的思路里面springboot和spark应该是没有关系才对,spark用maven打包,可以参考官方网站。
system
(system)
关闭
10
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。