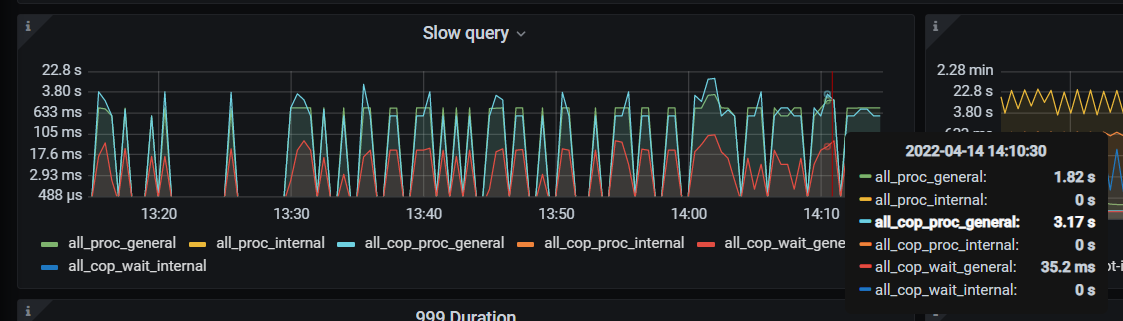
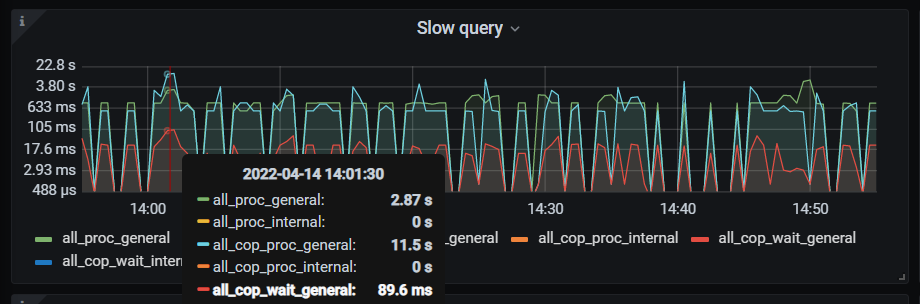
从slow query上面看,有些all_proc_general竟然会比all_cop_proc_general小,这种是什么情况?
all_proc_general应该是整个慢查询的时间?
参考文档:https://docs.pingcap.com/zh/tidb/stable/grafana-tidb-dashboard
- Slow query:慢查询的处理时间(整个慢查询耗时、Coprocessor 耗时、Coprocessor 调度等待时间),慢查询分为 internal 和 general SQL 语句。
还有上面的慢查询时间统计,怎么跟dashboard上面慢查询时间不一样,我在dashboard找了一遍在这个时间段最高慢查询只有2.3s
1 个赞
我记得好像是说因为下面这个 Cop 操作是并发的,在并发操作上时间的计算是将所有的并发耗时进行相加的。
而整体的查询时间,是指从开始到结束的时间,一条线,所以会出现 cop 操作时间大于整个SQL的执行时间的情况。
2 个赞
好像有点问题,就算并发的只算单个最高的,也不该高出总的吧
1 个赞
还有一个问题就是,相同时间段,查看dashboard最高的慢查询时间没有比alloc_proc_general显示的时间高
这个又是什么问题
刚理解错了,grafana上cop是显示的各节点的总和
这个以 Dashboard 为准吧,因为 Dashboard 里面是直接取的日志中 SQL 的信息记录。
Grafana 中的数据,是来自于 Prometheus ,数据一般是经过一些计算后再展现的,有一定的偏差。
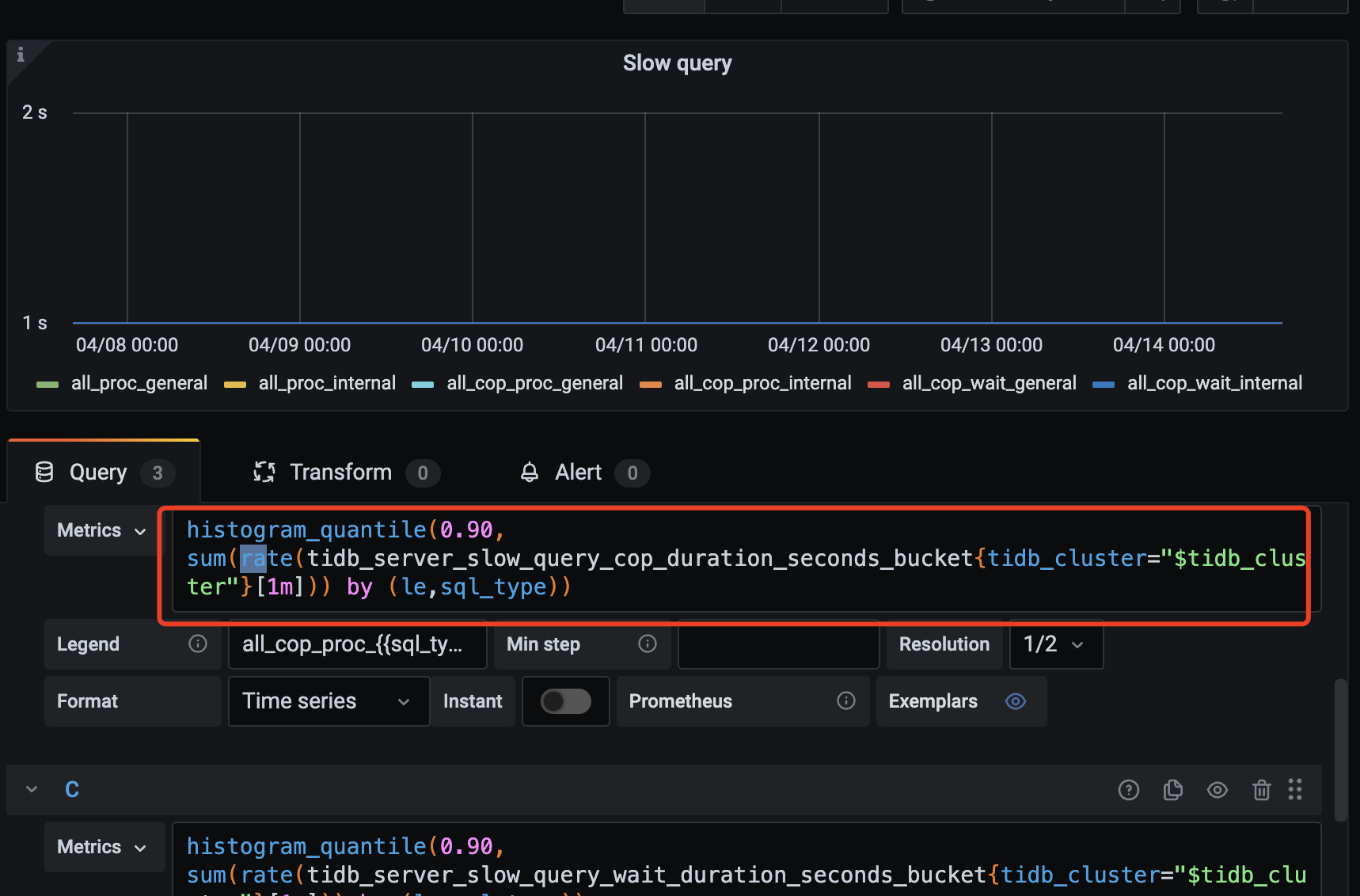
具体计算方法你可以通过点击 Slow query ,Edit 这个面板,看一下 PQL 表达式。这种比较偏统计类的相关知识,n你可以分析下。
system
(system)
关闭
8
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。