【 TiDB 使用环境】测试环境
【 TiDB 版本】5.3.0
【遇到的问题】
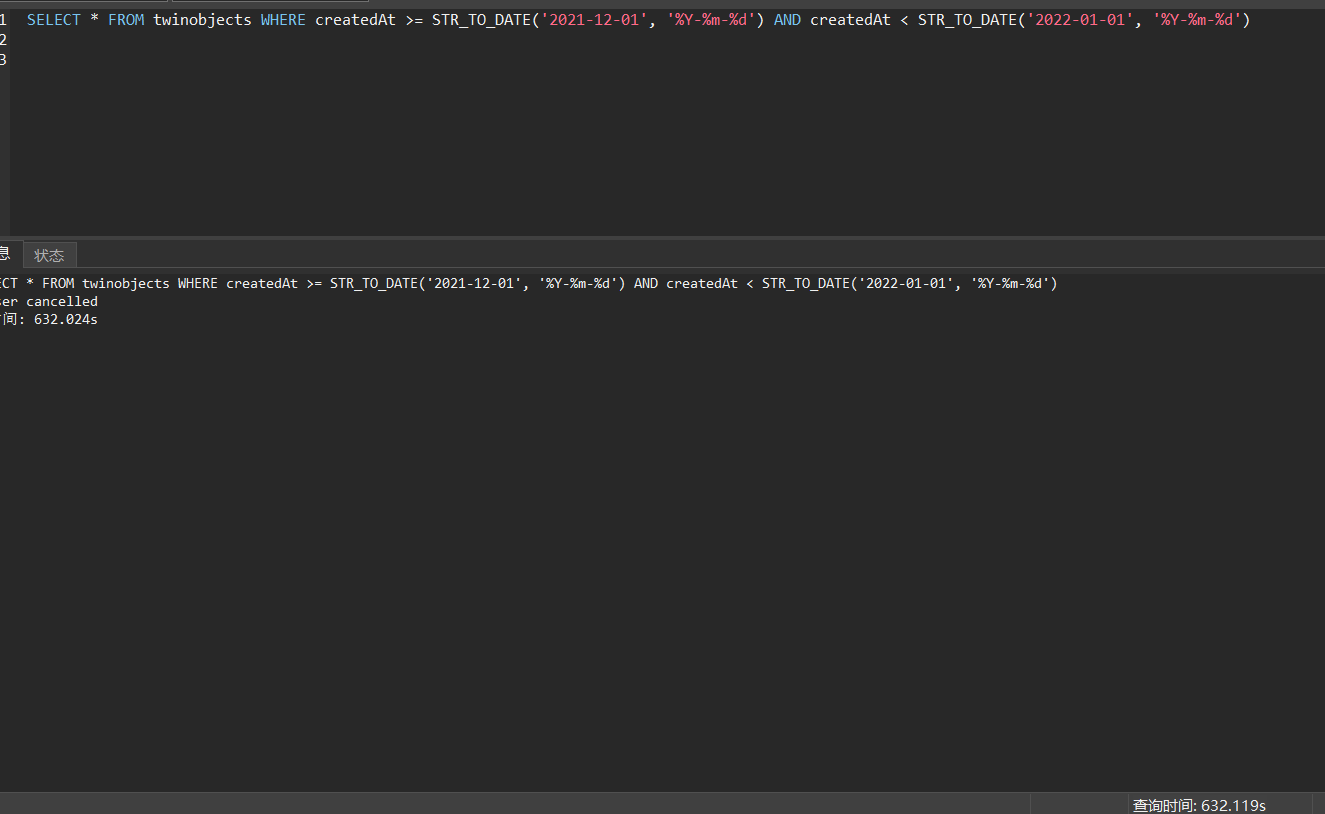
在一张800万数据的表中查询某月的数据,出现整个tidb集群不响应.
【复现路径】做过哪些操作出现的问题
SELECT * FROM twinobjects WHERE createdAt >= STR_TO_DATE('2021-12-01', '%Y-%m-%d') AND createdAt < STR_TO_DATE('2022-01-01', '%Y-%m-%d')
【问题现象及影响】
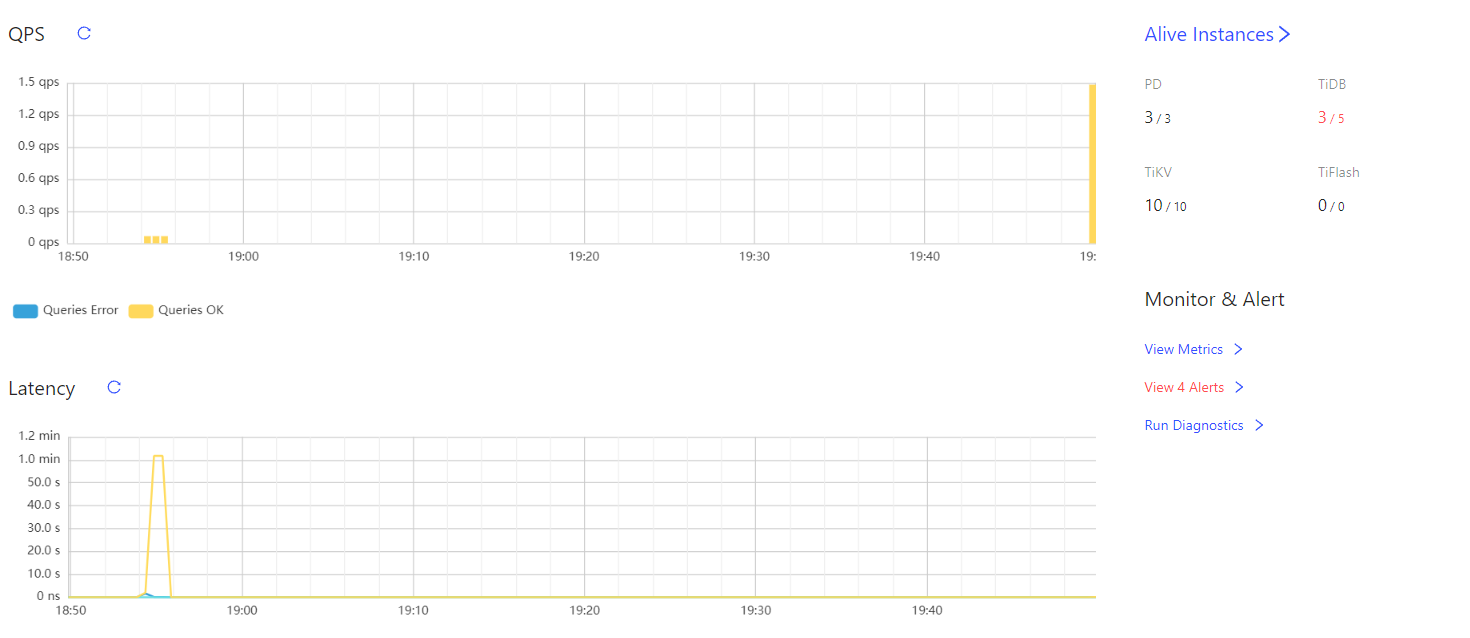
之后任何查询都卡死.无法作任何操作.
是否一定要把监控独立?
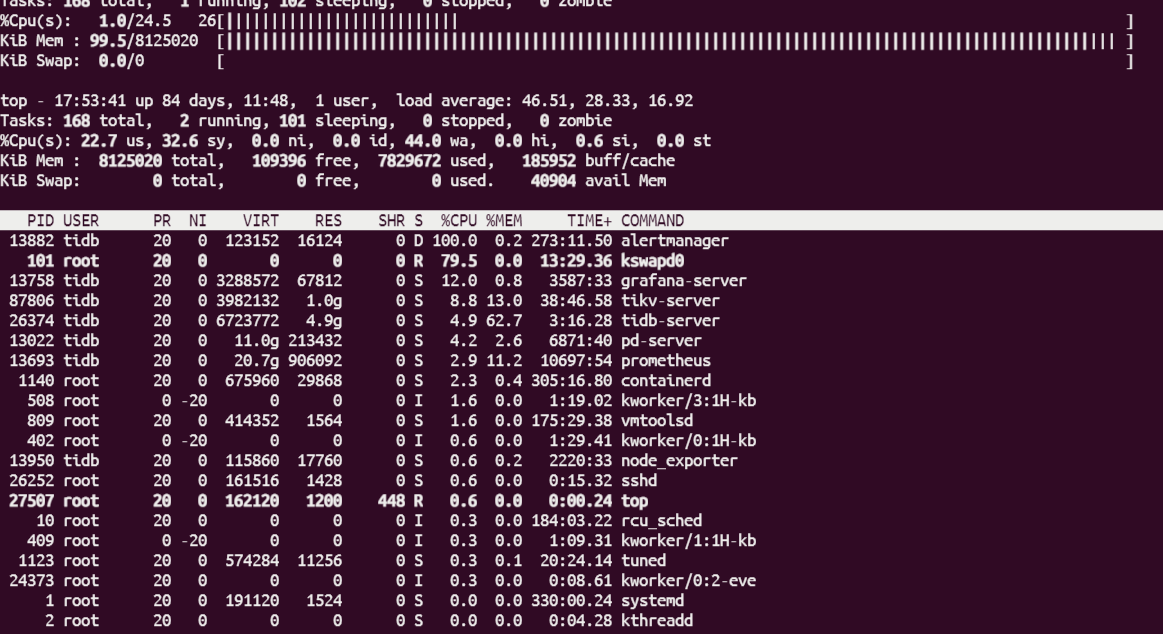
此外除了监控以外发生大数据量查询的时候pd tidb也经常吃满内存造成不响应.
【附件】
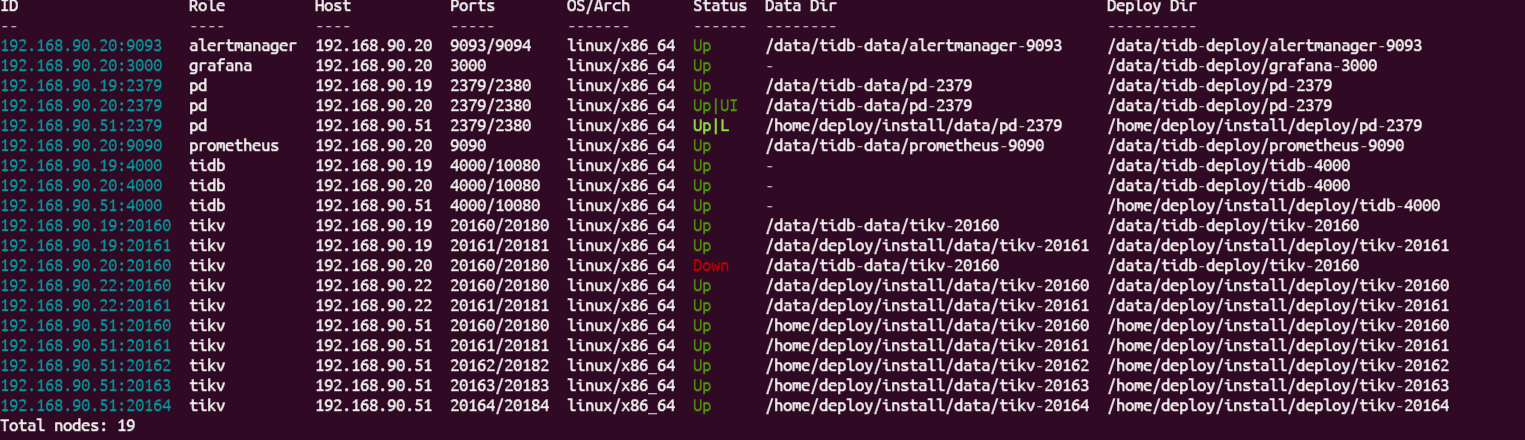
- TiUP Cluster Display 信息
- TiUP Cluster Edit Config 信息
- TiDB- Overview 监控
2 个赞
这一共830万行,没有任何索引,因为是全字段查询,没有任何优化
45个字段.我是分了10个tikv来存储,但是tidb和tidb是放一起的.
1 个赞
我这堆了这么多配置,就是为了测试全表性能的
还有分布式以后regoin分布合理不说秒回,我觉得这些数据量10秒以内没毛病
1 个赞
Kongdom
(Kongdom)
8
带宽是多少?dashboard中慢语句里监控一下这个语句,然后把慢查询详情中的执行时间页签发一下,看看各阶段使用时间。
2 个赞
大致查到原因了,由于监控那边的CPU和内存暴涨导致的.
因为我写反一,写成了 limit 1000, 1000000
这样导致内存暴涨张,监控发现以后不断的alert,我还是把监控分开再试试
另外如果是limit 1000的话返回时间是确定的.
非常感谢给我思路
1 个赞
是的,这条语句返回200万条记录,导致内存 CPU无法承受导致集群卡死.
system
(system)
关闭
15
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。