tidb 版本都是 v4.0.6
配置方法也都是一样的
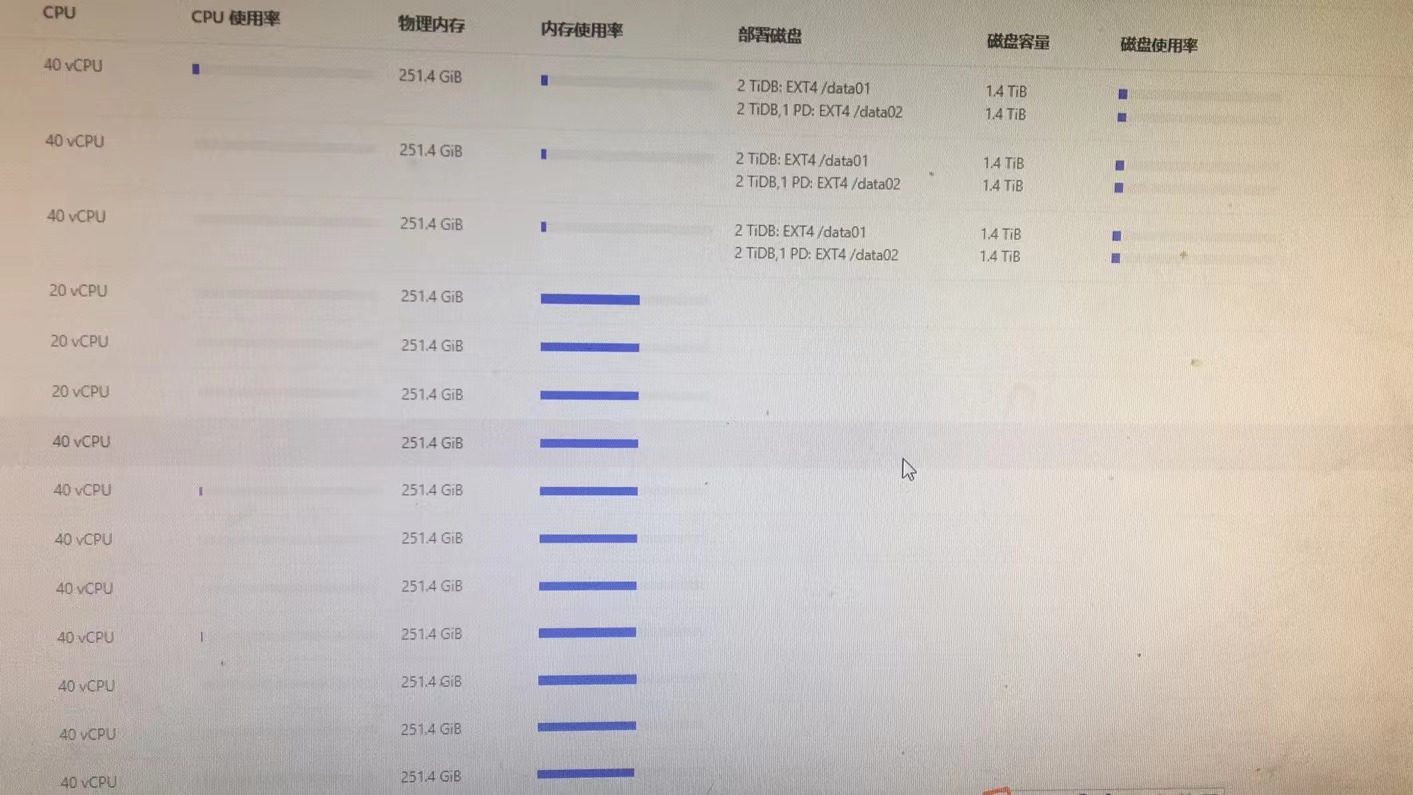
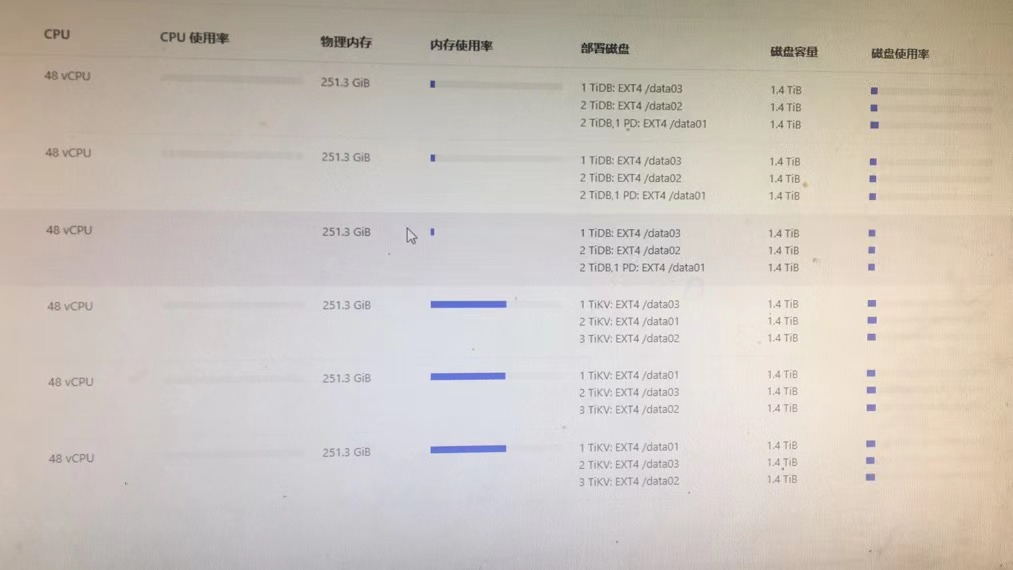
有的dashboard 里面可以监控集群所有节点的 /data 磁盘
有的dashboard 里面只能监控部分节点的 /data 磁盘
没监控出来的也都是ext4么
是的, 我们所有集群的所有data 磁盘格式都是 ext4的
磁盘属性参数也都是一致的
辛苦看下不显示磁盘信息节点的以下几点:
1.node_exporter、blackbox_exporter 进程都正常存在运行
2.这些都是什么,tikv,tidb,还是其他
3.运行下面两个sql
select * from INFORMATION_SCHEMA.CLUSTER_LOAD where instance=‘ip:port’;
select * from INFORMATION_SCHEMA.CLUSTER_HARDWARE where instance=‘ip:port’;
结果发下,看是否有磁盘相关信息,对应的ip,port就行没显示磁盘信息的节点的ip,port
4.看下prometheus的配置是否和其他几个节点一样
1.node_exporter、blackbox_exporter 进程都正常存在运行
查看node_exporter、blackbox_exporter经常运行都是正常的, 和其他正常节点比对已了 node_exporter进程上缺少 --colllector.buddyinfo参数,
发现异常的集群所有节点node_exporter进程上缺少 --colllector.buddyinfo参数, 其他正常集群所有集群node_exporter都有–colllector.buddyinfo参数
在网上查了下buddyinfo,如图说明:
是不是 没有 启用 --colllector.buddyinfo 收集器的原因呀?promeithous 都是部署集群是自动部署的,没有特地设置什么
我们部署和启动对promethous 没有配置任何东西, 但是有个别集群中所有服务器node_exporter 中都没有–colllector.buddyinfo参数, 但是其他集群中的机器node_exporter都有–colllector.buddyinfo参数, 不知道是什么地方的配置影响了
如果是这个问题的话,如何才能让node_exporter 启用–colllector.buddyinfo参数呢? 有和我有同种情况的吗?
稍等,我这头看一看,晚些回复你
老师, 麻烦您帮忙确认一下是否是–colllector.buddyinfo参数未启用 导致的, 如果是 那么如何启用该参数?
不好意思啊,公司这两天比较忙,可能回复的比较慢
你去/home/tidb/.tiup/storage/cluster/clusters/cluster-name/config-cache
下的对应节点的run_node_exporter***.下,没有该配置的节点是不是有不同的配置呢
启动方式的话可以看下对应节点的启动脚本
/monitor-9100/scripts/run_node_exporter.sh
同时也可以看看这里面的内容有没有该参数
老师好:
1、我按照你说的检查了一下配置文件, dashboard 监控不到磁盘信息的集群 config-cache/run_node_exporter*** 中没有–colllector.buddyinfo 参数, 其他正常集群是有这个参数的
2、但是我们部署的测试环境也没有–colllector.buddyinfo 参数,dashboard 可以正常监控到数据目录信息(这套是虚拟机 使用的目录是opt),所以 感觉监控不到 磁盘信息好像跟这个参数也没关系(异常的都是核心生产环境不敢动)
3、/monitor-9100/scripts/run_node_exporter.sh 比对了这个脚本启动参数和改集群config 中的一致,
有一点不同的是是dashboard监控异常的和测试环境的 比监控正常的少了个变量, (一个启动命令所在目录设置了变量,一个未设置,通过比对应该也和这个没有关系)
1.这个参数应该不影响,
,具体参数可以代表的作用可以看看这篇链接,https://devopstack.cn/监控/1574.html,影响磁盘的应该是mountstats参数辛苦看下对应节点的node_exporter的日志,是不是有error的情况
/data/tidb/tidb-deploy/monitor-9100/log
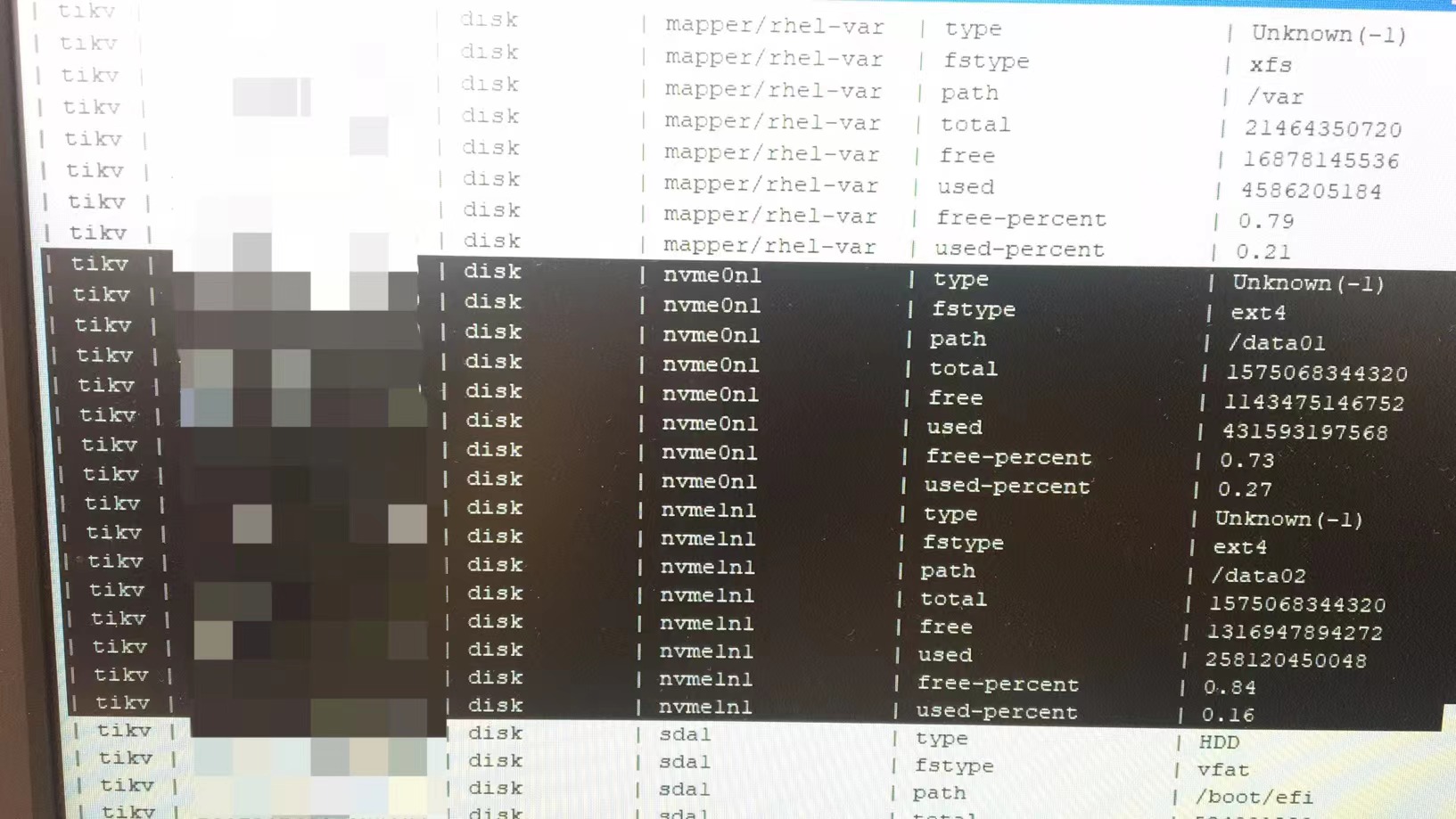
另外。我这里看了下node_exporter进程,里面的参数是–collector.systemd --collector.textfile --collector.textfile.directory
所以看起来信息采集走的是system.我的理解就是查看的是/proc下的内容,也可以根据这个看看有没有什么不同
之前也有看到过,rootfs 是 TiKV 上报的问题,把 virtual file system 弄出来了,新一点的版本就显示正常了
![]() 原来如此,我安装一个新的版本试试
原来如此,我安装一个新的版本试试
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。