HACK
2022 年4 月 1 日 07:50
1
【 TiDB 使用环境】
执行split table命令报错了,报错代码是ERROR 1105(HY000),t1 region step value should more than 1000, step 317 is invalid
我在社区上搜索这个报错代码,发现这个报错代码还代表其他意思:
跟我的报错信息不一样。
看样子是把一类报错归类到一个报错代码。
【背景】:做过哪些操作
1 个赞
HACK
2022 年4 月 1 日 08:17
3
mysql> split table t1 between(82461) and (88804) regions 20;
HACK
2022 年4 月 1 日 08:18
6
CREATE TABLE t1 (
id INT NOT NULL PRIMARY KEY auto_increment,
b INT NOT NULL,
pad1 VARBINARY(1024),
pad2 VARBINARY(1024),
pad3 VARBINARY(1024)
);
HACK
2022 年4 月 1 日 08:20
8
我这个split table,为啥会报错呢?是内部有限制吗?
h5n1
2022 年4 月 1 日 08:23
9
提示就是显示region step value should more than 1000, step 317 is invalid, 你设置成regions 6
h5n1
2022 年4 月 1 日 08:27
11
由于 row_id 是整数,所以根据指定的 lower_value 、 upper_value 以及 region_num ,可以推算出需要切分的 key。TiDB 先计算 step( step = (upper_value - lower_value)/region_num ),然后在 lower_value 和 upper_value 之间每隔 step 区间切一次,最终切出 region_num 个 Region
相当于每个region的数量吧
HACK
2022 年4 月 1 日 08:37
12
是不是说,这个step大于1000,是内部机制已经定义好的,必须大于1000?
TiDB 先计算 step (),然后在 和 之间每隔 step 区间切一次,最终切出 个 Region。 row_id lower_value upper_value region_num step = (upper_value - lower_value)/region_num lower_value upper_value region_num
Split Region 使用文档 |PingCAP 文档
MrSylar
2022 年4 月 1 日 08:57
15
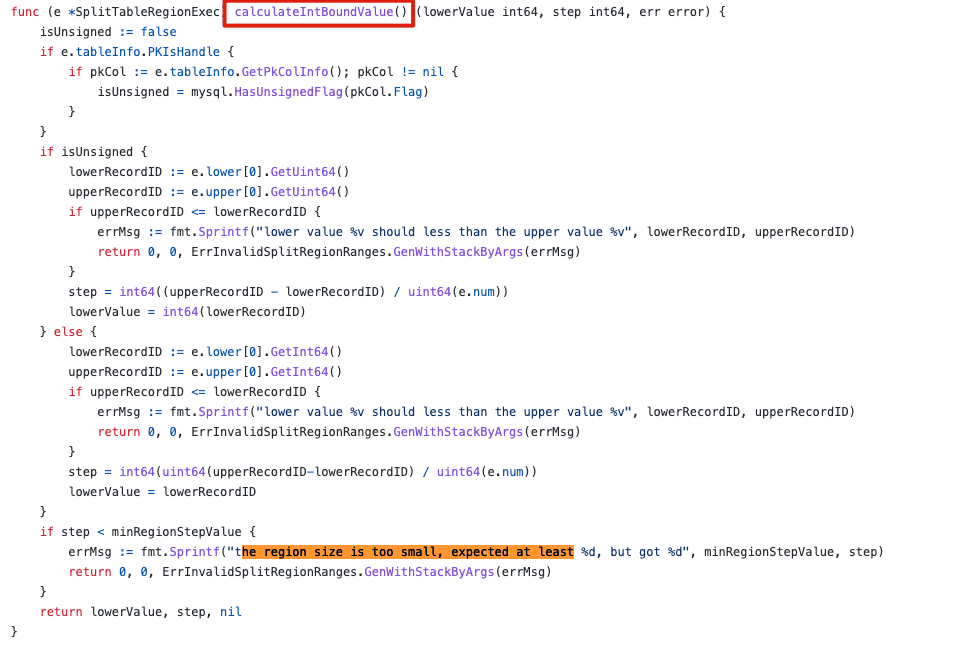
读TiDB 源码
https://github.com/pingcap/tidb/blob/v5.4.0/executor/split.go https://github.com/pingcap/tidb/blob/v4.0.16/executor/split.go
var minRegionStepValue = int64(1000)
在 4 版本的时候会报该错误:%s region step value should more than %v, step %v is invalid”, e.tableInfo.Name, minRegionStepValue, step)
2 个赞
dba-kit
2022 年4 月 2 日 08:05
17
不过这样设计的话,就没办法预分配分区了,比如说,可能订单表里主键里有个时间字段,在大促之前,可以预计某个区间段的数据量会比较大,针对某个时间段提前做下预分区,这样真正有数据写入时,就不会产生热点了。
dba-kit
2022 年4 月 2 日 08:27
18
不过我测试起来,貌似并没有限制每个region的大小
mysql> select * from test.`add_column`;
+----+-------+----+-------+
| c1 | c2 | c3 | c4 |
+----+-------+----+-------+
| 1 | apple | 1 | apple |
| 2 | bob | 2 | bob |
| 3 | cat | 3 | cat |
+----+-------+----+-------+
3 rows in set (0.07 sec)
mysql> split table test.`add_column` between (1, 'apple') and (1000, 'xx') regions 100;
+--------------------+----------------------+
| TOTAL_SPLIT_REGION | SCATTER_FINISH_RATIO |
+--------------------+----------------------+
| 99 | 1 |
+--------------------+----------------------+
1 row in set (0.54 sec)
mysql> select count(1) from information_schema.TIKV_REGION_STATUS where DB_NAME='test' and TABLE_NAME='add_column';
+----------+
| count(1) |
+----------+
| 101 |
+----------+
1 row in set (0.02 sec)
dba-kit
2022 年4 月 2 日 08:33
20
可能是只针对int类型来判断的,加1000的限制确实还算可以理解,不过报错提示可以更明显一些