课程名称:2.3.1 How to Deploy TiDB Platform with TiUP(如何通过 TiUP 部署 TiDB)
学习时长:
2h
课程内容:
什么是TiUP
- TiDB4.0引入的组件管理工具
- 提供部署,组件下载,分发等功能
- 单一二进制文件,命令行工具
TiUP核心理念
- 一切都是组件
- tiup后面的参数不是tiup的参数,是组件的参数,版本号可以不写,默认为最新版
- TiUP可以设置指定仓库Mirrors,和yum,apt类似
- 离线安装
- 可以设置内网镜像
- 或者本地文件系统



本地测试(playground)

线上环境(cluster)

- yaml文件配置
TiUP集群部署yaml配置文件
目录分global和各个组件中的,组件中的配置会覆盖global的配置
-
部署目录
- 绝对路径
- 相对路径:上面指定用户的家目录下/home//<deploy_dir>/…
-
数据目录
- 绝对路径
- 相对路径:上述组件目录下/
-
日志路径
- 和上述数据目录相同
- 和上述数据目录相同
-
server_configs
- 生成配置文件
-
pd_servers
- client_port 客户端通信端口
- peer_port pd之间通信端口
- numa_node:需要numactl命令,这个是绑定cpu用的
-
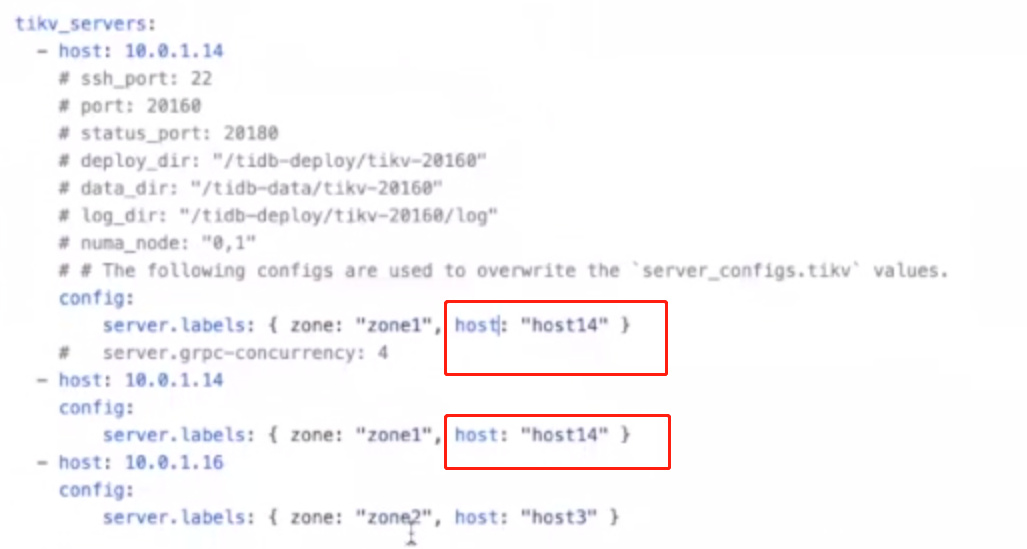
tikv_servers
- server.labels: { zone: “zone1”, host: “host1” }
- 如果一台机器启动多个tikv实例,需要将上述配置写入tikv的config,并且要将某一个字段要写成一样的,如host字段,并且要将该字段写入到pd里面,以便pd可以识别,这个地方主要是防止pd调度时将region放入同一个机器上面,这样该机器宕机会有丢数据的风险
-
tiflash_servers
- 可以有多个数据目录,用逗号隔开
- 可以有多个数据目录,用逗号隔开
-
drainer_servers
- commit_ts
- 如果没有做checkpoint,就是用这个值做初始checkpoint
- 如果是-1,从pd里面过去最新的时间戳,把这个时间戳当成checkpoint来使用
- 下游实例要先于drainer启动
- commit_ts
-
tispark_masters
- 使用spark_config和spark_env配置文件,不使用config字段
-
monitoring_servers
- prometheus
- roles_dir 这个字段目录是运行TiUP机器上的目录,不是目标机器的目录
- 上面目录自己定制的roles,需要全量copy yaml文件,不是单个
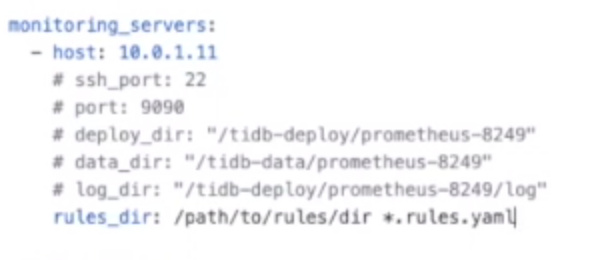
-
grafana_servers
- 和prometheus 差不多,可以自定义面板
- 目录也需要在tiup机器上
- 也需要将全量的json文件拷到目录上

-
alertmanager_servers
- 目录需要在tiup机器上
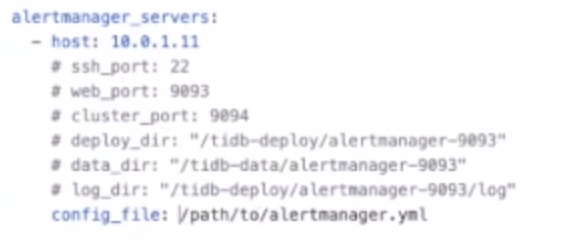
- 目录需要在tiup机器上


更改配置
- 只能修改生成config相关的配置,目录和端口等是不能修改的
- 加减机器只能通过scale-out或scale-in命令,不能在配置文件中添加或删除
- 修改后需要reload才会生效