课程名称: 2.1 When to use TiDB platform(TiDB 的适用场景)
学习时长:20min
课程收获:TiDB 的一些典型使用场景,大致的判断哪些场景适合 TiDB,哪些不适合
课程内容:
-
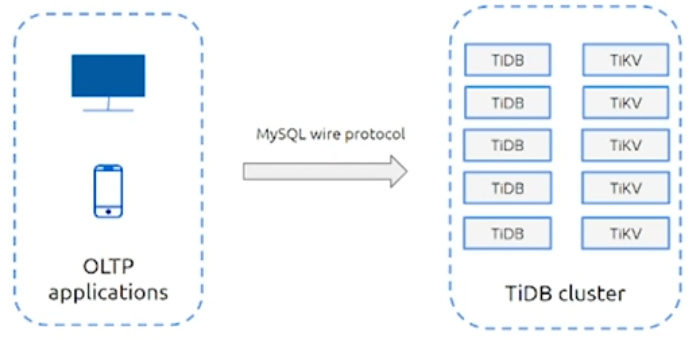
OLTP场景
-
随机、实时读写海量数据(数十亿级别,billions of rows),且
- 符合ACID
- 二级索引支持
- MySQL协议
-
实时HTAP场景
-
实时HTAP,即Hybrid transactional/analytical processing
-
使用TiFlash进行OLAP原地查询
- 新鲜数据
- 对OLTP性能零干涉
-
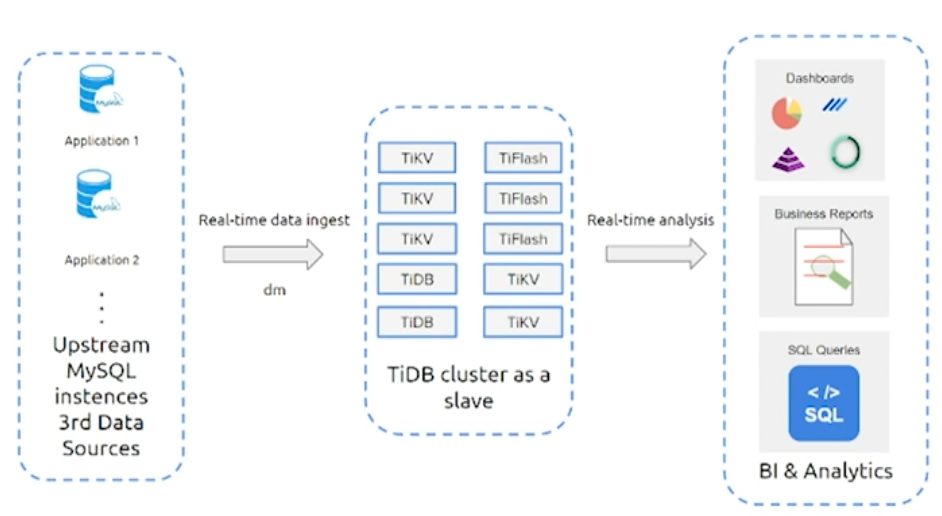
数据汇总
- 可以作为上游数据库的从库,进行汇总OLAP查询
-
-
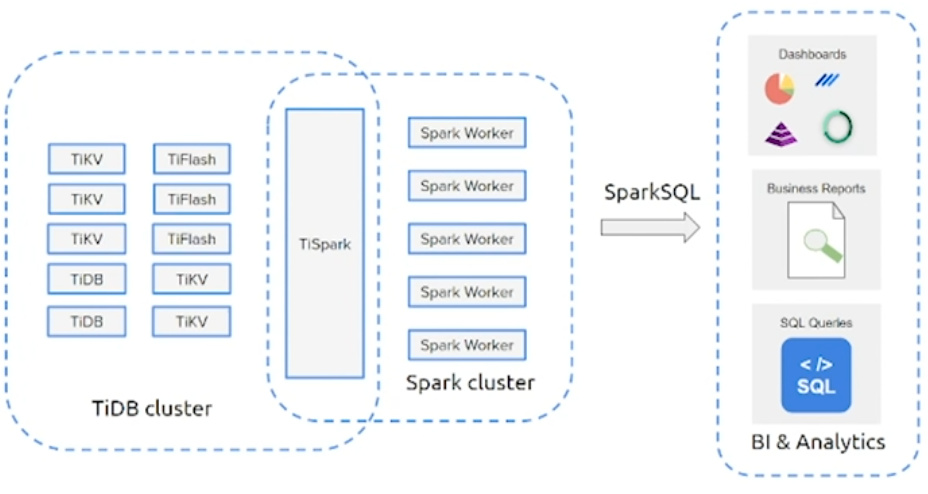
通过TiSpark连接到Spark生态系统
-
通过TiSpark,可以使用Spark在原地处理TiDB中的数据
-
适用于如下负载
-
迭代处理
- 比如传统ETL
-
连接数据集
- 从多数据源连接海量数据集
- 大量混排和排序
-
-
- ![]
-
-
不太适合的场景
-
单机可容纳的数据规模
-
重分析任务
- 在海量数据集上扫描、聚合(多张表,每张表几亿,要做join),或中间结果单机内存无法承载
- 即TiDB并不是传统的重型数据仓库解决方案,更偏重于实时处理
-
亚毫秒级延迟
- 可以考虑Redis?
-