TiDB 中的读写流程
Part I:Introduction of TiDB Platform
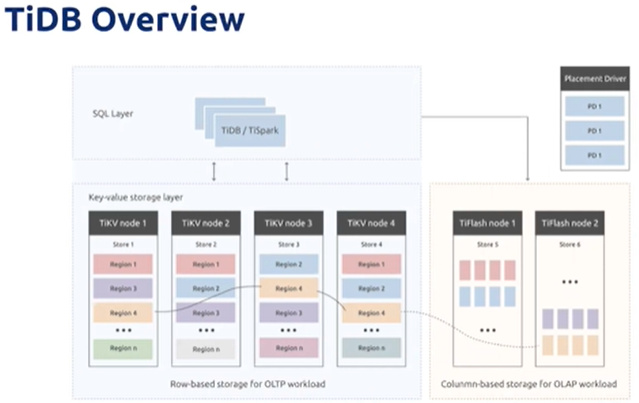
TiDB:负责SQL处理
PD:负责调度
TiKV:负责存储
TiSpark:与Spark结合的入口
TiFlash:列存储引擎
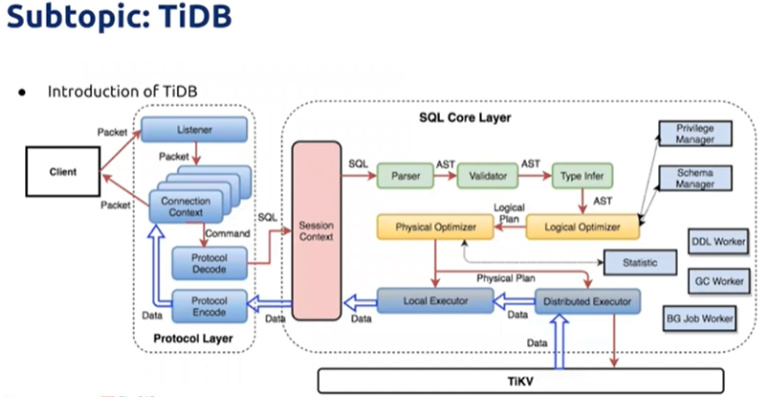
数据库的SQL层,负责SQL的解析和优化,最终生成分布式执行计划
其本身是无状态的,可以启动多个TiDB实例,客户端的连接可以均摊在多个TiDB实例上
TiDB本身不提供负载均衡的能力,需要借助第三方工具来实现
TiDB Server本身并不存储数据,只是解析SQL将实际的SQL请求转发给底层的存储层(TiKV)
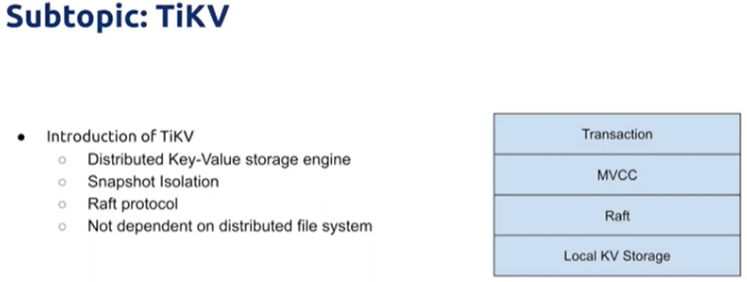
一个分布式KV存储引擎,具有高度分层特性,通过Raft协议保证数据的一致性
具有MVCC特性,实现事务的多版本并发控制
不依赖于分布式文件系统
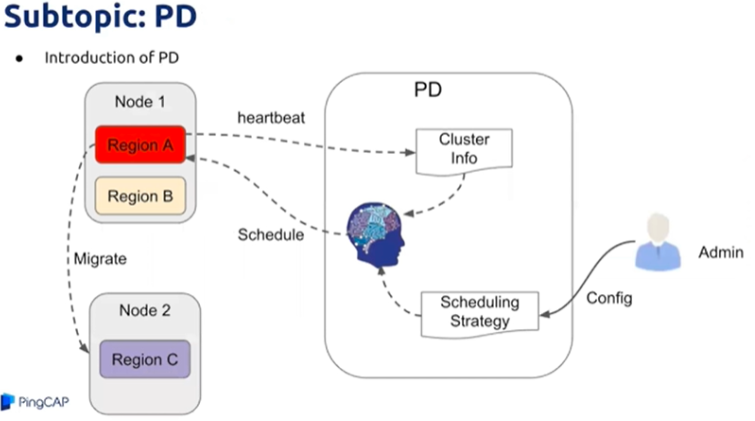
是TiDB集群的“大脑”,负责分配分布式事务ID,事务在开始以及提交的时候需要获取一个全局唯一的TSO号
实现region以及leader的调度,让负载均衡分配至TiKV节点上
提供Dashboard功能,方便检查管理集群状态
Part II:Read Request in TiDB
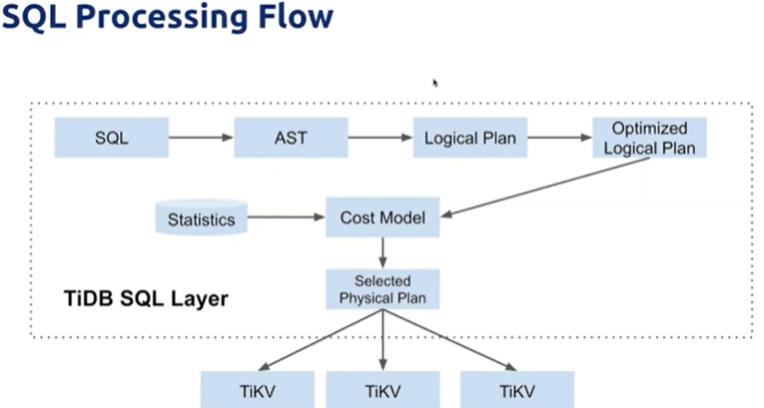
- SQL转化为AST抽象语法树
- 生成逻辑执行计划
- 优化逻辑执行计划
- 依据CBO选择实际执行计划
- 依据实际的执行计划将请求发送给TiKV节点
读请求在TiDB的处理过程
- 客户端与TiDB建立链接,并发送请求
- TiDB接受客户端发送的请求,获取客户端发送的SQL语句
- TiDB进行parses和compiles阶段,对SQL文本进行解析,生成AST语法树,并进行优化
- TiDB与PD交互获取start_ts信息
- TiDB根据执行计划以及表的元数据信息生成executor执行器
- TiDB通过gRPC请求的方式将coprocessor请求发送给TiKV层
- TiKV接受到请求并按照请求过滤数据,并将数据返回给TiDB
- TiDB接收到所有TiKV返回的请求后,整理汇总数据
- TiDB将结果反馈给客户端
Part III:Write Request in TiDB
写请求的处理过程
※1~5步与读请求的处理过程是一致的
- 客户端与TiDB建立链接,并发送请求
- TiDB接受客户端发送的请求,获取客户端发送的SQL语句
- TiDB进行parses和compiles阶段,对SQL文本进行解析,生成AST语法树,并进行优化
- TiDB与PD交互获取start_ts信息
- TiDB根据执行计划以及表的元数据信息生成executor执行器
- TiDB发起commit请求
- 参照percolator进行二阶段提交(prewrite阶段/commit阶段)TiDB会在二阶段的commit阶段向PD请求获取commit_ts
- TiKV将提交的结果返回给TiDB
- TiDB将结果反馈给客户端