课程名称:101+1.3 A Brief History About the TiDB database platform(TiDB 发展简史)
学习时长:25min
课程收获:
介绍了 TiDB 的发展历史。自从 v1.0.0 GA 开始,TiDB 做到了:可以从计算和存储两个层面的无限扩展,兼容了 MySQL 的语法和协议,强一致的真分布式事务。到今天,TiDB 可以称为一个真正的 HTAP 系统,不需要 ETL 工具进行数据转换,在系统运行 OLTP 业务时,也可以方便的进行报表查询。
一、早期TIDB简介;
二、TiSpark简介;
三、TiFlash简介;
四、现代的TiDB;
课程内容:
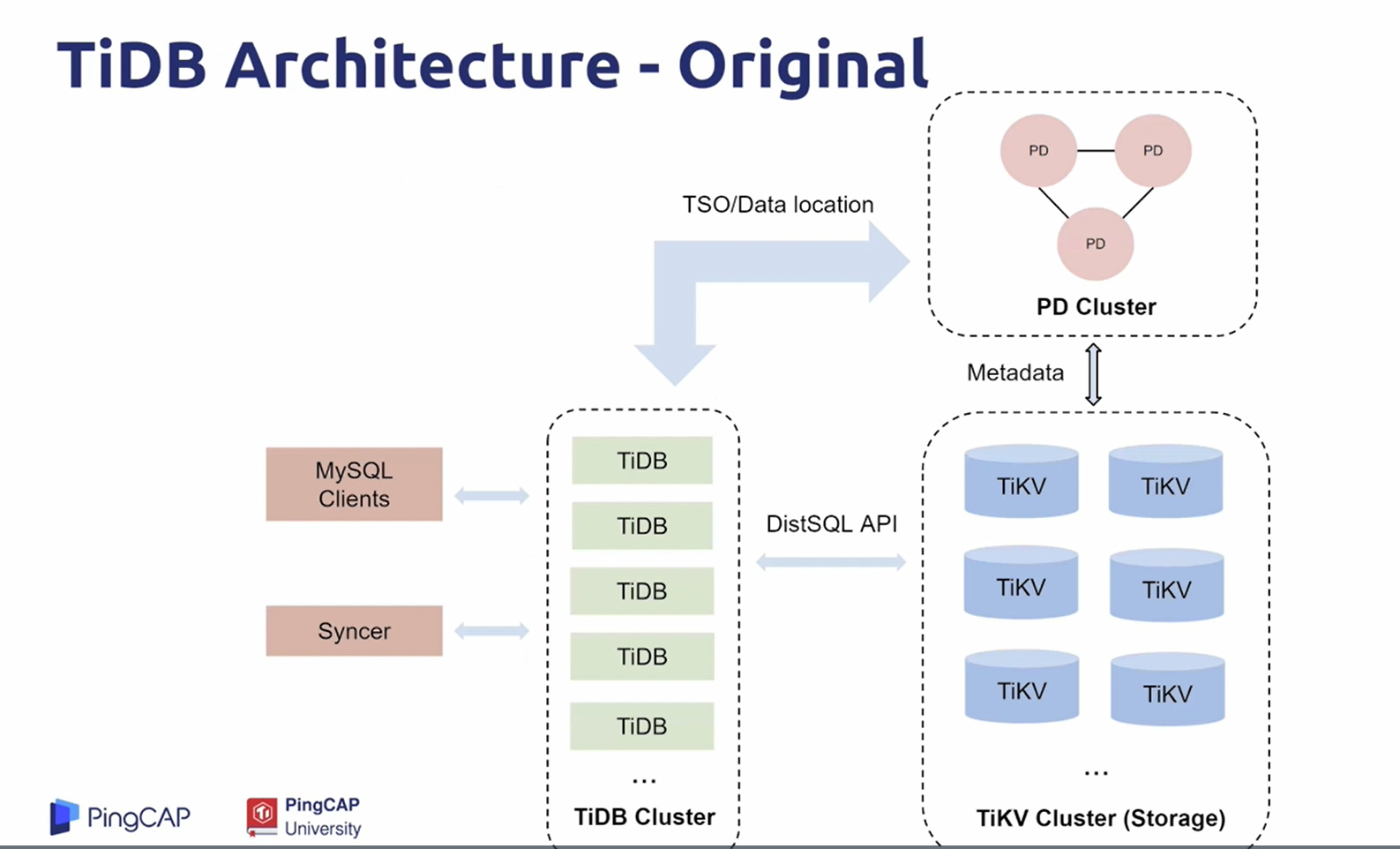
一、早期TiDB:
- 可以从计算和存储的两个层面的无线扩展;
- 兼用Mysql语法和协议;
- 强一致的分布式事务支持;
- 分为3个组件TiDB(无状态的SQL引擎,前端计算时可多实例启动),TiKV(分布式存储引擎,用Raft算法进行副本之间的复制来保证高可用),PD(主管元数据的存储以及TiKV之间的调度);
- 由于具备无线横向扩展的特性,TiDB可视为容量无线大的MySql;
-
数据中台:
(1)TiDB是中台数据场景的理想选择;
(2)协议兼容,容易同步mysql生产库;
(3)透明和可访问的交叉分割查询;
(4)数据的实时性;
(5)海量存储允许多个数据源汇聚;
(6)备机和中台合二为一;(在中台场景通过Syncer向TiDB进行数据的汇总,由于协处理器的存在,汇总的数据可以在TiKV中进行聚合,生成报表)。 -
缺点:
(1)在tp场景下,有点问题,影响不大;
(2)在ap场景下,复杂查询太慢、经常OOM(内存溢出)、无法和大数据平台整合"。
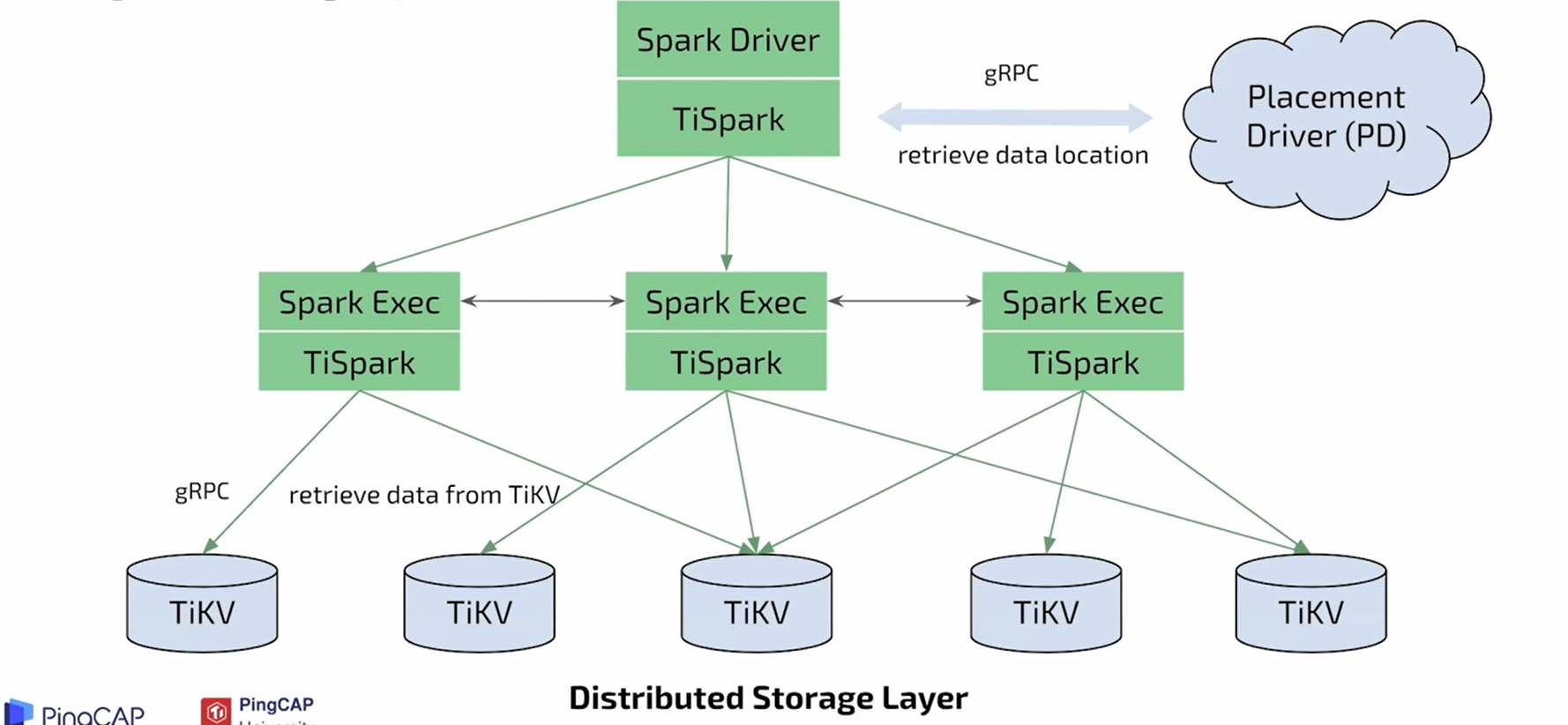
二、TiSpark:
- 将TiDB的计算能力扩展为多点变形计算;
-
优点:
(1)提供分布式的计算框架,更快也更稳定;
(2)无缝接入大数据生态,在脚本、Python、R语言都可以轻松操作tidb集群; - 缺点:并发性低并且消耗大量计算资源;
-
TiDB优化:简单优化器到加入RBO和CBO的优化器,到将来支持cascades optimizer,执行器从火山模型到批量执行到向量化执行以及更好的并发控制,外加一些新特性,比如分区表、index merge等,这些都对复杂计算有巨大的提升;
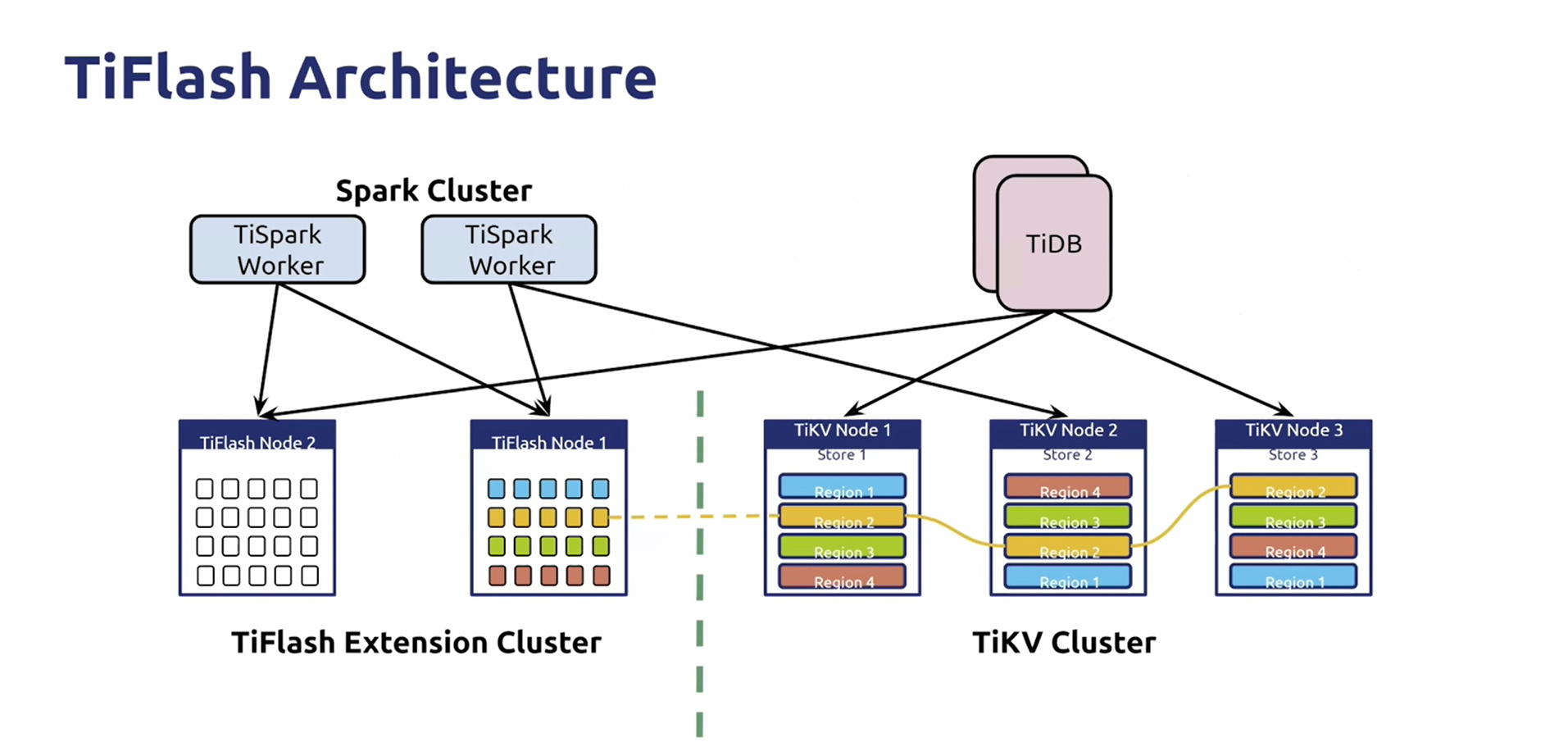
三、TiFlash:
- 通过Raft Learner向列存储引擎同步一份数据:
(1)同步代价极低的问题;
(2)读取通过Raft Index结合MVCC实现了强一致读。 - 通过打标签的形式实现了物理的隔离,使AP和TP的负载不互相影响"。
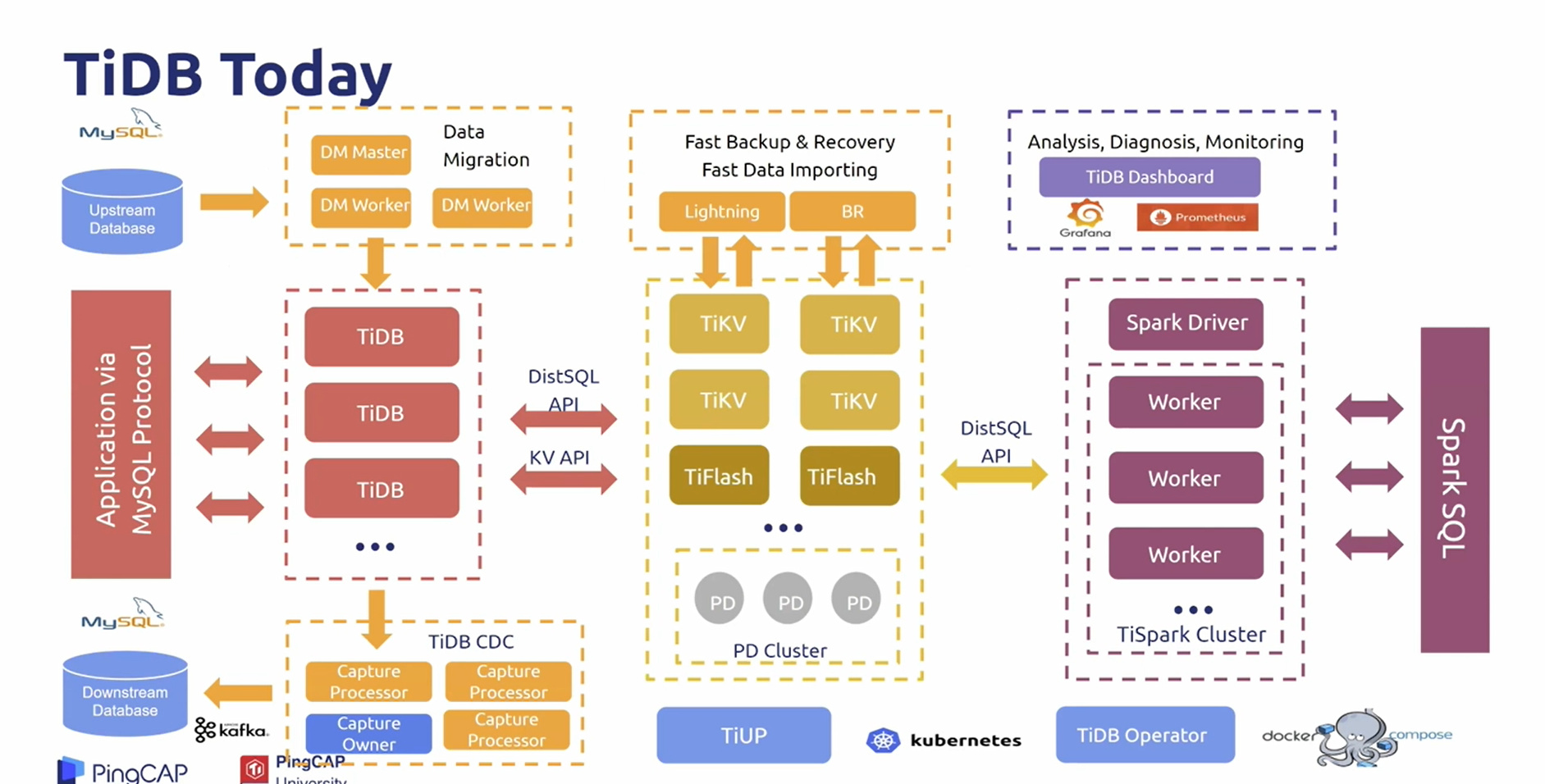
四、 今天的TiDB:
- 可称为HTAP;
- 在系统进行业务时,也可以方便报表查询数据库;
- 既有行存,也有列存,数据可自动进行转换。