TiDB 发展简史
- TiDB 启发于 Google Spanner
- TiDB 1.0.0 GA 版本
- 一个计算资源、存储自由扩展的数据库
- 兼容 MySQL 语法和协议
- 透明的数据分区策略 - range 分区
- 强一致性,支持分布式事务
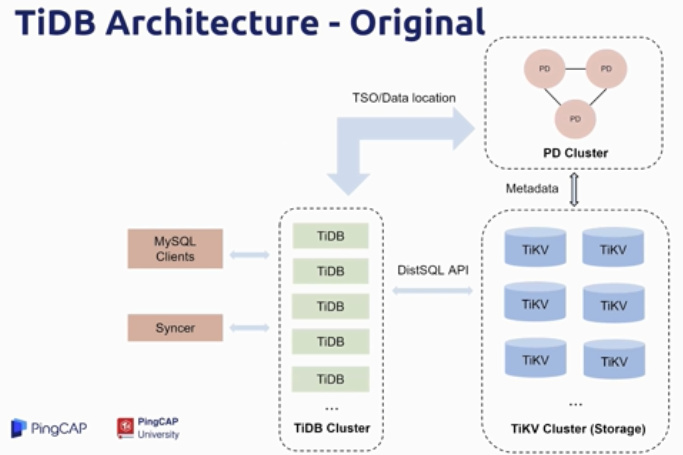
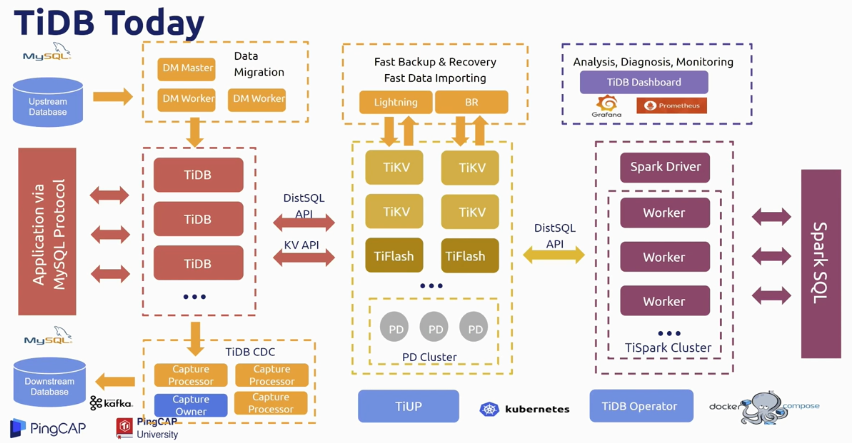
- PD Server 负责存储集群元数据,保证 TSO 全局一致,数据分区定位与调度等
- TiDB Server 负责 SQL 解析
- TiKV Server 做为底层存储,负责数据落盘保存

TiDB 提供数据同步工具 Syncer 可以同步生产数据仓库的数据到 TiDB 集群中。
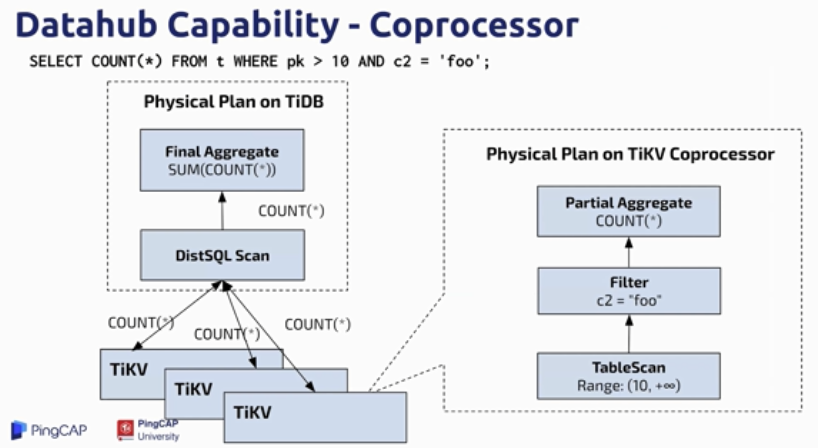
TiDB 通过 Coprocessor 接口与 TiKV 交互,一个查询语句会分发到多个 TiKV 中进行查询、合并,再返回结果。
TiDB 的数据中枢能力
- TiDB 是理想的数据中枢应用场景
- 兼容 MySQL 协议,很容易做数据同步
- 没有数据分片(sharding),跨存储块访问数据对应用来说是透明的
- 实时汇总数据
- 高容量存储运行多数据源进行数据汇总
- 备库与数据中枢分析合二为一
此时的 TiDB 仍然有存在一些不足:
- TP 场景中真香但总有一些问题出现
- AP 场景中
- 复杂查询很慢
- 经常 OOM
- 无法与大数据平台整合
解决的方法有两个选择:
- 跟 TiDB 或 TiKV 合并
- 完全重构优化器和执行器,创建一个 MPP 引擎
- 风险很高,周期很长
- 拥抱开源
- 寻找开源的分布式计算框架
- 成熟度高且有一定用户基础
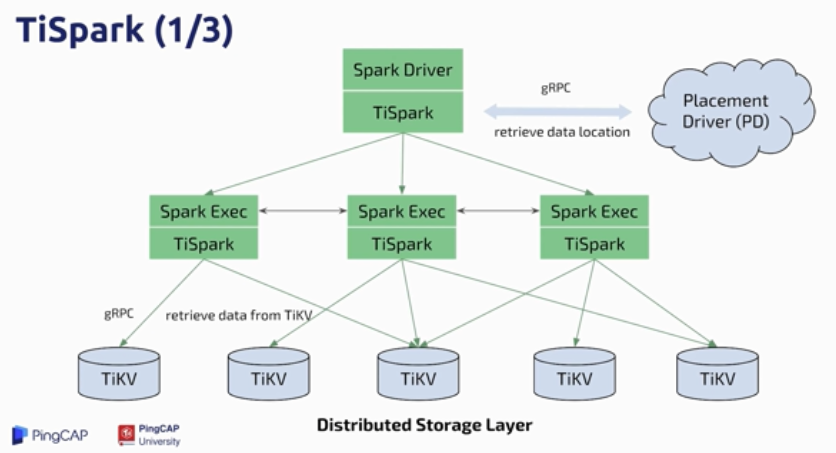
TiSpark 因此诞生
- 提供分布式计算能力
- 一个成熟的分布式计算平台
- 更快也更稳定
- 完全继承了 Apache Spark 的生态圈
- 无痛整合到大数据生态圈中
- 脚本,Python,R,Apache Zeppelin,Hadoop 等
TiSpark 的缺点
- Apache Spark 只能提供低并发计算
- 复杂的计算模型和很高的资源消耗
- 只适用于报表查询或特定的复制查询
- 大多数情况下,用户需要高并发,中小型的 AP 数据库
- 低耗复杂查询
- TiDB 远远比 Spark 集群容易维护
与此同时,TiDB 不断优化:
- 已经为独立的 TiDB 做了很多优化,保证在中小规模场景中可以跑得更快,更智能,更高效
- 优化器也做了一些优化,从最基础的优化器 → RBO + CBO → 级联优化器(WIP)
- 执行器也是一路进行演化
- 经典火山模型 → 批量模型 → 向量化模型
- 更好的并发度和管道机制
- 还有分区表,索引合并等等
直到 TiDB 2.1,仍然存在两个核心矛盾
- 行存储对于数据分析场景相当不友好,没有列存储如何敢自称 HTAP?
- 负载隔离无法实现,TiSpark 应用体验非常差,跑个查询 CPU 飙到 10000% ???
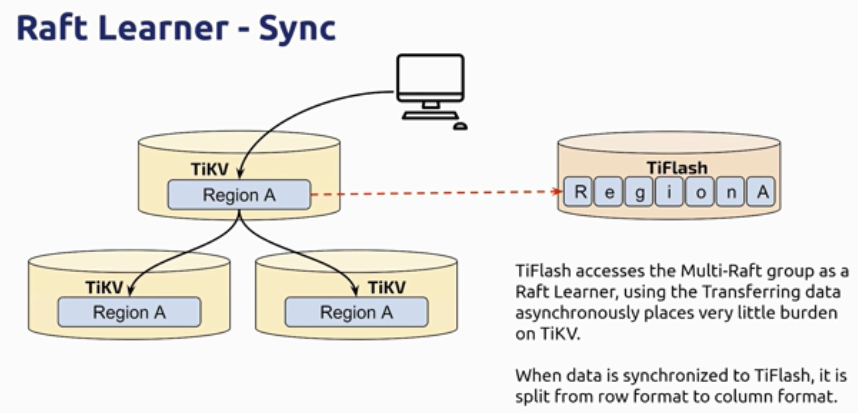
TiFlash 应运而生
- 通过 Raft Learner 同步数据到独立的列式存储中
- 使用极低的资源消耗进行数据同步
- 基于 MVCC 机制对外提供强一致性读
- 通过标签实现物理隔离
- 从此 AP 和 TP 老死不相往来。。。(工作负载互不影响)

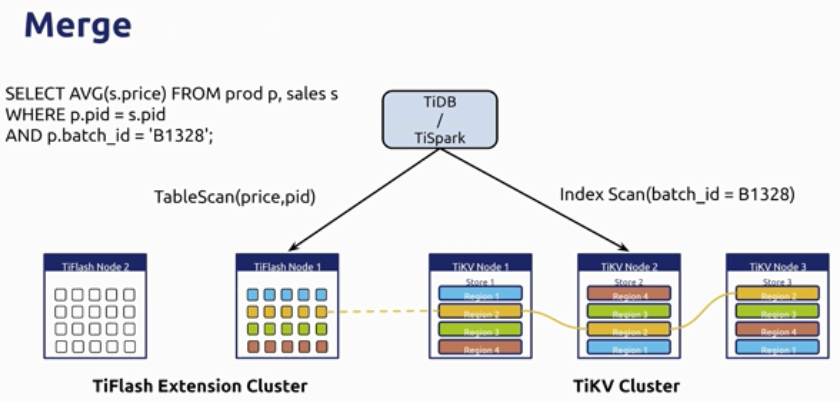
至此,任督二脉打通
- TiDB 就是一个完整的 HTAP数据库
- 一个平台,兼容行存和列存,支持无痛
人流数据同步 - 系统运行 TP 业务的同时更容易做报表查询