课程名称:课程版本(101)+ 1.3 A Brief History About the TiDB database platform(TiDB 发展简史)
学习时长:
15min
课程收获:
主要学习TiDB的发展过程,从最早的形式,到不断发展填充,到如今整体的架构。
课程内容:
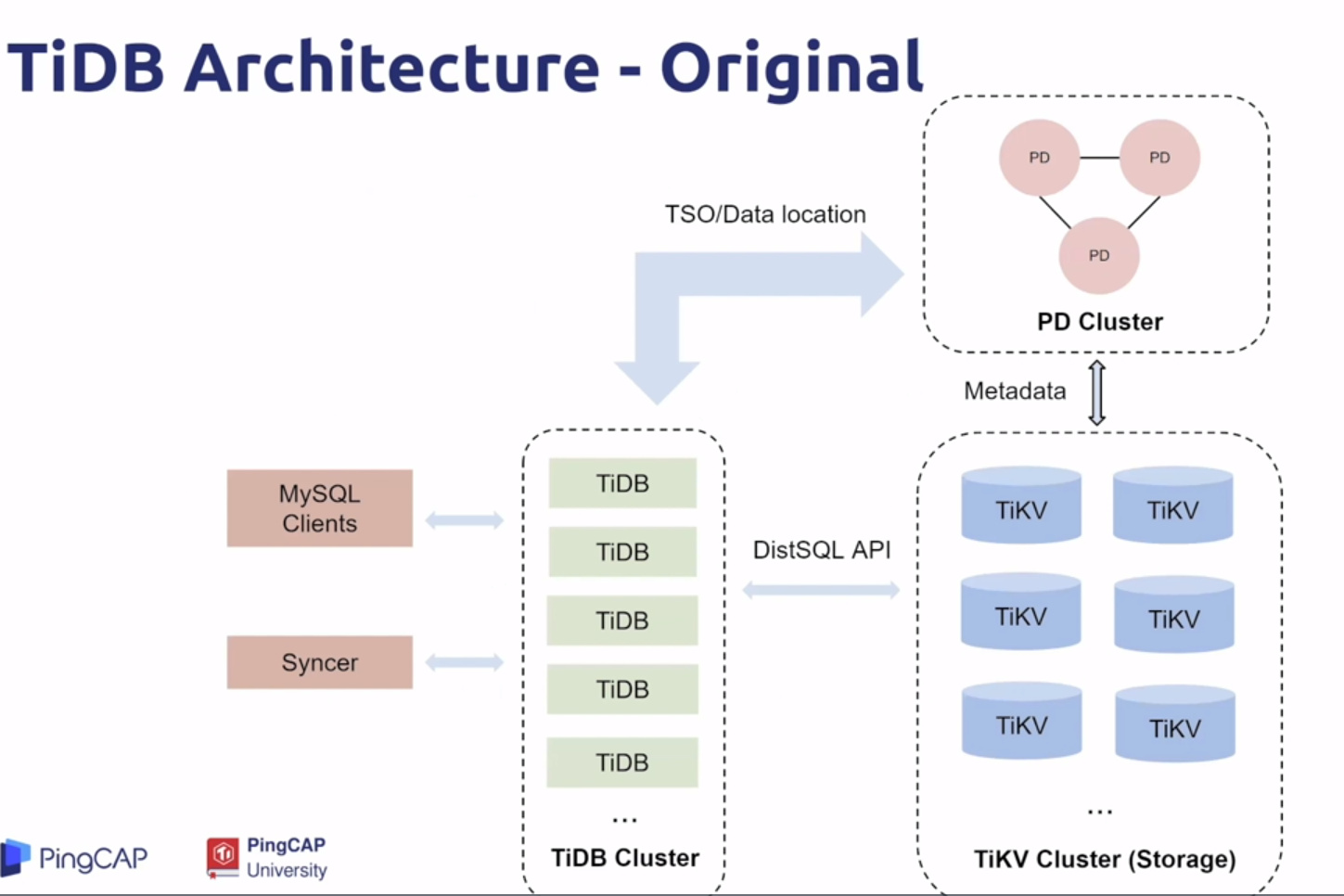
Ancient days of TiDB
- 受Spanner 启发
- 在 1.0.0 GA version
- 一个可扩展数据库
- 兼容MySQL语法和协议
- 透明数据分片 - 范围分片
- 强一致性,分布式事务支持
Datahub Capability
- 适合数据中台应用场景,很好的中台能力
- 由于协处理器的存在,汇总数据可以并行聚合
- 不需要数据分片,对应用数据透明
- 协议兼容MySQL, 很好的同步MySQL库
- 实时数据汇总,备机和中台可以合二为一
One year later
- TP 场景使用还行
- AP 场景使用不容乐观
- 复杂查询过慢
- AP 中容易OOM
- 与大数据平台整合较难
Choice
- 整合TiDB 和 TiKV ,采用MPP 架构, 高风险,长时间
- 采用成熟开源的分布式计算框架 (
 )
)
TiSpark
- 提供分布式计算框架
- 无缝接入大数据框架
- 并发低
- 消耗资源大
Meanwhile
- 优化器
- Basic optimizer → RBO + CBO → Cascades Optimizer(WIP)
- 执行器
- Classic Volcano Model → Batch Execution → Vectorized Execution
- 分区表
Core conflict
- 只有行存,没有列存,对AP不友好
- 没有工作隔离,单个查询对整体有影响
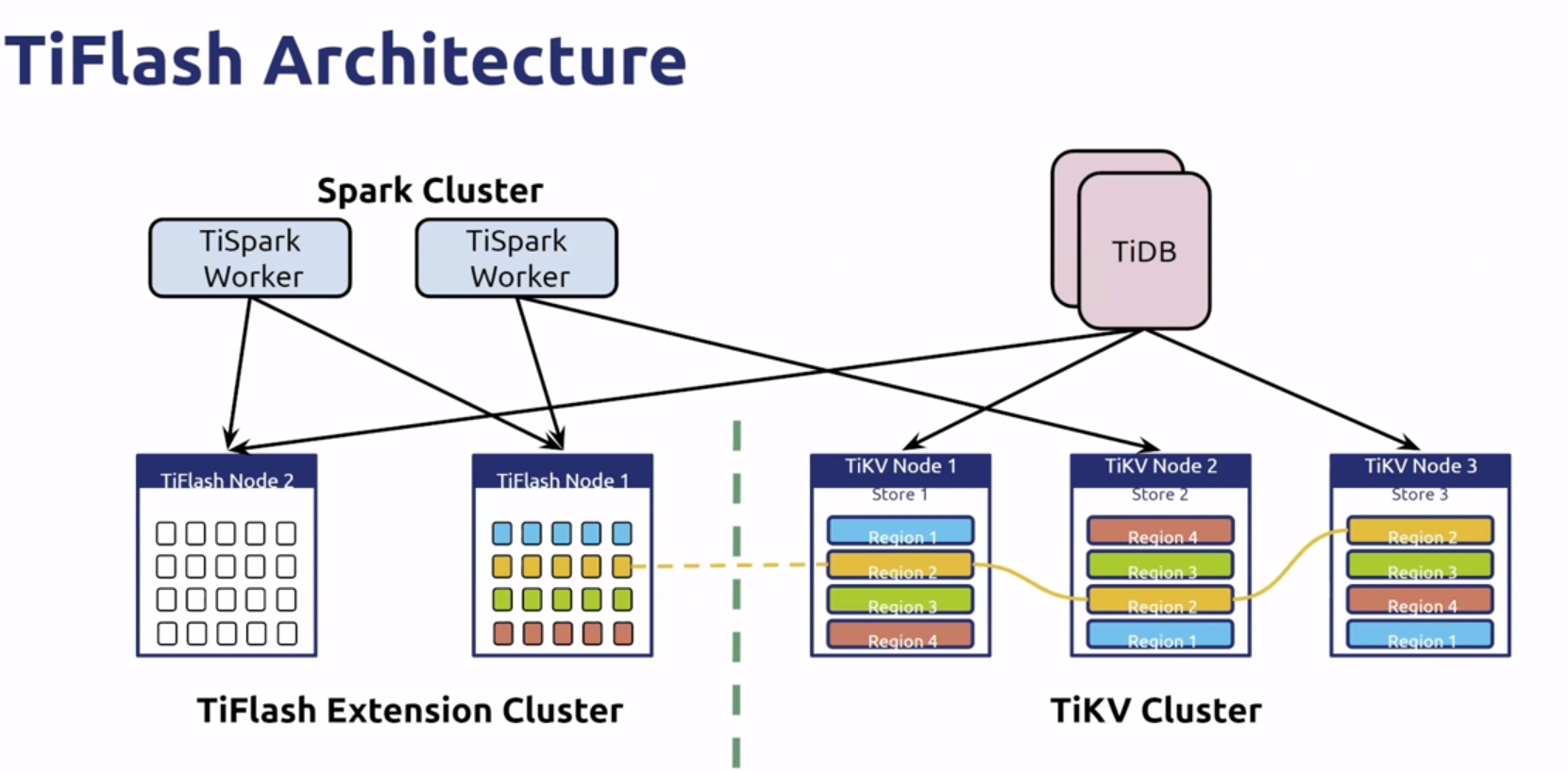
TiFlash
- 列存
- 使用Raft 实现数据同步
- AP TP 物理隔离
- 一个SQL的不同请求发送到不同引擎中
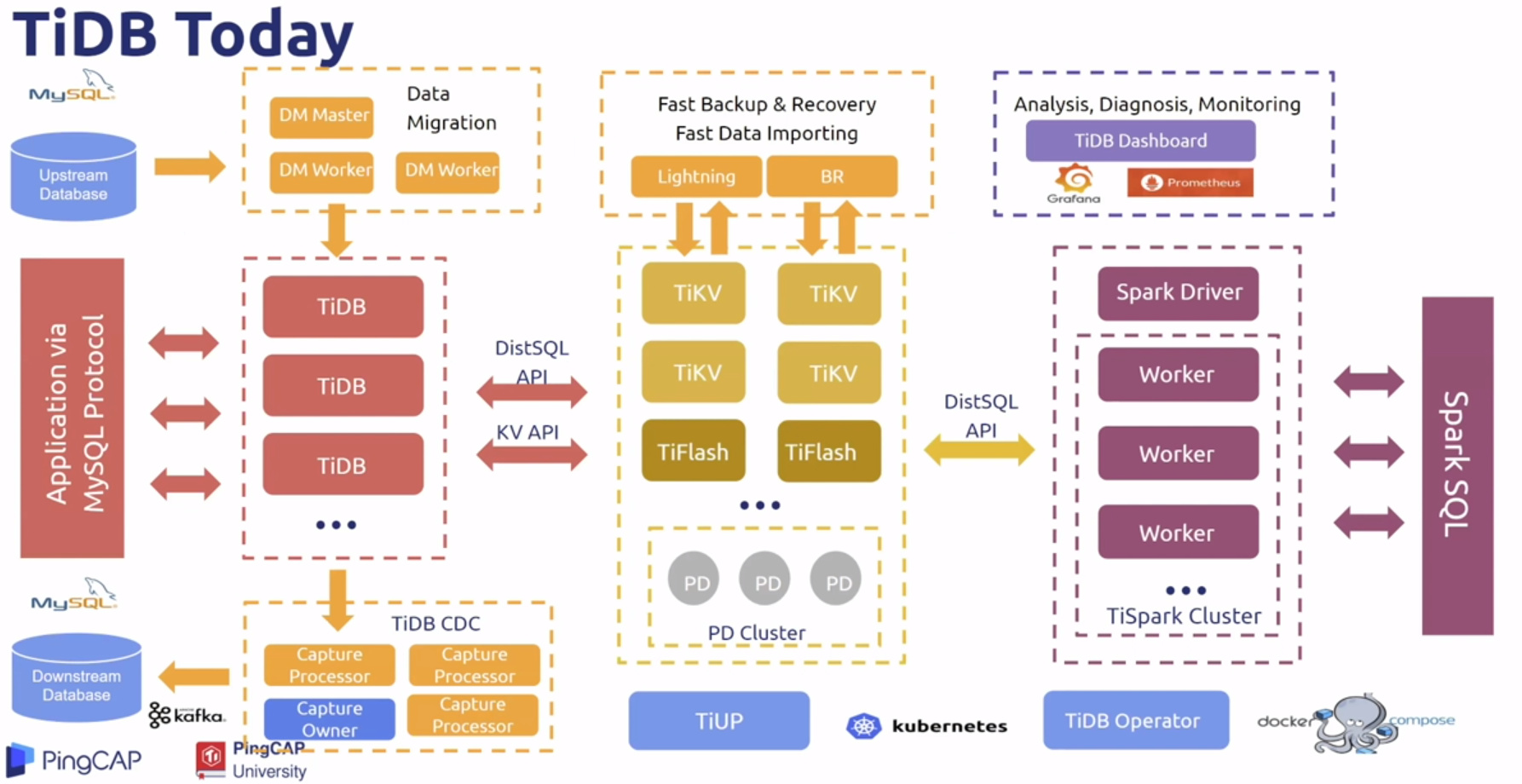
Till now
- HTAP 支持行存 列存
- 自动行列转换
- 对于不同查询请求自动分配处理引擎
- 各种工具,安装部署,数据迁移,数据同步,备份恢复,数据监控等等