为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:v3.0.9
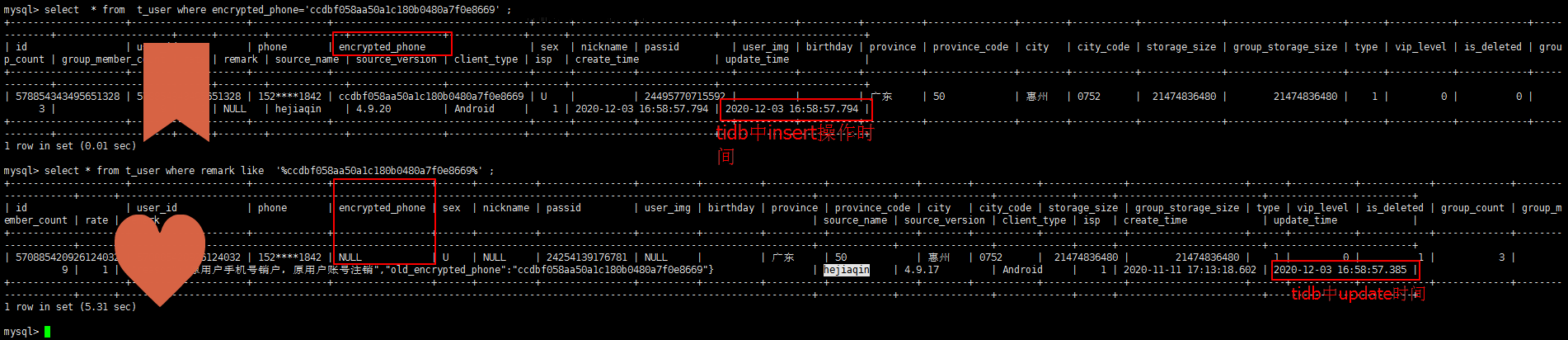
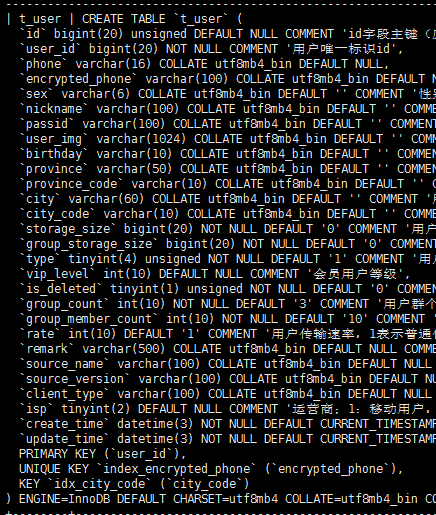
- 【问题描述】:tidb线上环境对t_user表进行update更新一条记录的unique_key的值由A设为null,然后插入一条unique_key值为A的新记录,tidb数据库中update操作的时间比insert操作的时间早0.4秒左右,但是同步到下游mysql时,并没有执行updae语句,而是直接执行insert语句,导致drainer报Duplicate entry错误。
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
来了老弟
2
sorry,
请问同步链路是 tidb(v309)-> tidb binlog(v309) -> mysql(?)
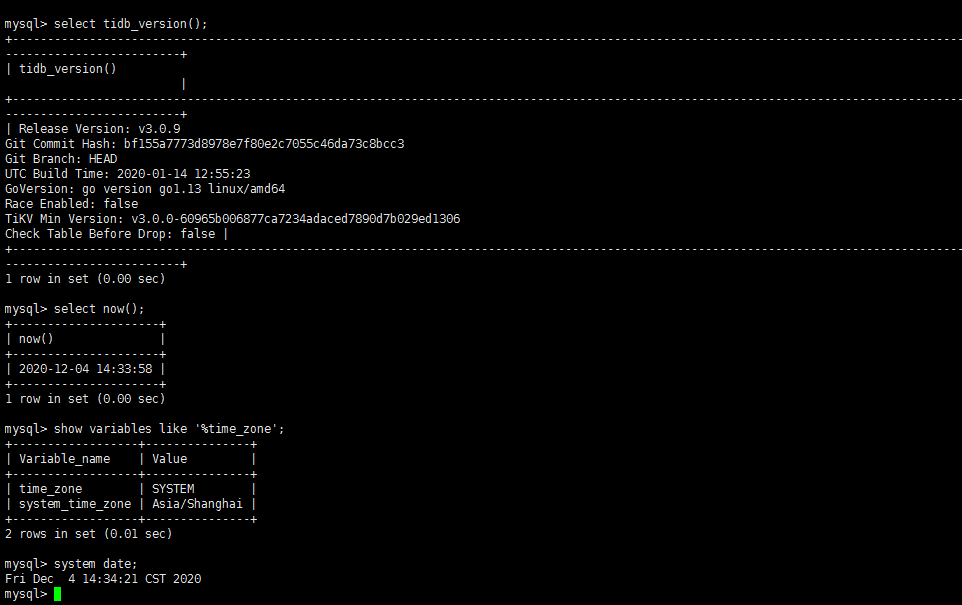
tidb:
select tidb_version(); select now(); show variables like '%time_zone'; system date
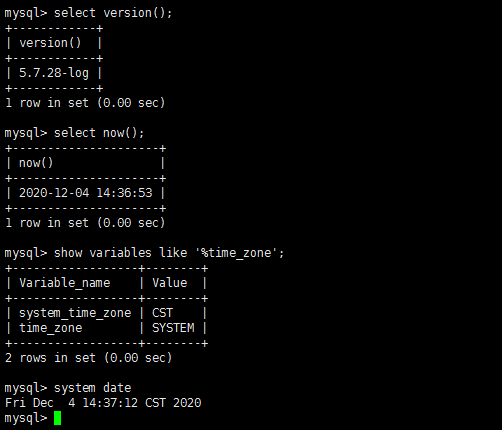
mysql:
select version(); select now(); show variables like '%time_zone'; system date
同步链路是 tidb(v309)-> tidb binlog(v309) → mysql
来了老弟
5
感谢你的反馈,能否提供下完整的 pump 和 drainer log 看下?
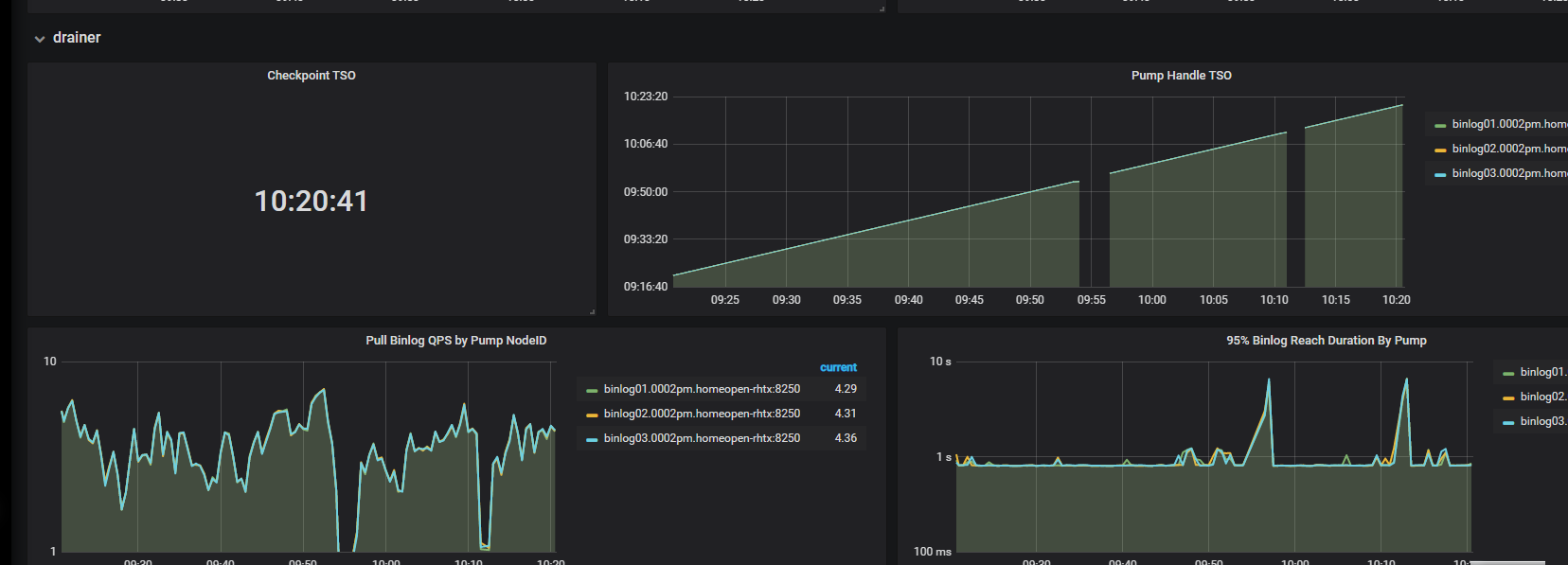
时间区间包括这张图的时间即可
drainer.log.txt (73.5 KB) pump1.log.txt (11.2 KB) pump2.log.txt (11.2 KB) pump3.log.txt (11.3 KB)
该问题在11月30号下午集群底层的存储hang住后出现的,之前一直没有问题
来了老弟
8
非常感谢你的反馈
问题分析:
重复的数据主键不冲突,但是唯一索引冲突。
drainer 在并发到下游的时候,会根据第一个唯一的 key(包括主键) 的 hash 作为分发的条件。由于两条记录的主键不同,所以并发执行的时候,不能保证严格的顺序。
结论是
- 目前的 drainer 并发模式不能很好的支持这类同步。
- 用户可以通过设置 worker-count = 1 避免这段并发来绕过这个问题。
- 升级到 ticdc v4.0.6(ticdc GA 之后的版本)建议最新版本,解决此问题。
我重新做了好几次同步 但是发现下游每天新增的数据要比tidb的少很多,但是binlog除了偶尔报一次主键冲突的错误,其他一切看起来都正常,看看监控也没有延迟
设置 worker-count = 1 后还是遇到该问题
来了老弟
12
@Hacker_1bOJKx43
你好,
请帮忙确认以下信息:
- 用户没有改动过 causality 相关配置。
- 用 admin check table 结果辛苦反馈下。
该问题在11月30号下午集群底层的存储hang住后出现的,因为怀疑是部分update的binlog日志未到达drainer,所以重新部署了pump集群并把worker-count设置为1,然后就修复了这个问题。
但是之前设置worker-count设置为1时,也同时修改了中控机上的drainer_mysql.toml文件和drainer服务器上的drainer.toml文件,感觉修复的主要原因是重新部署了pump.
来了老弟
15
@Hacker_1bOJKx43 hello,请帮忙看下上面的问题
如果有困难,可以提供下完整的 pump log 我们看下
pump_1.zip (5.5 MB) [quote=“东北大胖子, post:14, topic:64052”]
admin check table
[/quote]
pump_2.zip (5.3 MB) pum_3.zip (5.1 MB)
您好,这是故障前后的日志
来了老弟
17
[quote=“Hacker_1bOJKx43, post:16, topic:64052”]
这个没太看懂,就是在业务低峰期执行下 admin check table tble-name; tble-name 为上下游数据量不太一样的表即可(譬如上面截图中 t_user )
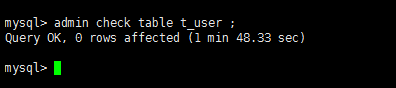
admin check table t_user的结果为空