Cluster version: v4.0.8
已有三个TIKV节点,扩容两个节点,然后下线这两个节点,一直处于 Pending Offline 中,等了一夜没有变化。
第二天一早 执行了强制下线的命令 tiup cluster scale-in prod-cluster --node 192.168.4.18:20160 --force
强制下线后,执行 扩容命令
但是系统提示失败:
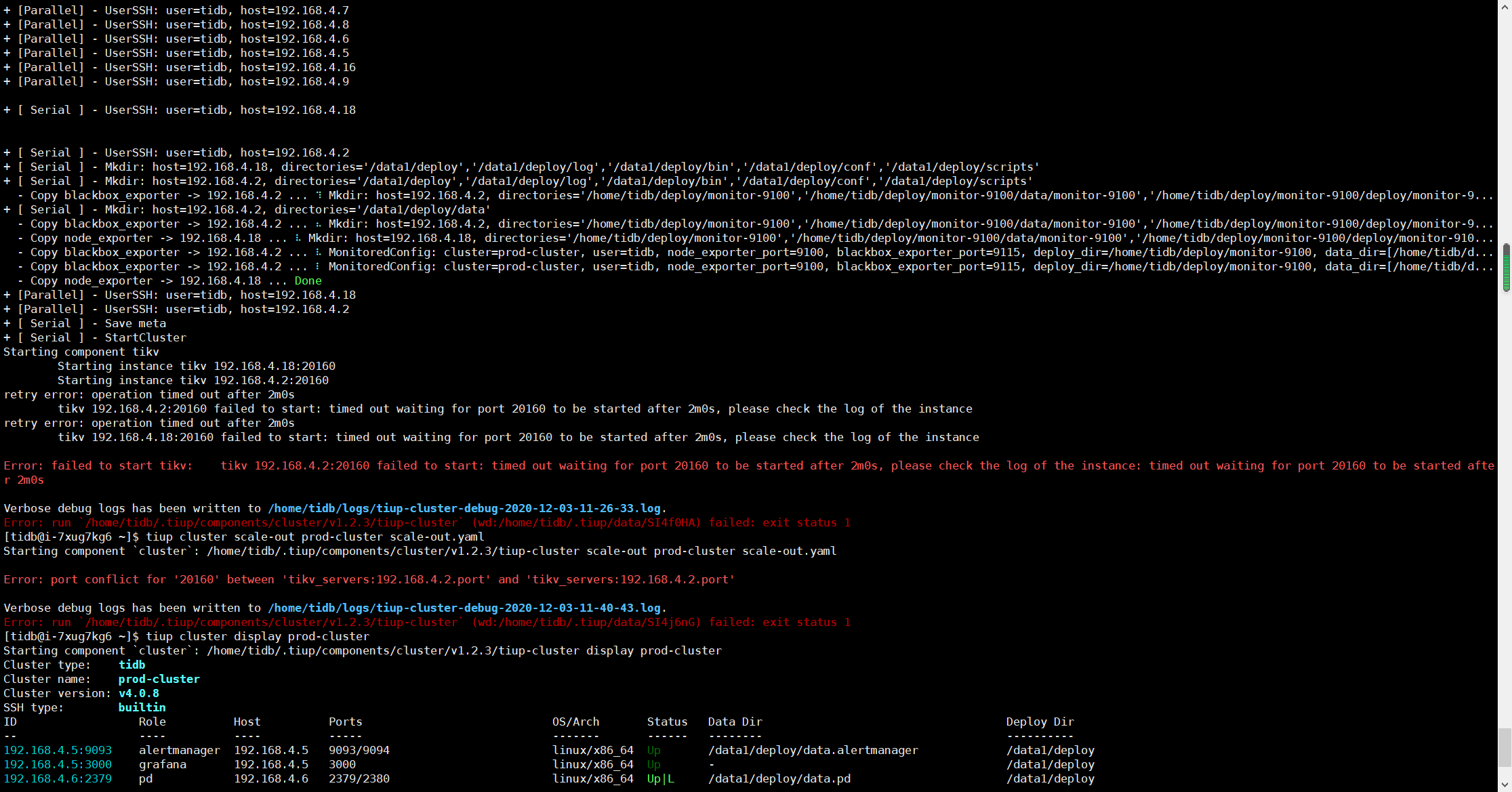
- [ Serial ] - UserSSH: user=tidb, host=192.168.4.2
- [ Serial ] - Mkdir: host=192.168.4.18, directories=’/data1/deploy’,’/data1/deploy/log’,’/data1/deploy/bin’,’/data1/deploy/conf’,’/data1/deploy/scripts’
- [ Serial ] - Mkdir: host=192.168.4.2, directories=’/data1/deploy’,’/data1/deploy/log’,’/data1/deploy/bin’,’/data1/deploy/conf’,’/data1/deploy/scripts’
- Copy blackbox_exporter -> 192.168.4.2 … ⠹ Mkdir: host=192.168.4.2, directories=’/home/tidb/deploy/monitor-9100’,’/home/tidb/deploy/monitor-9100/data/monitor-9100’,’/home/tidb/deploy/monitor-9100/deploy/monitor-9…
- [ Serial ] - Mkdir: host=192.168.4.2, directories=’/data1/deploy/data’
- Copy blackbox_exporter -> 192.168.4.2 … ⠦ Mkdir: host=192.168.4.2, directories=’/home/tidb/deploy/monitor-9100’,’/home/tidb/deploy/monitor-9100/data/monitor-9100’,’/home/tidb/deploy/monitor-9100/deploy/monitor-9…
- Copy node_exporter -> 192.168.4.18 … ⠧ Mkdir: host=192.168.4.18, directories=’/home/tidb/deploy/monitor-9100’,’/home/tidb/deploy/monitor-9100/data/monitor-9100’,’/home/tidb/deploy/monitor-9100/deploy/monitor-910…
- Copy blackbox_exporter -> 192.168.4.2 … ⠧ MonitoredConfig: cluster=prod-cluster, user=tidb, node_exporter_port=9100, blackbox_exporter_port=9115, deploy_dir=/home/tidb/deploy/monitor-9100, data_dir=[/home/tidb/d…
- Copy blackbox_exporter -> 192.168.4.2 … ⠇ MonitoredConfig: cluster=prod-cluster, user=tidb, node_exporter_port=9100, blackbox_exporter_port=9115, deploy_dir=/home/tidb/deploy/monitor-9100, data_dir=[/home/tidb/d…
- Copy node_exporter -> 192.168.4.18 … Done
- [Parallel] - UserSSH: user=tidb, host=192.168.4.18
- [Parallel] - UserSSH: user=tidb, host=192.168.4.2
- [ Serial ] - Save meta
- [ Serial ] - StartCluster
Starting component tikv
Starting instance tikv 192.168.4.18:20160
Starting instance tikv 192.168.4.2:20160
retry error: operation timed out after 2m0s
tikv 192.168.4.2:20160 failed to start: timed out waiting for port 20160 to be started after 2m0s, please check the log of the instance
retry error: operation timed out after 2m0s
tikv 192.168.4.18:20160 failed to start: timed out waiting for port 20160 to be started after 2m0s, please check the log of the instance
Error: failed to start tikv: tikv 192.168.4.2:20160 failed to start: timed out waiting for port 20160 to be started after 2m0s, please check the log of the instance: timed out waiting for port 20160 to be started after 2m0s
Verbose debug logs has been written to /home/tidb/logs/tiup-cluster-debug-2020-12-03-11-26-33.log.
Error: run /home/tidb/.tiup/components/cluster/v1.2.3/tiup-cluster (wd:/home/tidb/.tiup/data/SI4f0HA) failed: exit status 1
重启两台新TIKV节点
再次在主控机器执行扩容命令提示
[tidb@i-7xug7kg6 ~]$ tiup cluster scale-out prod-cluster scale-out.yaml
Starting component cluster: /home/tidb/.tiup/components/cluster/v1.2.3/tiup-cluster scale-out prod-cluster scale-out.yaml
Error: port conflict for ‘20160’ between ‘tikv_servers:192.168.4.2.port’ and ‘tikv_servers:192.168.4.2.port’
Verbose debug logs has been written to /home/tidb/logs/tiup-cluster-debug-2020-12-03-11-40-43.log.
Error: run /home/tidb/.tiup/components/cluster/v1.2.3/tiup-cluster (wd:/home/tidb/.tiup/data/SI4j6nG) failed: exit status 1