Culbr
2020 年11 月 29 日 06:20
1
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
我们目前正在利用DM从线上RDS MySQL库同步到TiDB,接收同步请求的那个TiDB节点每隔几分钟就会出现关于tidb_tikvclient_backoff_seconds_count的报警,具体信息如下:
1 alert for alertname=tidb_tikvclient_backoff_seconds_count env=ENV_LABELS_ENV instance=10.0.44.247:10080 job=tidb type=regionMiss
[1] Firing
Labels
alertname = tidb_tikvclient_backoff_seconds_count
cluster = sht-tidb-cluster-pro
env = ENV_LABELS_ENV
expr = increase( tidb_tikvclient_backoff_seconds_count[10m] ) > 10
instance = 10.0.44.247:10080
job = tidb
level = warning
monitor = prometheus
type = regionMiss【报警中还有另外一种type,名为staleCommand】
Annotations
description = cluster: ENV_LABELS_ENV, instance: 10.0.44.247:10080, values:138.46153846153845
summary = TiDB tikvclient_backoff_count error
value = 138.46153846153845
根据官方文档的描述,其含义是:
TiDB 访问 TiKV 发生错误时发起重试的次数。如果在 10 分钟之内重试次数多于 10 次,则报警。
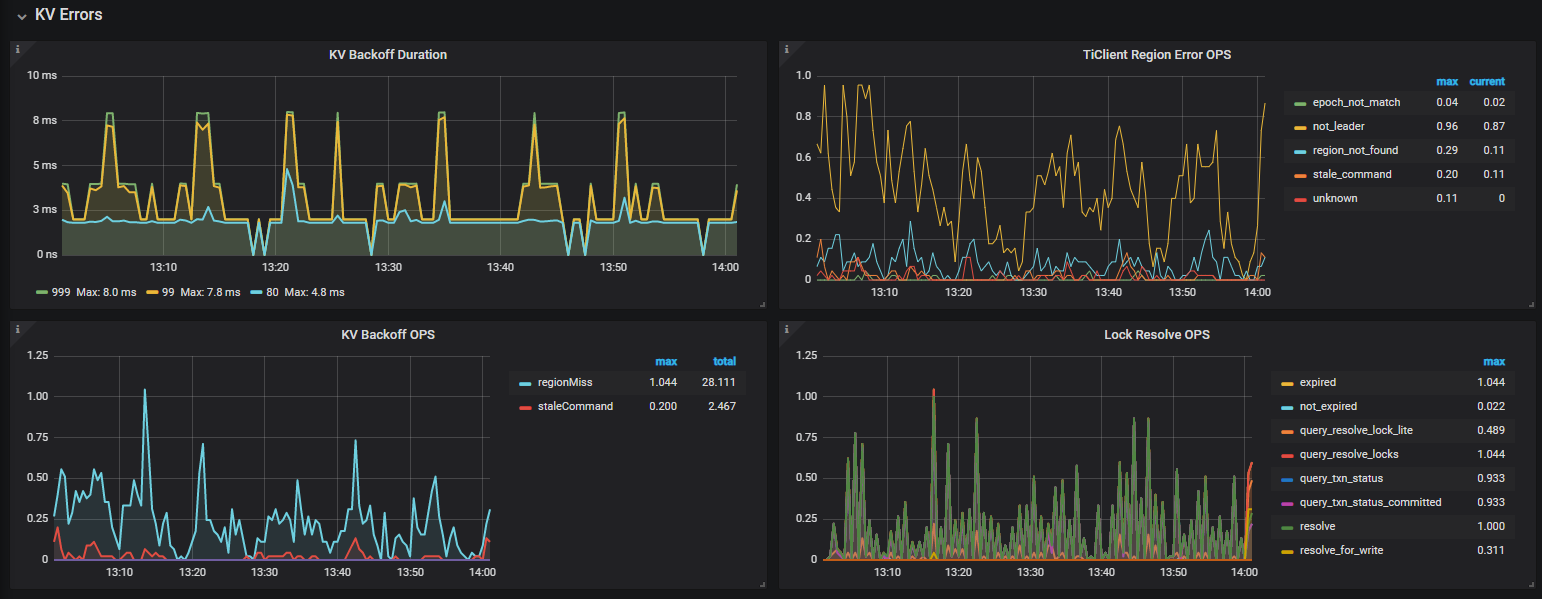
查看Grafana中相关的监控面板:
其他信息:
DM同步任务的safe-mode固定开启,QPS大概在3K~6K左右。
同步任务执行的SQL延迟都正常(1ms以下)。
此TiDB节点专门负责同步,不接收普通客户端的读写请求。
通过查找其他帖子,发现报警原因是**“region或leader调度引起的重试”**次数达到了阈值(目前集群中大概有1W多个region)。
Many thanks~
spc_monkey
2020 年11 月 30 日 02:25
2
1、可以调大相关阈值,不过看上面的监控,发现数量很低啊
1 个赞
Culbr
2020 年11 月 30 日 03:42
3
感谢回复~
不过监控中backoff的单位是OPS,如果含义是每秒backoff频率的话,总数确实有可能会很大(我们观察到的10分钟regionMiss总数最高到过250),并且这个报警一天24小时都存在,没有间断过。我们现在的写入QPS并不高,担心过一段时间上量之后问题会更严重,可否帮忙提供一些诊断这个问题的思路呢?麻烦了~
yilong
2020 年11 月 30 日 10:00
4
Culbr
2020 年12 月 2 日 03:50
5
hi,我之前已经参考过了该帖子,通过观察TiDB和TiKV的日志,没有发现原帖主所反映的write conflict现象(但仍然存在我之前反馈过的switch region leader to specific leader due to kv return NotLeader问题),也没有发现有助于解决的任何思路。
如前所述,我们出现问题的那个TiDB节点只承担DM节点的同步任务,并且已经关掉了safe-mode, 目前写入QPS在1K~3K上下浮动,但是该报警仍然24H存在。或者再明确一下我们的疑问:
tidb_tikvclient_backoff_seconds_count的报警阈值默认设为10分钟10次,官方是基于什么考量得出的?在单个TiDB节点承载频繁写入的情况下报警远超过默认阈值,是否是可预见的行为?
为什么频繁写入的同时会触发region的频繁调度?
在参考帖子中也提到“可以检查下当前的调度参数设置是否合理”,但我们未对PD参数做过修改,全部默认,是否意味着默认PD参数在高写入的情况下不合理?如果直接调低参数来减少调度行为(如region-schedule-limit从默认的2048修改为参考帖子中的4),是否会有其他隐患?
十分感谢~
spc_monkey
2020 年12 月 7 日 07:12
6
1、建议修改该阈值避免频繁告警,目前该阈值有点低(官网给的阈值建议根据自己实际情况调整),另外可以搜一下 backoff 相关监控指标,官网给出的阈值,不会这么低
Culbr
2020 年12 月 8 日 02:36
7
好的谢谢,目前修改成了100。另外去官网TiDB集群报警规则 一节确定过,默认值就是这么低的~
system
2022 年10 月 31 日 19:03
9
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。