为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:v4.0.9
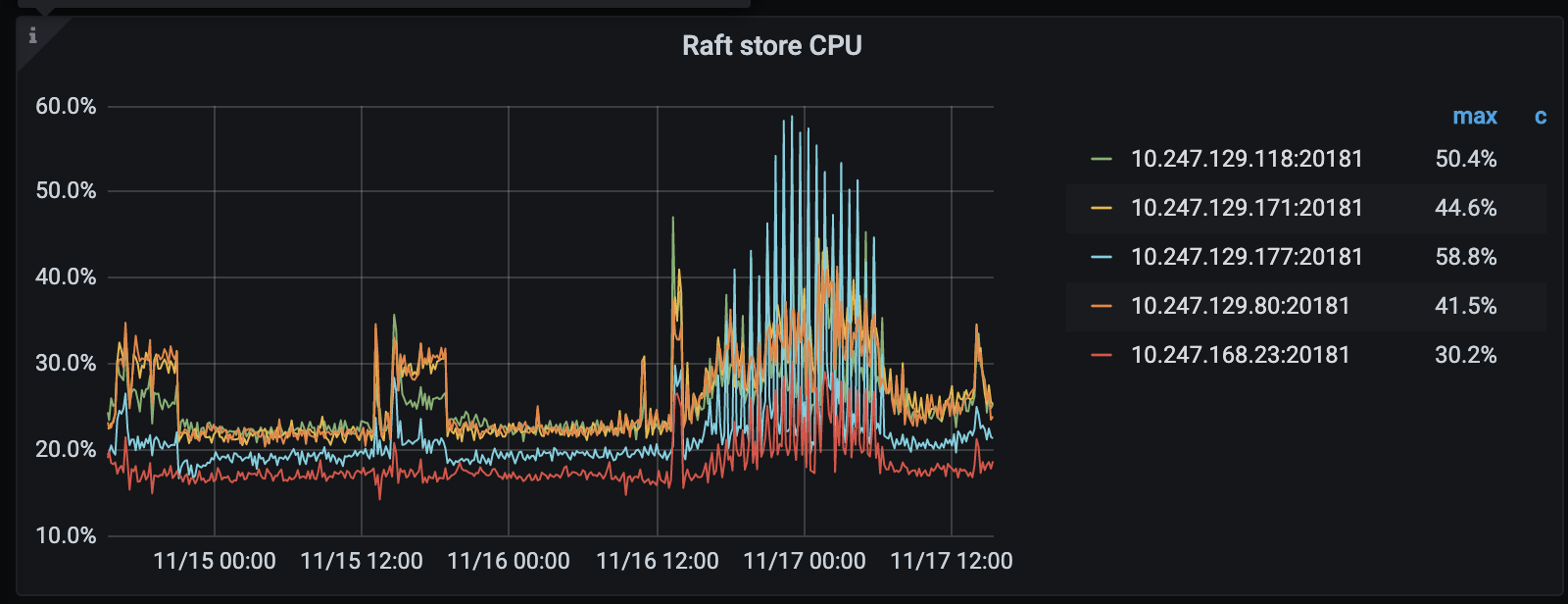
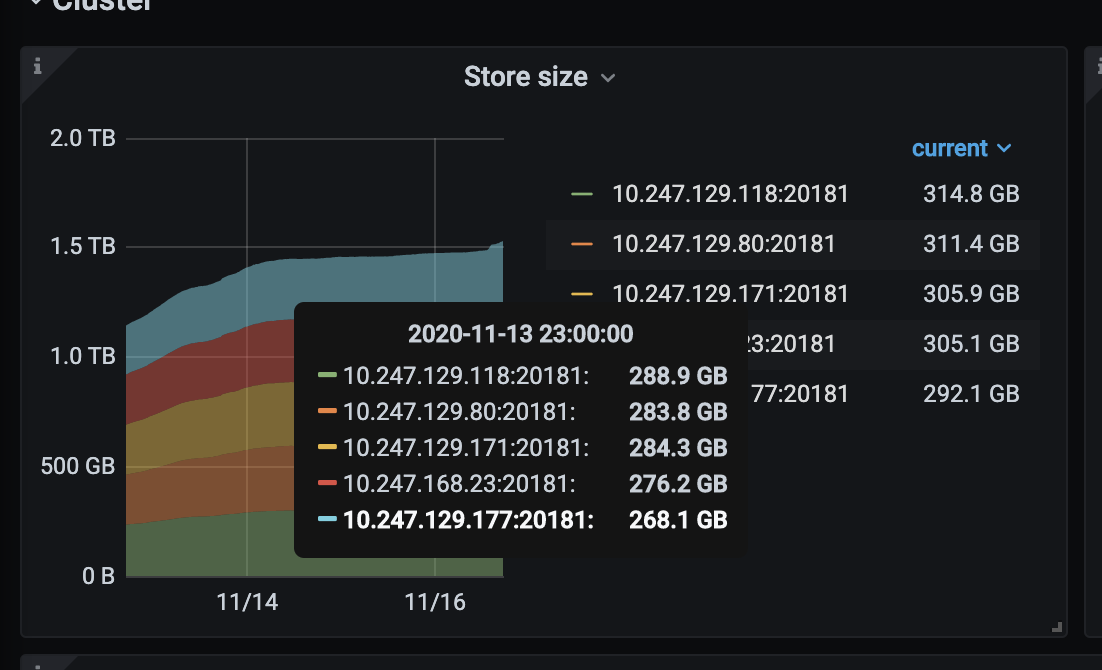
- 【问题描述】:集群内某几台tikv io过高,严重时导致后续数据无法写入 同时,周末集群数据增长量与实际插入量不符,数据高于实际插入量 有没有推荐的排查方法
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出打印结果,请务必全选并复制粘贴上传。
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出打印结果,请务必全选并复制粘贴上传。
1.集群版本写错了吧?v4.0.9 还没有发布;
2.请问下集群使用的磁盘类型是什么,并麻烦核实下是否存在写入热点问题,可参考下面的方法:
https://docs.pingcap.com/zh/tidb/stable/troubleshoot-hot-spot-issues#tidb-热点问题处理
3.数据增长量和实际插入量不符,请问下这个具体是如何判断的?
感谢回复
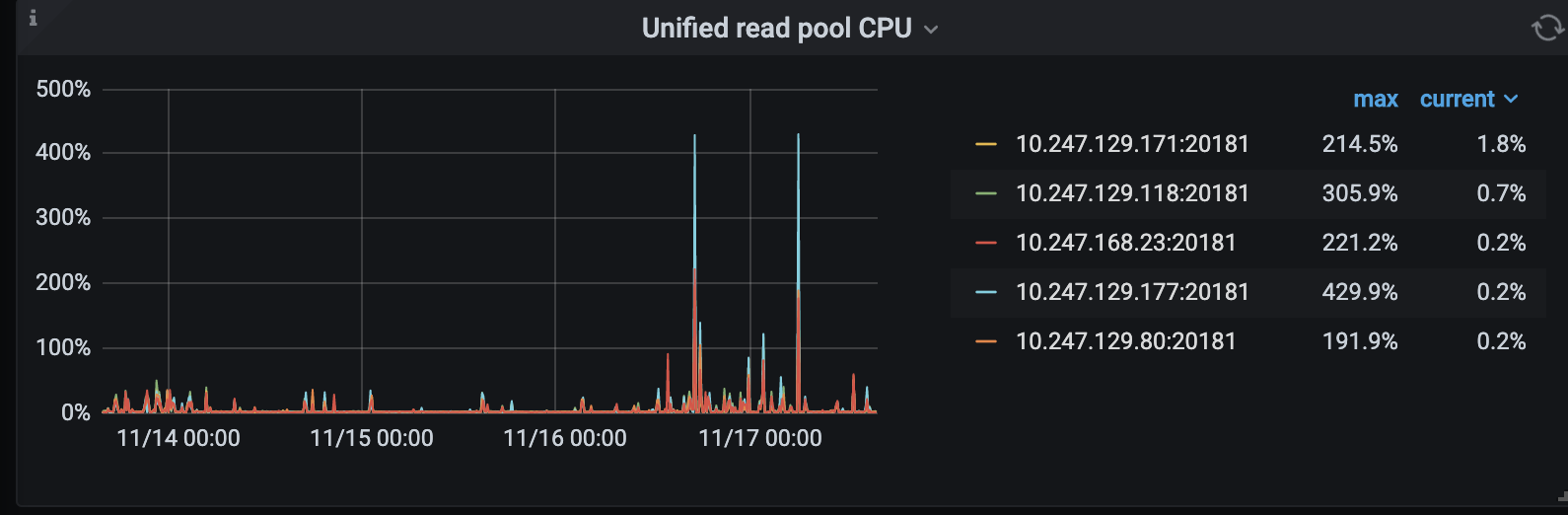
麻烦看下监控面板 TiKV-Details -> Thread CPU 中 Unified read pool CPU 使用情况。
1.提供的监控信息不完整,大部分页面没有数据,麻烦重新上传下 overview、tikv-detail 和 tikv-throuble-shooting 面板的数据,时间选择 IO 明显冲高的时间段;
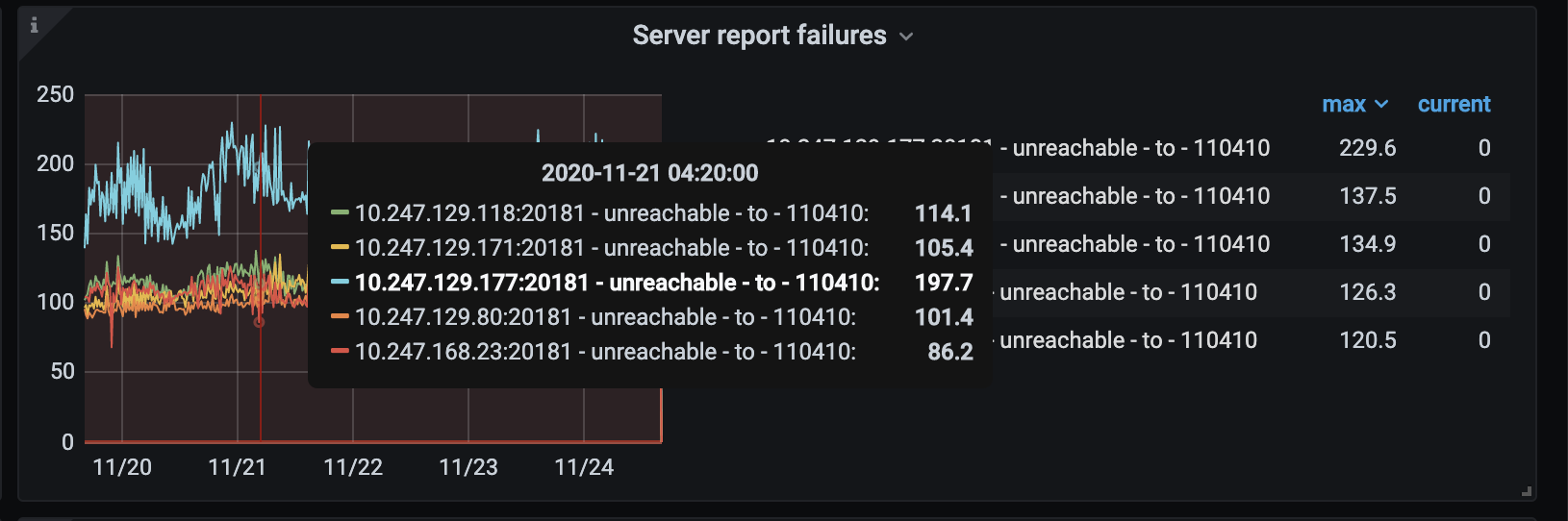
2.在监控面板 server report failures 里每个 tikv 都有大量的 “tikv unreachable to” 报错信息,麻烦检查下 tikv 节点或网络是否正常,并且也发现 23 这台网段和其他的 tikv 均不在一个网段内;
3.请问下各个 tikv 节点的机器配置都是一样的吗?
tikv-detail: tidb-deploy-sj1-TiKV-Details_2020-11-19T09_16_02.692Z.json.tar.gz (1.6 MB)
overview: tidb-deploy-sj1-Overview_2020-11-19T09_20_46.668Z.json (2.5 MB)
tikv-throuble-shooting: tidb-deploy-sj1-TiKV-Trouble-Shooting_2020-11-19T09_24_05.060Z.json.tar.gz (1.5 MB)
23这台机器是后来添加的,确实不在同一网段;确认过和其他节点间不存在丢包的情况,机器间传输文件有170M/s的速度
各机器间配置完全一样
多谢
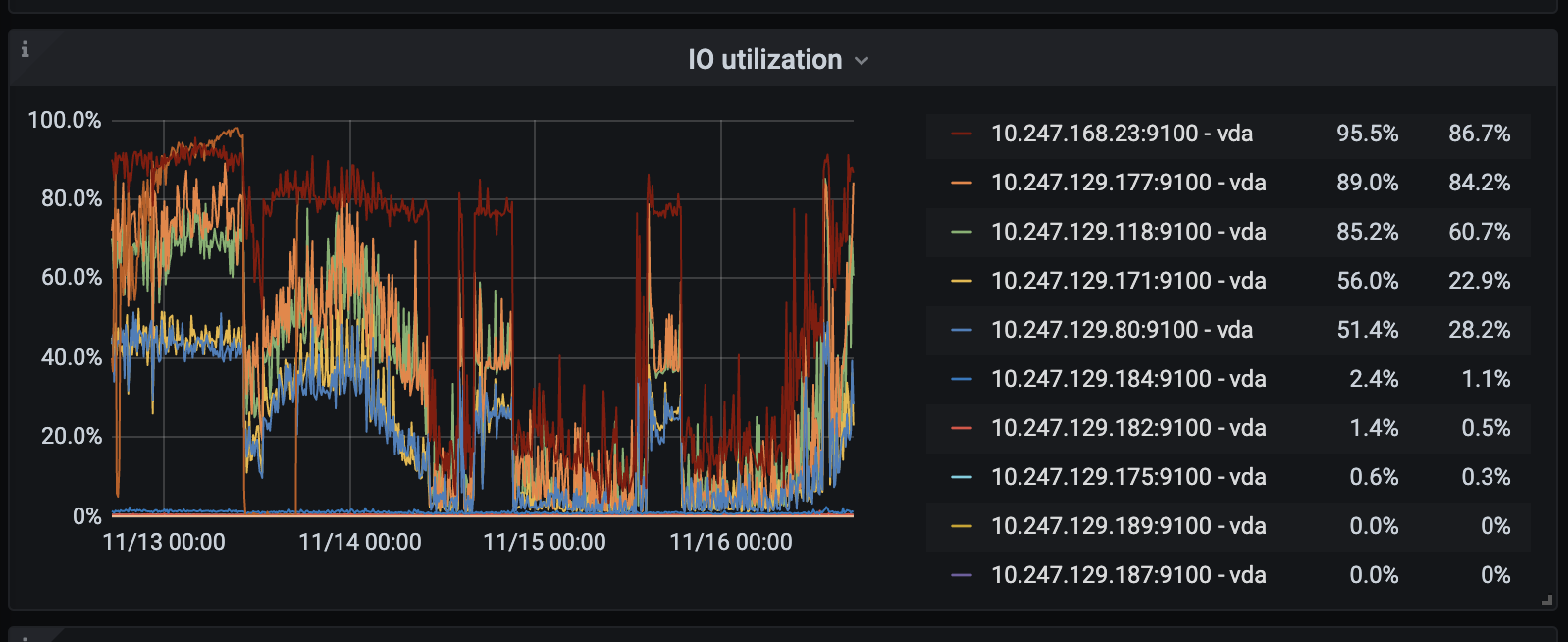
麻烦再反馈下 23 节点的 disk-performance 的监控数据,我们这边再分析下。
tidb-deploy-sj1-Disk-Performance_2020-11-23T05_16_35.414Z.json (106.1 KB) 过去三天23节点 disk-performance信息,感谢帮助
![]()
![]()
![]()