为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:TiDB4.0.8
- 【问题描述】:
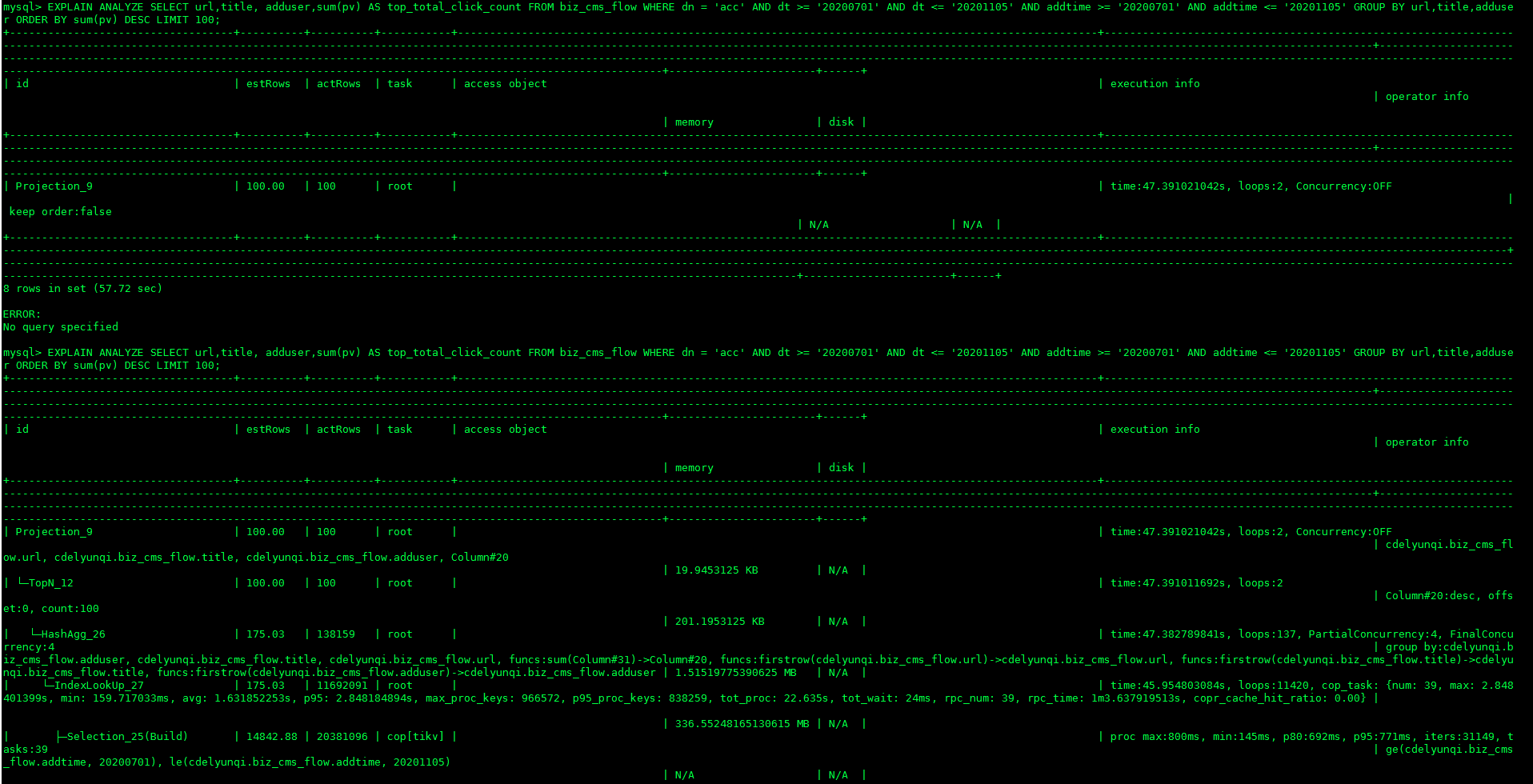
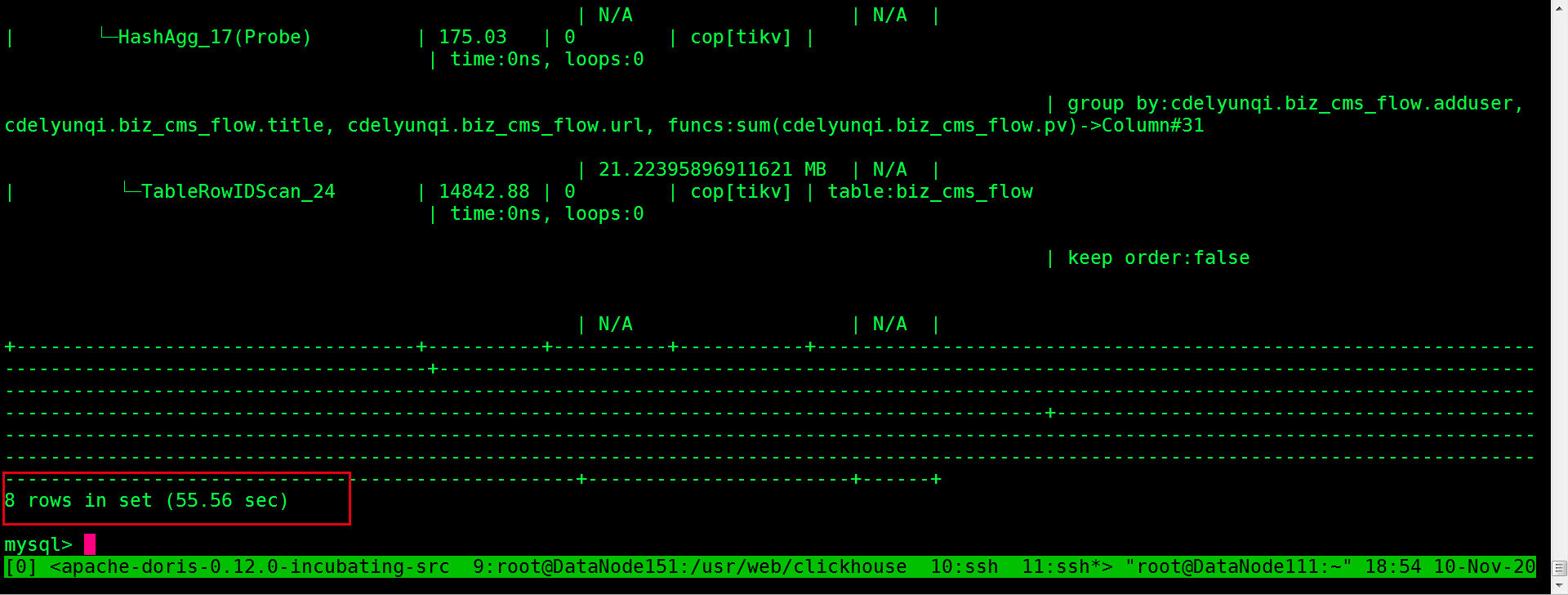
单表查询,做了部分聚合,时间跨度3个月,数据在3000W,KV 取数据在几百毫秒,主要耗时在TiDB上。
这样怎么优化?
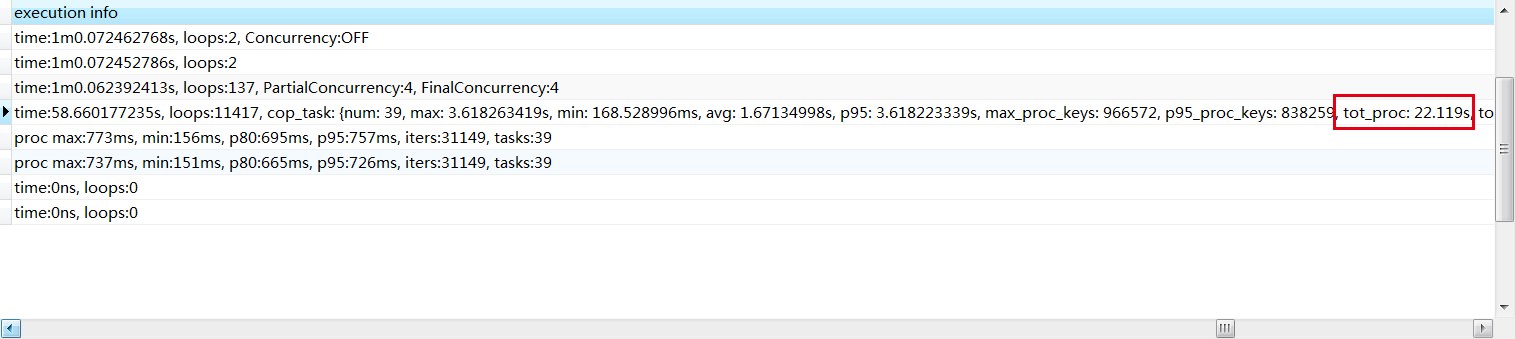
这个时间有点长,tot_proc时间代表什么意思?
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出打印结果,请务必全选并复制粘贴上传。
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出打印结果,请务必全选并复制粘贴上传。
麻烦把完整的 explain analayze sql 都发出来,多谢。
EXPLAIN ANALYZE SELECT
url,
title,
adduser,
sum(pv) AS top_total_click_count
FROM
biz_cms_flow
WHERE
dn = ‘acc’
AND dt >= ‘20200701’
AND dt <= ‘20201105’
AND addtime >= ‘20200701’
AND addtime <= ‘20201105’
GROUP BY
url,
title,
adduser
ORDER BY
sum(pv) DESC
LIMIT
100;
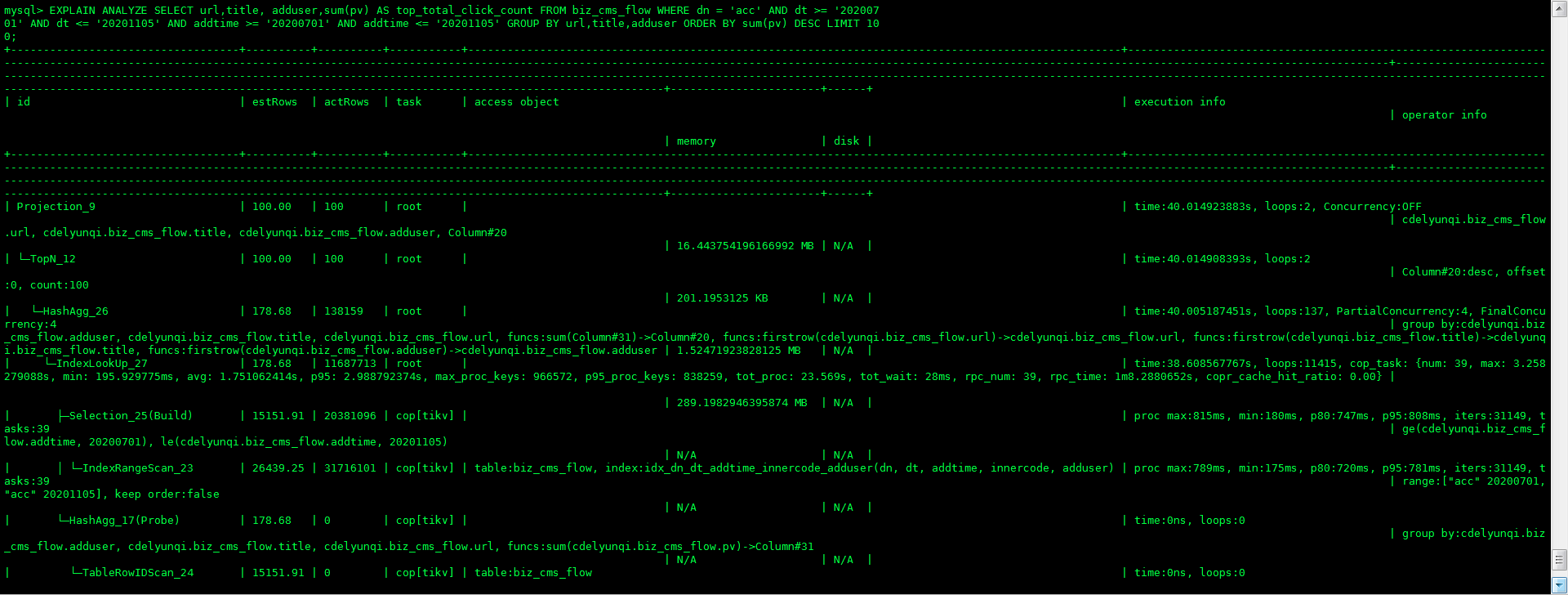
在发帖之前,我已经把这个数据扩大了一倍(默认是4,我现在设置成了8),还是这样的效果!
@zyw8136 调到下面2个参数再试试?
set @@tidb_index_lookup_concurrency=16;
set @@tidb_distsql_scan_concurrency=40;
如果需要经常跑这个聚合查询,而且查询的条件基本不变的话,可以考虑开启 cop cache 配置, https://docs.pingcap.com/zh/tidb/stable/tidb-configuration-file#tikv-clientcopr-cache-从-v400-版本开始引入
可以重新贴下参数调整后,explain analyze 的结果吗?
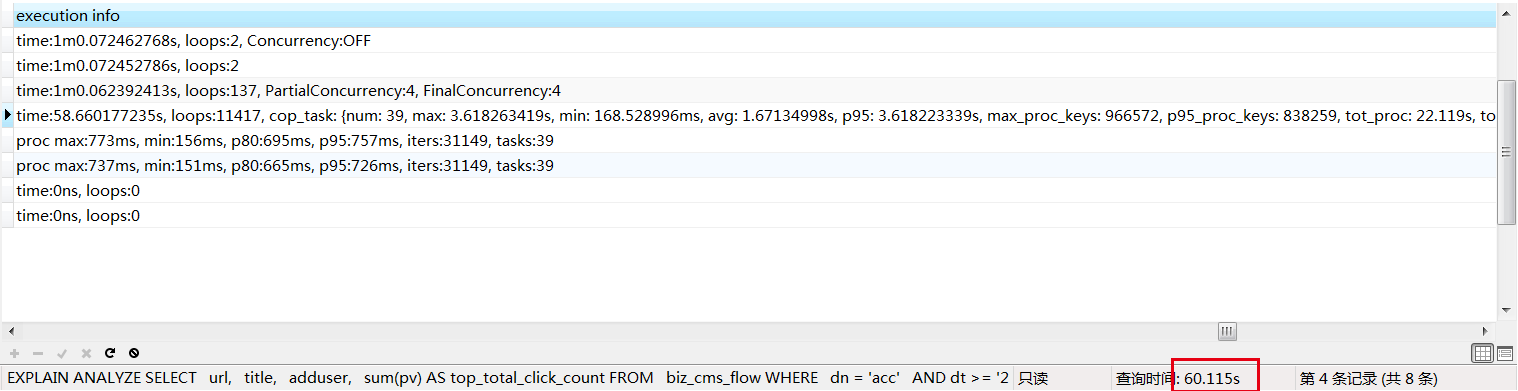
tot_proc 是所有在 TiKV 侧的 cop process time 总时间。
现在主要耗时在 indexlookup 算子, 先读索引,然后还要回表。
set @@tidb_distsql_scan_concurrency=40; 后,再继续调大 tidb_index_lookup_concurrency 看看有没有效果,比如调到 100?
到了100后,tot_proc 还是那么长时间(20多秒)。还是没有效果。
analyze表的话,还是一样的效果,这个表大概7000多万的数据。不是特别大。
@zyw8136 可以加 hint, 不走索引,强制走全表扫吗?感觉总共 7000W 数据 , 读 3000W 数据可能走全表扫可能更好。
EXPLAIN SELECT
url,
title,
adduser,
sum(pv) AS top_total_click_count
FROM
biz_cms_flow ignore index (xxxx)
....