漫谈TiDB数据库部署
--2020-11-08 刘春雷
1、前言
使用TiDB数据库2年多了,部署架构上踩过很多坑,也有过很多优化,此篇文章大致梳理下,希望对大家有所帮助~
2、阶段目标
如果说部署及架构私有云(K8S)为最终目标,那么58这边算是走到了第二阶段
【第一阶段:探索阶段】:
- 调研TiDB、探索业务场景、尝试部署架构、解决问题、优化部署
【第二阶段:稳定阶段】:
- 有一定使用经验,提升了稳定性,自动化、平台化的总体完善,沉淀了较好的部署架构,优化业务,快速、稳定发展
【第三阶段:私有云阶段】:
- 探索更好、更轻、更节约人力的运维方式,跟上业界步伐,让DBA有精力去深入优化业务,更多的赋能业务~
3、第一阶段:探索阶段
这一阶段,属于探索阶段,几乎没有很好的业界实践经验,只能自己尝试。
【版本】: 2.x,3.x
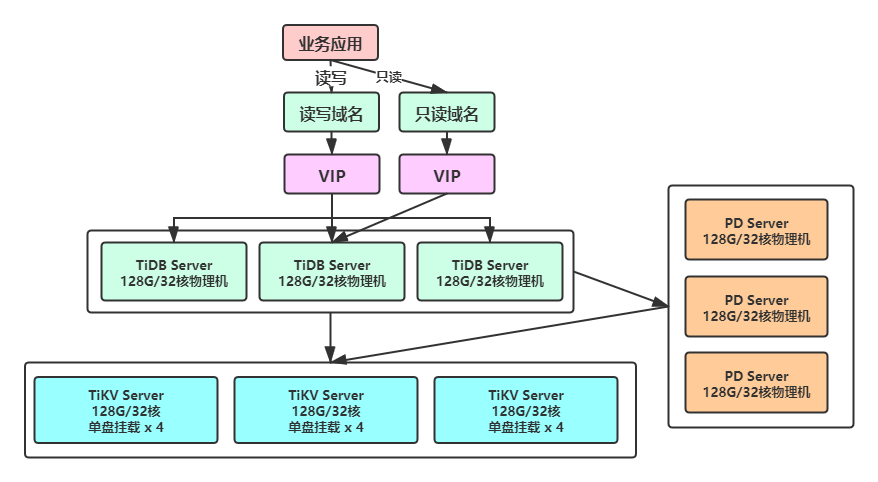
【部署机器】:
- TiDB & PD:内存型物理机
- TiKV :单盘挂载 x 4 的物理机,CPU 32核,内存128G
【集群间部署情况】:
- 多套 TiDB & PD & Prometheus & Grafana 混合部署在多个内存型机器上
- TiKV 单机部署一个集群,4个TiKV节点 分布在独立的4个单盘上
【集群使用情况】:
- 大集群思想,每套集群上建立多个库(schema)
【运维规范】:
- 制定集群的端口规范,每个间隔一定数量,减少混合部署端口问题
【问题】:
- 单个集群占用空间特别大,短时间内就超过了5T、10T,导致Region数多,心跳繁忙
- 单集群内多个库相互影响,慢SQL多
- 多个集群TiDB Server相互影响,导致某一集群慢SQL,影响多个集群的TiDB Server、PD Server等,排查问题复杂
- 单机部署过多TiKV 节点,导致内存、CPU资源不足,经常宕机,最多的时候,1个月宕机4-6台+
- 消耗内存型机器过多,资源跟不上,导致内存型机器部署实例越来越多,有点到达14个多,严重影响了性能及稳定性
- 宕机影响范围大:
- TiDB & PD 节点宕机,至少影响集群6套以上,宕机一次,DBA需要处理一下午
- TiKV 节点宕机:4个TiKV节点受影响,导致集群状态异常,且受限于2.x,3.x版本的恢复速度,直接没有流量,影响时间长;有的30分钟级别恢复不了原来的流量,只能等机器起来才能恢复。
- TiKV机器使用的是某老旧型号,磁盘及机器性能都不好,集群读写性能上不去。
【临时处理】:
- 拆分集群,重要的、量大的库单独部署
- 后期出了静默region后,所有集群都设置上
- 重要集群的TiDB Server 部署在节点少、流量少的内存型物理机上
- 关注流量、慢SQL、CPU等报警
- 及时优化慢SQL
- 部分集群尝试使用性能更好的TiKV机器,128G/40核、6x800G SSD RAID5
4、第二阶段:稳定阶段
这一阶段,属于趋于稳定阶段,有了自己的实践经验,能很好的规避一些风险及提升了稳定性。
【版本】 :3.x,4.x
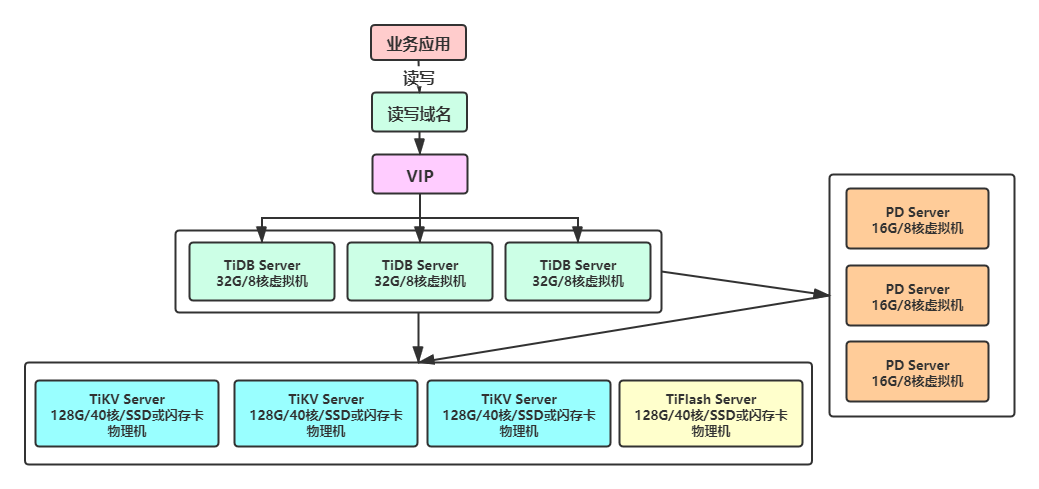
【部署机器】:
- TiDB :内存型虚拟机 32G/8核
- PD :内存型虚拟机 16G/8核
- TiKV :物理机,CPU 40核,内存128G,6x800G SSD RAID5 或 单盘闪存卡3.5T
【集群间部署情况】:
- TiDB独立部署
- PD独立部署
- Prometheus&Grafana 与TiDB 混合部署
- TiKV 单机混合部署2个集群的TiKV节点,在1个RAID5 分区上
【集群使用情况】:
- 中小型集群思想,每套集群上建立1个重要、量大的库(schema)
- 单独集群部署同一业务的多个量小、不重要的库(schema),例如日志流水等
【接入规范】 :
- 规范上对接入的业务进行量及增长情况评估,增量小的、增量不明确的暂时使用MySQL,后期量大了再迁移至TiDB
- 从MySQL接入单表大于100G的,解决MySQL问题
【版本】:
- 快速跟进官方版本迭代,快速调研测试,自动化开发,快速升级,提升性能及丰富功能
【近期工作】:
- Q4大批量替换虚拟机,独立部署,目前剩余近百节点待替换
【优势】:
- TiDB、PD节点独立部署,减少相互影响情况,稳定性提升
- TiDB、PD虚拟机部署,对磁盘要求不高,独立部署后,SQL执行时间没有明显变化,有些更好了
- 接入业务时查看情况,减少小库的不正确使用
- 虚拟机有专业的团队支持,申请简单,可以支持大量使用,稳定性比较好
- TiKV减少部署节点至2个,并配置内存相关参数,减少相互影响,减少宕机概率
- TiKV同一分区,减少集群磁盘使用不均衡问题
- 性能要求高的集群,使用闪存卡,性能至少是 RAID5 后的SSD的5倍以上,解决了性能问题,尤其是写入QPS高的。
- 部署TiFlash,减少分析型SQL对业务性能的影响
- 宕机影响范围小:
- TiDB & PD 宿主机宕机,影响范围减少,多数为1-2个TiDB虚拟机受影响
- TiKV 宕机:至多影响2个集群,每个集群1个节点,影响小,业务流量恢复快
【问题】:
- TiKV机器上混合部署2节点,还是会有相互影响的问题,待解决
- 集群存储量比较小的话,磁盘使用率比较低,限于TiKV机器节点数要求,又无法部署很多。
【临时解决】:
- 更多的从接入时的情况来限制,小库先使用MySQL,大了再迁移TiDB
- 及时跟进量小的集群,或混合部署多个不重要、量小的库(scheme)
【最终】:
- 最近1年节点宕机次数,大约在5台之内(所有节点),且均快速恢复
- 开发反馈问题减少,满意度增加
5、最终阶段:云化
这一阶段,属于目标阶段,因为虚拟机还是比较重,还是想达到业界的云化阶段,私有云建设。例如官方已经出了TiDB Operator,是 Kubernetes 上的 TiDB 集群自动运维系统,提供包括部署、升级、扩缩容、备份恢复、配置变更的 TiDB 全生命周期管理。借助 TiDB Operator,TiDB 可以无缝运行在公有云或私有部署的 Kubernetes 集群上。 这样能更好的运维TiDB,真正的解决资源隔离的需求等。
因目前的自动化、平台化都做的比较完善了,很多工作都是基于CDB平台了,且DBA人力不多,也需要Kubernetes团队配合,暂时对于快速使用Kubernetes等虚拟化要求不高,暂定计划为2021年开始做。
目前工作重点还在深度优化业务、尽快替换内存型物理机至虚拟机,保证年底高峰期的稳定运行上,同时积极学习相关知识等。
希望此文对于大家部署TiDB 有一定参考价值,减少一些弯路~