为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:TiDB-v4.0.0
- 【问题描述】: 通过dumpling导入数据之后,发现count单表为0,通过analyze table,发现一直卡住,但是日志和资源利用率都不高,请教该如何排查
执行analyze table很慢:

查看tidb slow log:

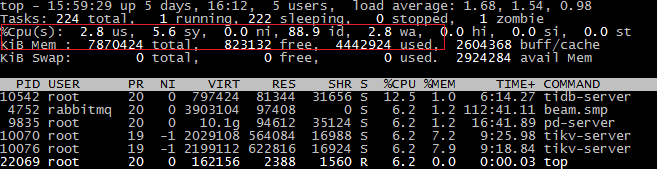
查看服务器top:
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
查看tidb slow log:
查看服务器top:
这个最好分析一下 tidb.log ,可以提供一下对应时间的对应节点 tidb 日志
看日志没问题,应该就是较慢。tidb 中 analyze 命令 与 mysql 稍微有些差别,可参考:https://docs.pingcap.com/zh/tidb/stable/sql-statement-analyze-table#analyze
我用的4核8G服务器,把所有服务都部署上了,发现每次导入数据都很慢,最后都卡在analyze table阶段。磁盘格式是xfs,不知道有影响没
下面是我配置信息:
global:
user: “root”
ssh_port: 22
deploy_dir: “/home/tidb/tidb_deploy”
data_dir: “/home/tidb/tidb_data”
monitored:
node_exporter_port: 9100
blackbox_exporter_port: 9115
server_configs:
tidb:
log.slow-threshold: 1000
tikv:
readpool.storage.use-unified-pool: false
readpool.coprocessor.use-unified-pool: true
pd:
replication.enable-placement-rules: true
replication.location-labels: [“host”]
pd_servers:
tidb_servers:
tikv_servers:
host: 192.168.1.132
port: 20160
status_port: 20180
config:
server.labels: { host: “host-1” }
host: 192.168.1.132
port: 20161
status_port: 20181
config:
server.labels: { host: “host-2” }
monitoring_servers:
grafana_servers:
其实想把内网数据库迁移到tidb,发现每次只有部分表迁移成功。并且好多表数据导入了一部分,但是使用count(1)居然为0。请问内网想学习tidb是不是必须使用ext4格式磁盘?
内网其实原本就是测试熟悉,发现数据都无法完整的导入进去。并且各种慢,又没有那么高配的服务器。
这种测试环境,感觉适合熟悉下功能。测试性能和大数据量导入还是需要环境好一些比较好。
谢谢你!
![]()
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。

