使用TiDB自带的TiSpark,与 使用外置的Spark, 通过jdbc读取TiDB数据,然后分析.这两个有区别吗?
哪个更快?
tispark 加入了对 tikv元数据信息的支持,使用 tispark 可以直接从 tikv 上读取数据
如果使用 原生 spark 不引入 tispark 插件 ,只能连接 tidb 。会有性能消耗
使用 tispark 直连 tikv 模式会更快
相关信息可以参考如下
https://docs.pingcap.com/zh/tidb/stable/tispark-overview#tispark-用户指南
好的,我再看下。
1、我不知道我理解的是否正确,是不是我独立安装的Spark,只要引入TiSpark的那几个jar包,就变成了TiSpark了,就可以直接从TiKV里面读取数据了?
2、我打算按照这篇文档来生产部署TiSpark,这样部署对吗?可以直接从TiKV读写数据吗?
3、正常我有个特殊需求,就是需要在IDEA编写SparkSQL程序,然后使用java -cp SparkSQL中的main方法来提交任务,用的是local模式。 这种情况下,似乎与服务器中Spark是否加入了TiSpark的jar包没什么关系。请问如果这种方式进行编程的话,我需要在Maven里面加入什么依赖,以引入TiSpark的jar包吗?
我看了这个视频,但这里没弄太清楚

也就是我只是代码里这样写是不是不够?
1.2 不再重复回答
3.可以参考下
https://github.com/pingcap/tispark 相关 readme 文档 会有相关内容
<dependencies>
<dependency>
<groupId>com.pingcap.tispark</groupId>
<artifactId>tispark-assembly</artifactId>
<version>2.3.9</version>
</dependency>
</dependencies>
相关代码 examples 可以参看如下链接
https://github.com/pingcap/tispark-test/tree/master/tispark-examples
在原生spark的基础上增加
- tispark的jar包
-
spark.sql.extensions org.apache.spark.sql.TiExtensionsinspark-defaults.conf. - ensure that
spark.tispark.pd.addressesis set correctly.
就可以使用tispark了
好的,谢谢
好的,谢谢,我试下
![]()
我照着官方案例做了一下,但是有一点不太明白。
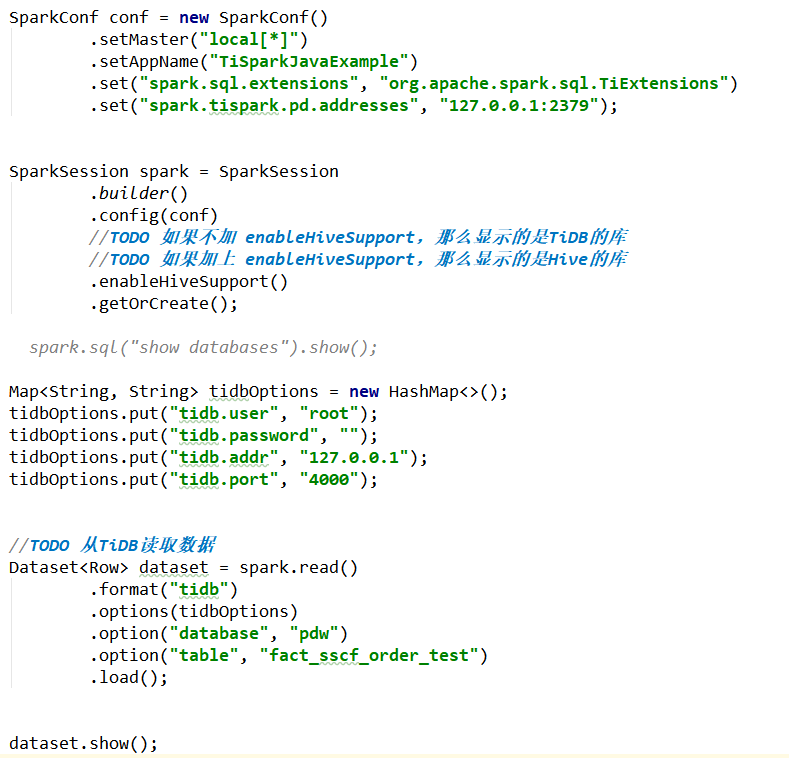
请问我通过spark.read.format(tidb)的方式,从TiDB读取数据,TiSpark是直接从TiKV读取数据,还是通过JDBC从TiDB读取数据?
如果是通过jdcb读数据,是不是比直接从TiKV读数据要慢很多?
我想从TiDB读数据,由TiSpark分析后写入Hive。不知道怎么写Hive了。加上enableHiveSupport后,读的就是Hive的库和表,不是TiDB的库和表了。
sorry 这边处理下,稍等
1 个赞
您好,从 TiSpark v2.3 开始,若想要直接从 TiKV 读取数据,只需要在 spark-defaults.conf 中加入
spark.sql.extensions org.apache.spark.sql.TiExtensions
这个配置即可直接使用 Spark SQL 进行查询了,具体行为可见 https://github.com/pingcap/tispark/blob/master/docs/userguide.md#demonstration
可使用 use $database 语法直接切换当前 catalog 至 TiDB 库,或者使用 $database.$table 来指定表名。
若存在 Hive 库与 TiDB 库重名的情况,可以参考 TiSpark从TiDB读取数据,怎么写入Hive?怎么解决Hive库与TiDB库名冲突的问题? 这里的解决思路,由于在那个回答里已经回复,所以这里不再叙述。若有其他问题,欢迎继续提出问题~
2 个赞


暂时不建议使用 format tidb 进行读操作。原因是目前 TiSpark 实现的 DataSourceAPIV2 接口主要为了写入,并没有做读优化,包括并发等。
最好直接通过 Spark SQL 接口读取,会效率更高些。
2 个赞
好的,谢谢
你好,请问是都解决了你的问题呢?
解决了,非常感谢
![]()
视频能分享一下吗?
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。